Avant-propos
Cet article est une traduction de l’article de Amit Chaudhary : A Visual Survey of Data Augmentation in NLP. Merci à lui de m’avoir autorisé à effectuer cette traduction.
J’ai ajouté des éléments supplémentaires quand j’estimais que cela était pertinent.
Introduction
Contrairement à la vision par ordinateur où l’augmentation de données d’images est une pratique courante, l’augmentation de données textuelles est moins répendue en traitement du langage naturel (NLP).
Cela s’explique par le fait que cette pratique est moins essentielle qu’en image car en NLP les données sont disponibles en abondance (les modèles de transformers étant entraînés par exemple sur les millions de pages de Wikipédia, Common Crawl, etc.). Néanmoins, pour certaines tâches il se peut que vous manquiez de données.
Voici un exemple simple que j’ai rencontré professionnellement lorsque je travaillais à l’INSERM :
dans le cadre de la conception d’un outil de classification afin de déterminer la nature des traumatismes des patients passant par le service des urgences du centre hospitalier universitaire de Bordeaux nous nous sommes aperçus que pour avoir des résultats fiables, il faut environ 500 exemples d’entraînement par classes. A cela doit s’ajouter les effectifs nécessaires pour l’échantillon test. Un tel nombre ne pose pas de problème par exemple pour les chutes à domicile (le nombre de personnes âgées admises aux urgences pour une chute est monstrueux), les accidents de la route, le sport, etc. Mais pour d’autres classes, il manque (heureusement) des effectifs comme par exemple pour les noyades, les morsures d’animaux, les tentatives de suicides, etc. Même en ayant plus de 7 années d’historique de données.
Ainsi pour obtenir des résultats probants, il nous faut augmenter artificiellement les effectifs de certaines classes.
L’objectif de cet article est de donner un aperçu des approches actuelles utilisées pour augmenter les données textuelles.
1. La substitution lexicale
Cette approche consiste à substituer des mots présents dans un texte sans pour autant changer le sens de la phrase.
1.1 Substitution basée sur un thésaurus
Dans cette technique, nous prenons un mot aléatoire de la phrase et le remplaçons par son synonyme à l’aide d’un thésaurus. Par exemple, nous pouvons utiliser la base de données WordNet pour l’anglais afin de rechercher les synonymes et effectuer ensuite le remplacement. Il s’agit d’une base de données gérée manuellement avec des relations entre les mots.
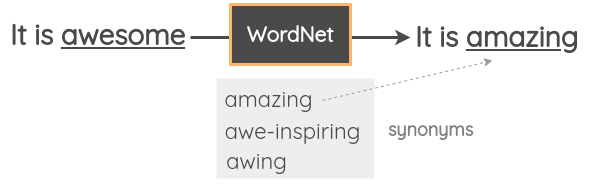
Zhang et al. ont utilisé cette technique dans leur article de 2015 intitulé Character-level Convolutional Networks for Text Classification. Mueller et al. ont utilisé une stratégie similaire pour générer 10 000 exemples d’entraînement supplémentaires pour leur modèle de similarité des phrases.
Pour le français, quatre bases sont disponibles. Elles consistent toutes en une traduction de WordNet :
- La partie en français de la base EuroWordNet qui répertorie plusieurs langues européennes. Elle est cependant limitée, n’est pas accessible librement, et commence à dater (1998)
- WOLF de Sagot Benoît et Fišer Darja, datant de 2008
- JAWS datant de 2010 qui est plus large que WOLF
- WoNef datant de 2014 qui est peut être vu comme une extension de JAWS
Il existe aussi une base de données appelée PPDB contenant des millions de paraphrases (en anglais et multilingues) que vous pouvez télécharger et utiliser.
1.2 Substitution basée sur du word embedding
Dans cette approche, nous prenons des enchâssements de mots pré-entrainés tels que Word2Vec, GloVe, FastText, Sent2Vec, et nous utilisons les mots les plus proches de celui que l’on souhaite remplacer dans l’espace des enchâssements. Jiao et al. ont utilisé cette technique avec GloVe dans leur article TinyBert pour améliorer la généralisation de leur modèle linguistique. Wang et al. l’ont utilisée pour augmenter les tweets nécessaires à l’entraînement de leur modèle.

Par exemple, vous pouvez remplacer le mot par les 3 mots les plus similaires et obtenir trois variations du texte.
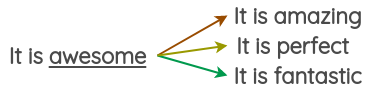
Pour l’anglais, il est facile d’utiliser des packages comme Gensim pour accéder à des vecteurs de mots pré-entraînés et obtenir les voisins les plus proches. Par exemple, nous trouvons ici les synonymes du mot awesome en utilisant des vecteurs de mots entraînés sur des tweets.
# pip install gensim
import gensim.downloader as api
model = api.load('glove-twitter-25')
model.most_similar('awesome', topn=5)
Vous aurez alors en sortie les 5 mots les plus similaires ainsi que les similitudes calculées via le cosinus.
[('amazing', 0.9687871932983398),
('best', 0.9600659608840942),
('fun', 0.9331520795822144),
('fantastic', 0.9313924312591553),
('perfect', 0.9243415594100952)]
Pour le français, plusieurs choix s’offrent à vous :
- Les différents enchâssements de mots mis à disposition par Jean-Philippe Fauconnier (exemple d’implémentation sur sa page)
- Ceux de FastText (voir le tableau en bas du lien)
1.3 Substitution basée sur un modèle de langage masqué
Des modèles de transformers tels que BERT (voir partie 2.2 de l’article du blog), ROBERTA et ALBERT (voir partie 1.1 de l’article du blog ont été entraînés sur une grande quantité de texte en utilisant la tâche de prétexte de modélisation du langage masqué où le modèle doit prédire des mots masqués en fonction du contexte.
Cette tâche peut être utilisée pour compléter certains textes. Par exemple, nous pourrions utiliser un modèle BERT pré-entraîné, masquer certaines parties du texte et demander au modèle BERT de prédire le token masqué.
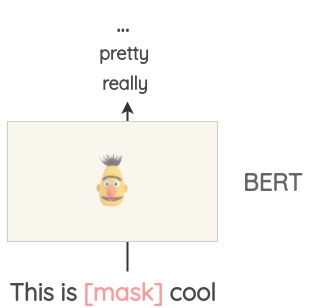
Ainsi, nous pouvons générer des variations d’un texte en utilisant les prédictions du masque. Par rapport aux approches précédentes, le texte généré est plus cohérent d’un point de vue grammatical, car le modèle tient compte du contexte lors des prédictions.
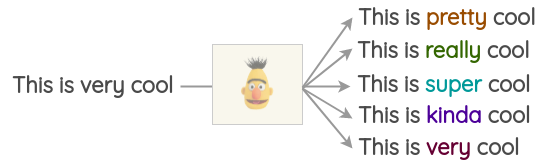
Cette approche est facile à mettre en œuvre avec la librairie open source Transformers d’Hugging Face. Vous pouvez définir le jeton que vous souhaitez remplacer par <mask> et générer des prédictions.
from transformers import pipeline
nlp = pipeline('fill-mask')
nlp('This is <mask> cool')
[{'score': 0.515411913394928,
'sequence': '<s> This is pretty cool</s>',
'token': 1256},
{'score': 0.1166248694062233,
'sequence': '<s> This is really cool</s>',
'token': 269},
{'score': 0.07387523353099823,
'sequence': '<s> This is super cool</s>',
'token': 2422},
{'score': 0.04272908344864845,
'sequence': '<s> This is kinda cool</s>',
'token': 24282},
{'score': 0.034715913236141205,
'sequence': '<s> This is very cool</s>',
'token': 182}]
De même pour le français, vous pouvez utiliser le code suivant :
camembert_fill_mask = pipeline("fill-mask", model="camembert-base", tokenizer="camembert-base")
results = camembert_fill_mask("Le camembert est <mask> :)")
A noter cependant que pour cette méthode le fait de décider quelle partie du texte est à masquer n’est pas triviale. Vous devrez utiliser l’heuristique pour décider du masque, sinon le texte généré pourrait ne pas conserver le sens de la phrase originale.
1.4 Substitution basée sur un TF-IDF
Cette méthode d’augmentation a été proposée par Xie et al. dans le document intitulé Unsupervised Data Augmentation. L’idée de base est que les mots qui ont un score TF-IDF faible ne sont pas informatifs et peuvent donc être remplacés sans affecter le label d’une phrase.

Les mots qui remplacent le mot original sont choisis en calculant les scores TF-IDF des mots sur l’ensemble du document et en prenant les plus bas. Pour l’implémentation, vous pouvez vous référer au code fournit avec la publication, disponible ici.
2. La rétrotraduction
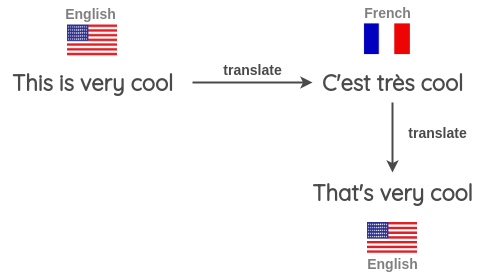
Dans cette approche, nous utilisons la traduction automatique pour paraphraser un texte tout en en retravaillant le sens. Xie et al. ont utilisé cette méthode pour augmenter leur corpus de texte non labellisé et ont entraîné un modèle semi-supervisé sur un jeu de données IMDB avec seulement 20 exemples étiquetés. Leur modèle a surpassé le précédent modèle de pointe entraîné sur 25 000 exemples étiquetés. Le processus de rétro-traduction est le suivant :
- Prendre une phrase (par exemple en anglais) et la traduire dans une autre langue, par exemple français
- Traduire la phrase en français obtenue précédemment en anglais
- Vérifier si la nouvelle phrase est différente de la phrase d’origine. Si c’est le cas, utiliser cette nouvelle phrase comme une version augmentée du texte original
Vous pouvez également effectuer une rétrotraduction en utilisant différentes langues à la fois pour générer plus de variations. Comme illustré ci-dessous, nous traduisons une phrase anglaise vers une langue cible et inversement vers l’anglais pour trois langues cibles : français, mandarin et italien.
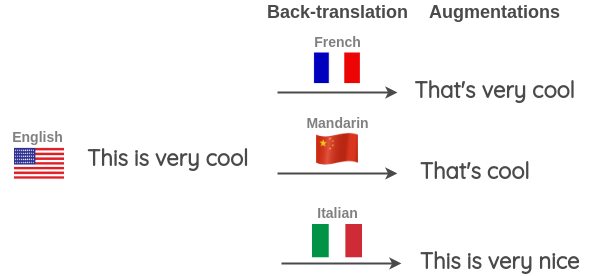
Cette technique a été utilisée par le gagnant du « Toxic Comment Classification Challenge » sur Kaggle. Il l’a utilisée pour l’augmentation des données d’entraînement ainsi que pendant le test où les probabilités prédites pour la phrase anglaise ainsi que la rétrotraduction en trois langues (français, allemand, espagnol) ont été calculées pour obtenir la prédiction finale.
Pour la mise en œuvre de la rétrotraduction, vous pouvez utiliser la librairie TextBlob et notamment la fonction Translator. Vous pouvez également utiliser Google Sheets et suivre les instructions données par Amit pour appliquer Google Translate (en anglais). Cette approche est néanmoins manuelle. Pour automatiser la chose, utilisez l’API Googletrans. Attention cependant si vous avez des données sensibles, utilisez des outils à base de Google Translate siginifie que Google les lira.
Une alternative consiste alors à utiliser un modèle de NLP entraîné à réaliser de la traduction. Vous pouvez par exemple utilisez ceux disponibles sur la libraire Hugging Face. Ils sont trouvables en utilisant le filtre «translation» : https://huggingface.co/models?filter=translation.
3. Transformation de la surface du texte
Il s’agit de transformations introduites par Claude Coulombe dans sa publication : Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs.
Dans son article, il donne un exemple de transformation de formes verbales de la contraction à l’expansion et vice versa. Nous pouvons générer des textes augmentés en appliquant cette transformation.

Comme la transformation ne doit pas changer le sens de la phrase, nous pouvons voir que cela peut échouer en cas d’expansion de formes verbales ambiguës comme :
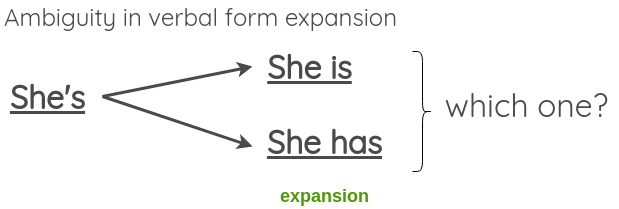
Pour résoudre ce problème, le document propose de permettre des contractions ambiguës mais de sauter les expansions ambiguës.
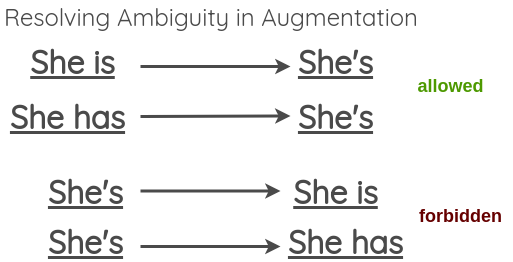
Vous pouvez trouver une liste des contractions pour la langue anglaise ici. Pour l’expansion, vous pouvez utiliser la librairie contractions en Python.
Cette technique ne semble pas avoir d’intérêt pour la langue française puisque celle-ci ne contient pas de contraction/expansion comme en anglais.
4. Injection aléatoire de bruit
L’idée de ces méthodes est d’injecter du bruit dans le texte afin que le modèle entrainé soit robuste aux perturbations.
4.1 Injection de fautes d’orthographe
Dans cette méthode, nous ajoutons des fautes d’orthographe à un mot aléatoire de la phrase. Ces fautes d’orthographe peuvent être ajoutées par programmation ou à l’aide d’un lexique des fautes d’orthographe courantes, comme cette liste pour l’anglais.

Pour le français, j’ai essayé de trouver une liste comme celle en anglais citée à l’instant, sans succès.
4.2 Injection de fautes de frappe
Cette méthode tente de simuler les erreurs courantes qui se produisent lors de la saisie sur un clavier à disposition QWERTY en raison des touches très proches les unes des autres. Les erreurs sont injectées en fonction de la distance entre les touches du clavier.
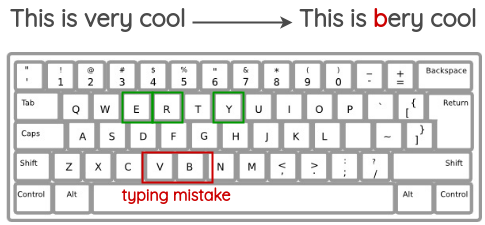
Cette approche est bien sur reproductible pour les claviers AZERTY utilisés par les francophones.
4.3 Bruits d’unigramme
Cette méthode a été utilisée par Xie et al. ou encore par Qizhe Xie et al.. L’idée est d’effectuer le remplacement en utilisant des mots échantillonnés à partir de la distribution de fréquence des unigrammes. Cette fréquence est essentiellement le nombre de fois que chaque mot apparaît dans le corpus d’entraînement.
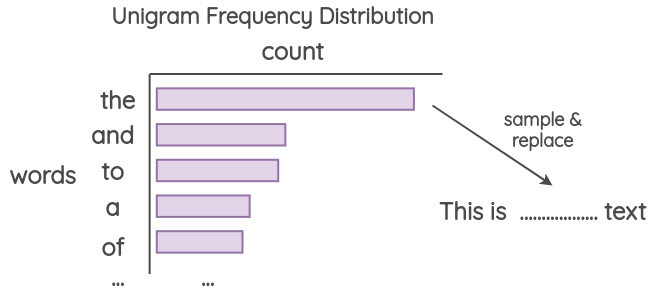
4.4 Bruits parasites
Cette méthode a été proposée par Xie et al. dans leur article. L’idée est de remplacer aléatoirement un mot par un token que l’on aura choisi préalablement. Dans l’article les auteurs utilisent « » comme caractère de remplacement. C’est un moyen d’éviter de trop s’adapter à des contextes spécifiques ainsi qu’un mécanisme de lissage du modèle linguistique. Cette technique a permis d’améliorer la perplexité et les scores BLEU.
4.5 Mélanges de phrases
Il s’agit d’une technique naïve qui consiste à mélanger des phrases présentes dans un texte de d’entraînement afin de créer une version augmentée.
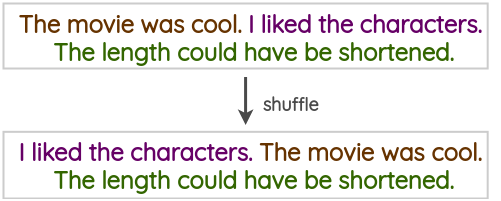
4.6 Insertion aléatoire
Cette technique a été proposée par Wei et al. dans leur article Easy Data Augmentation. Dans cette technique, nous choisissons d’abord un mot aléatoire dans la phrase qui n’est pas un mot d’arrêt. Ensuite, nous trouvons son synonyme et nous l’insérons dans une position aléatoire de la phrase.

4.7 Echange aléatoire
Cette technique a également été proposée par Wei et al. dans leur article Easy Data Augmentation. L’idée est d’échanger de manière aléatoire deux mots quelconques dans la phrase.

4.8 Suppression aléatoire
Cette technique a également été proposée par Wei et al. dans leur article Easy Data Augmentation. Dans ce cas, nous retirons aléatoirement chaque mot de la phrase avec une probabilité p.

5. Augmentation par Crossover
Cette technique a été introduite par Luque dans son article sur l’analyse des sentiments pour la TASS 2019. Elle s’inspire de l’opération de croisement des chromosomes qui se produit en génétique. Dans cette méthode, un tweet est divisé en deux moitiés et deux tweet aléatoires ayant le même label que le tweet divisé voient leurs moitiés échangées (cf. image ci-dessous). L’hypothèse est que, même si le résultat sera peu grammatical et peu solide sur le plan sémantique, le nouveau texte préservera quand même le sentiment.
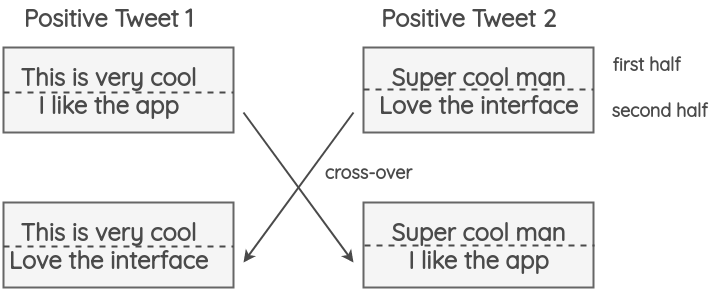
Les résultats de l’article montrent que cette technique n’a pas eu d’impact sur la précision mais a permis d’améliorer le F1-score, notamment pour les classes minoritaires (Neutral dans l’article).

6. Manipulation de l’arbre syntaxique
Cette technique a été utilisée dans le papier de Coulombe. L’idée est d’analyser et de générer l’arbre des dépendances de la phrase originale, de le transformer à l’aide de règles et de générer une phrase paraphrasée.
Par exemple, une transformation qui ne change pas le sens de la phrase est la transformation de la voix active à la voix passive de la phrase et vice versa.
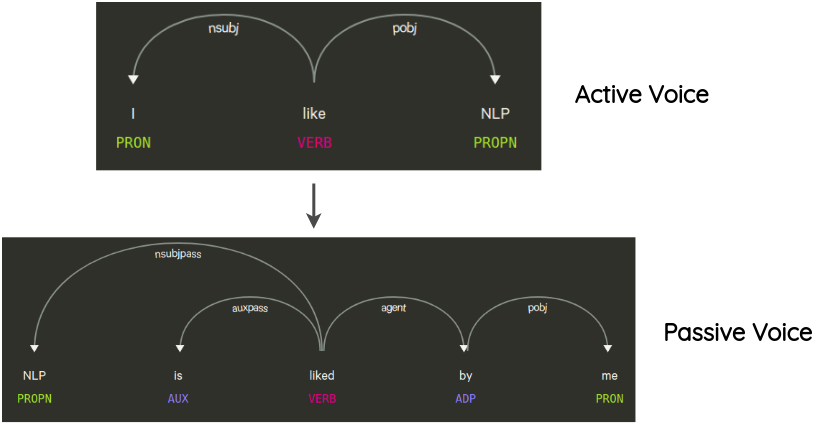
Dans la même logique on peut passer de singulier au pluriel une phrase et inversement, ou bien encore du masculin au féminin et inversement.
7. Le mélange de texte (MixUp)
Le MixUp est une technique simple mais efficace d’augmentation d’images introduite par Zhang et al. en 2017. L’idée est de combiner deux images aléatoires dans une certaine proportion dans un mini-batch afin de générer des exemples synthétiques pour l’entraînement. Pour les images, cela signifie combiner des pixels d’image de deux classes différentes. Cela agit comme une forme de régularisation pendant l’entraînement.

Guo et al. ont appliqué cette idée au NLP pour travailler avec du texte. Ils proposent deux nouvelles approches pour appliquer Mixup au texte :
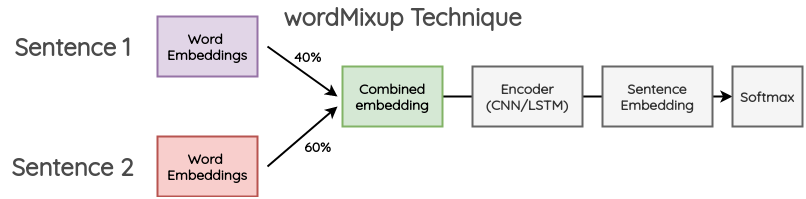
7.1 WordMixUp
Dans cette méthode, deux phrases d’un mini-batch sont prises aléatoirement et dimensionnées à la même longueur. Ensuite, les mots qui les composent sont combinés dans une certaine proportion. L’enchâssement de mots qui en résulte est transmis au flux habituel pour la classification du texte. L’entropie croisée est calculée pour les deux labels du texte original dans la proportion donnée.
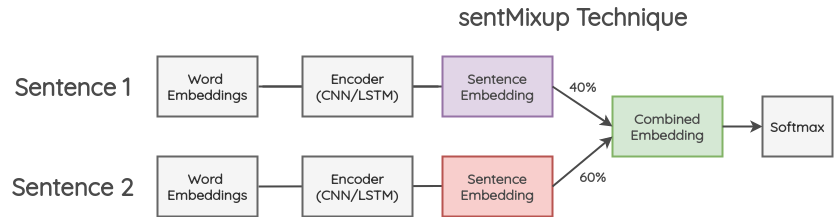
7.2 SentMixup
Dans cette méthode, on prend deux phrases et on les met à la même longueur. Ensuite, leurs enchâssements de mots sont passés dans un encoder LSTM/ConvNet et nous prenons le dernier état caché comme enchâssement de la phrase. Ces enchâssements sont combinés dans une certaine proportion et sont ensuite transmis à la couche de classification finale. La perte d’entropie croisée est calculée sur la base des deux labels des phrases originales dans la proportion donnée.
8. Méthodes génératives
Kumar et al proposent dans leur article d’utiliser des transformers pré-entrainés afin d’augmenter les données d’entraînement. La formulation du problème est la suivante :
- Ajouter le label de la classe à chaque texte de vos données d’entraînement
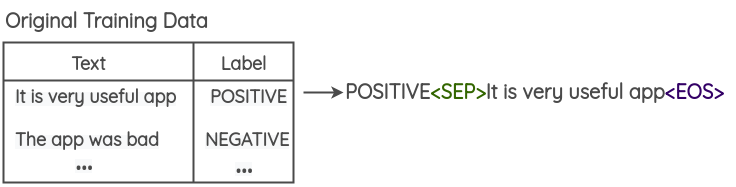
- Finetuner un grand modèle de langue pré-entraîné (BERT/GPT2/BART) sur ces données d’entraînement modifiées. Pour le GPT2, la tâche est la génération tandis que pour BERT, l’objectif est la prédiction du jeton masqué.

- En utilisant le modèle de langage finetuné, de nouveaux échantillons peuvent être générés en utilisant le label de la classe et quelques mots initiaux comme « prompt ».

Pour le français, cette méthode est difficilement applicable, c’est pourquoi je ne vous la recommande pas.
En français, il existe deux GPT2 entraînés avec un vocabulaire en français sur des données en français existant pour le moment : le BelGPT-2 d’Antoine Louis et PAGnol de Launay et al..
Pour le BelGPT2, quand on génère une phrase avec le modèle, celle-ci est la plupart du temps correcte. Cependant un problème apparait quand on génère plusieurs phrases : celles-ci sont individuellement correctes mais le tout devient incorrect d’un point de vue de la logique quand elles se succèdent. Le contexte passe du coq à l’âne.
Lors de quelques expérimentations, j’ai aussi pu constater que des phrases dans d’autres langues que le français étaient générées (anglais et wolof entre autres). Vous pouvez expérimenter par vous-même via l’API d’HuggingFace. Je n’ai pas eu l’occasion de faire d’expérimentations avec PAGnol. Vous pouvez le tester par vous-même via le démonstrateur en ligne proposé par les auteurs du modèle.
Ainsi, je déconseille d’utiliser cette technique en l’état actuel. D’autres sont plus simples, plus rapides à mettre en place car ne nécessite pas de finetuning, sont moins lourdes (PAGnol faisant 1,5 milliard de paramètres par exemple), et donne de meilleurs résultats.
9. La simplification de textes
J’ajoute une méthode supplémentaire qu’Amit n’a pas cité dans son article : les modèles permettant la simplification de texte. Ils permettent de conserver le sens de la phrase mais avec une syntaxe différente et souvent plus courte. Deux approches sont envisageables. La première où le texte original est paraphrasé. La deuxième consiste à faire un résumé du texte original.
9.1 Les paraphrases
Pour la langue anglaise, le jeu de données ASSET de Fernando Alva-Manchego, Louis Martin et al. est disponible depuis mai 2020. Il permet de finetuner les modèles de simplification de texte.

Pour la langue française, il existe le jeu de données ALECTOR de Gala et al. extraits de sites proposant du matériel pédagogique pour les niveaux CE1, CE2 et CM1 de l’école primaire. Chaque texte original a été adapté (simplifié) au niveau du lexique (vocabulaire), de la morpho-syntaxe (catégories grammaticales, structures de phrase) et du discours (co-référence).
Ou bien encore les données en français du jeu de données PPDB déjà cité dans la partie 1.1 de cet article.
Vous pouvez consulter également les travaux de Martin et al., portant sur un outil permettant une simplification de phrases multilingues.
9.2 Le résumé
Dans cette approche, nous avons le texte original en entrée et un résumé de ce texte en sortie. Cette approche est bien développée en anglais avec des jeux de données disponibles pour le finetuning (XSum de Narayan et al., CNN/DM de Hermann et al.) et des modèles déjà entraînés à cette tâche (le T5 de Raffel et al., BART de Lewis et al., etc.) Pour l’implémentation, vous pouvez utiliser le code suivant reposant sur la fonction pipeline de la librairie Hugging Face :
summarizer = pipeline("summarization") # utilise BART par défaut
summarizer("Sam Shleifer writes the best docstring examples in the whole world.", min_length=5, max_length=20)
Ce qui donne :
Sam Shleifer writes the best docstring examples in the world
Pour le français, vous pouvez utiliser la partie en français de la base de données multilingues MLSUM de Scialom et al. pour entraîner votre propre modèle ou bien la base OrangeSum de Eddine et al. qui a été introduite avec leur modèle BARThez. Pour l’implémentation, vous pouvez utiliser le même code que pour l’anglais en changeant seulement le modèle et en donnant en entrée une phrase en français :
summarizer = pipeline("summarization", model="moussaKam/barthez-orangesum-abstract", tokenizer="moussaKam/barthez",)
summarizer("Votre texte")
Implémentation
Les librairies Python comme nlpaug et textattack fournissent une API simple afin d’appliquer les méthodes ci-dessus pouvant ainsi être facilement intégrées dans un pipeline.
Conclusion
Dans la plupart des papiers liés à l’augmentation de données textuelles, les auteurs se limitent à présenter leur méthode : aucune comparaison n’est réalisée avec d’autres méthodes existantes.
Ce travail de comparaison est réalisé par Columbe dans sa thèse (2020). Celle-ci a été rédigée en français (application à des textes en anglais). Elle décrit bien les méthodes 1 à 7 de cet article, permettant de connaître les atouts et les limites de chacune d’elles.
Si vous avez du temps et êtes intéressés par ce sujet, je vous invite fortement à la lire (environ 200 pages).
Références
- ASSET: A Dataset for Tuning and Evaluation of Sentence SimplificationModels with Multiple Rewriting Transformations de Fernando Alva-Manchego, Louis Martin et al. (2020)
- Alector: A Parallel Corpus of Simplified French Texts with Alignments of Misreadings by Poor and Dyslexic Readers de Gala et al. (2020)
- Multilingual Unsupervised Sentence Simplification de Louis Martin et al. (2020)
- A Visual Survey of Data Augmentation in NLP de Amit Chaudhary (2020)
- Techniques d’amplification des données textuelles pour l’apprentissage profond de Claude Coulombe (2020)
- Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs de Coulombe (2018)
- French Word Embeddings de Fauconnier (2015)
- The Multilingual Paraphrase Database de Ganitkevitch et Callison-Burch (2014)
- Augmenting Data with Mixup for Sentence Classification: An Empirical Study de Guo et al. (2019)
- TinyBERT: Distilling BERT for Natural Language Understanding de Jiao et al. (2019)
- Data Augmentation using Pre-trained Transformer Models de Kumar et al. (2020)
- Atalaya at TASS 2019: Data Augmentation and Robust Embeddings for Sentiment Analysis de Luque (2019)
- WordNet: A Lexical Database for English de Miller (1995)
- JAWS : Just Another WordNet Subset de Mouton et Chalendar (2010)
- Global Monopole in Palatini f(R) gravity de Nascimento et al. (2018)
- WoNeF de Pradet et Baguenier-Desormeaux (2012)
- Construction d’un wordnet libre du français à partir de ressources multilingues de Sagot et Fiser (2008)
- EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks de Wei et Zou (2019)
- Data Noising as Smoothing in Neural Network Language Models de Xie et al. (2017)
- Unsupervised Data Augmentation for Consistency Training de Xie et al. (2019)
- That’s So Annoying!!!: A Lexical and Frame-SemanticEmbedding Based Data Augmentation Approach to AutomaticCategorization of Annoying Behaviors using#petpeeveTweets de Yang Wang et Yang (2015)
- mixup: Beyond Empirical Risk Minimization de Zhang et al (2017)
- Character-level Convolutional Networks for Text Classification de Zhang et al. (2015)
- Don’t Give Me the Details, Just the Summary!Topic-Aware Convolutional Neural Networks for Extreme Summarization de Narayan et al. (2018)
- Teaching Machines to Read and Comprehend de Hermann et al. (2015)
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension de Lewis et al. (2019)
- Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer de Raffel et al. (2020)
- MLSUM: The Multilingual Summarization Corpus de Scialom et al. (2020)
- BARThez: a Skilled Pretrained French Sequence-to-Sequence Model de Eddine et al. (2020)
Citation
@inproceedings{nlp_data_augmentation_blog_post,
author = {Loïck BOURDOIS},
title = {L'augmentation de données en NLP},
year = {2020},
url = {https://lbourdois.github.io/blog/nlp/Data-augmentation-in-NLP/}
}