Avant-propos
Les techniques évoquées dans cet article apparaissent maintenant comme anciennes par rapport aux diverses architectures basées sur le transformer qui sont très populaires depuis fin 2017/ début 2018. Ainsi beaucoup de documentation est déjà disponible en français à leur sujet.
Je ne compte donc pas faire un article extrêmement détaillé qui ferait doublon par rapport à ce qui existe a déjà été fait.
Je me contente d’énoncer les grandes idées et vous renvoie vers d’autres articles / vidéos pour plus de détails (formules mathématiques, exemples d’applications, etc.).
Les RNN, les LSTM et les GRU
Les RNNs (recurrent neural network ou réseaux de neurones récurrents en français) sont des réseaux de neurones qui ont jusqu’à encore 2017/2018, été majoritairement utilisé dans le cadre de problème de traitement du langage naturel.
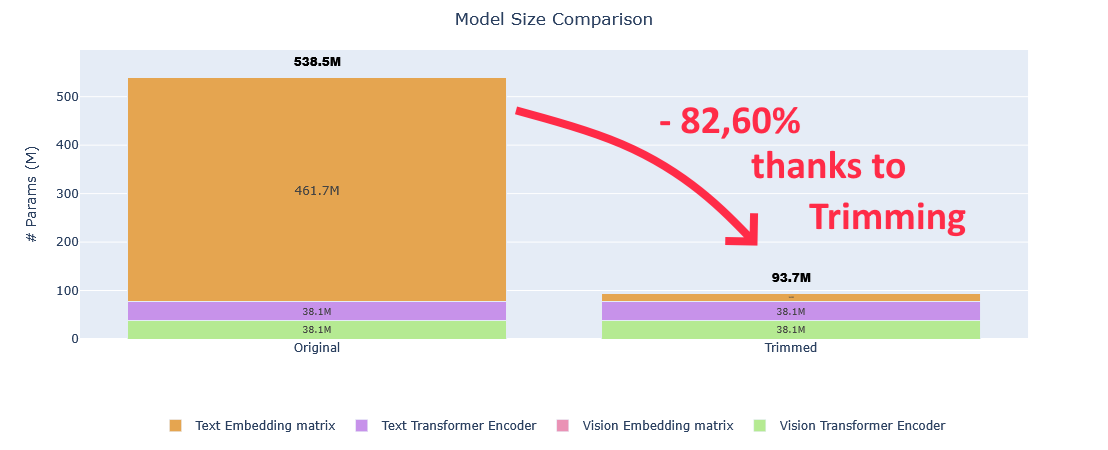
U, V et W sont trois matrices de poids (avec notamment V la matrice des poids récurrents). Ces trois matrices sont les mêmes pour chaque étape t. Les valeurs de ces matrices sont apprises lors de la phase d’entraînement du réseau.
Cette architecture possède un problème.
Lorsque la séquence à traiter est trop longue, la rétropropagation du gradient de l’erreur peut soit devenir beaucoup trop grande et exploser, soit au contraire devenir beaucoup trop petite.
Le réseau ne fait alors plus la différence entre une information qu’il doit prendre en compte ou non.
Il se trouve ainsi dans l’incapacité d’apprendre à long terme.
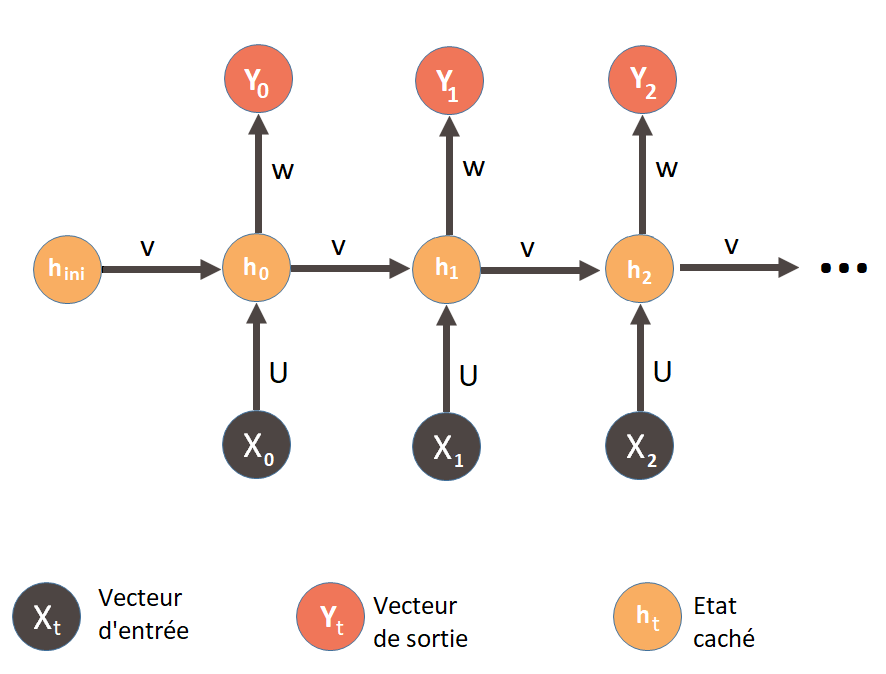
Les LSTMs (Long Short-Term Memory) de Hochreiter et Schmidhuber proposent une solution à ce problème en prenant en compte un vecteur mémoire via un système de portes (gates) et d’états. Les portes sont au nombre de 3 et les états au nombre de 2 :
- Forget Gate (capacité à oublier de l’information, quand celle-ci est inutile)
- Input Gate (capacité à prendre en compte de nouvelles informations utiles)
- Output Gate (quel est l’état de la cellule à l’instant t sachant la forget gate et la input gate)
- Hidden state (état caché)
- Cell state (état de la cellule)
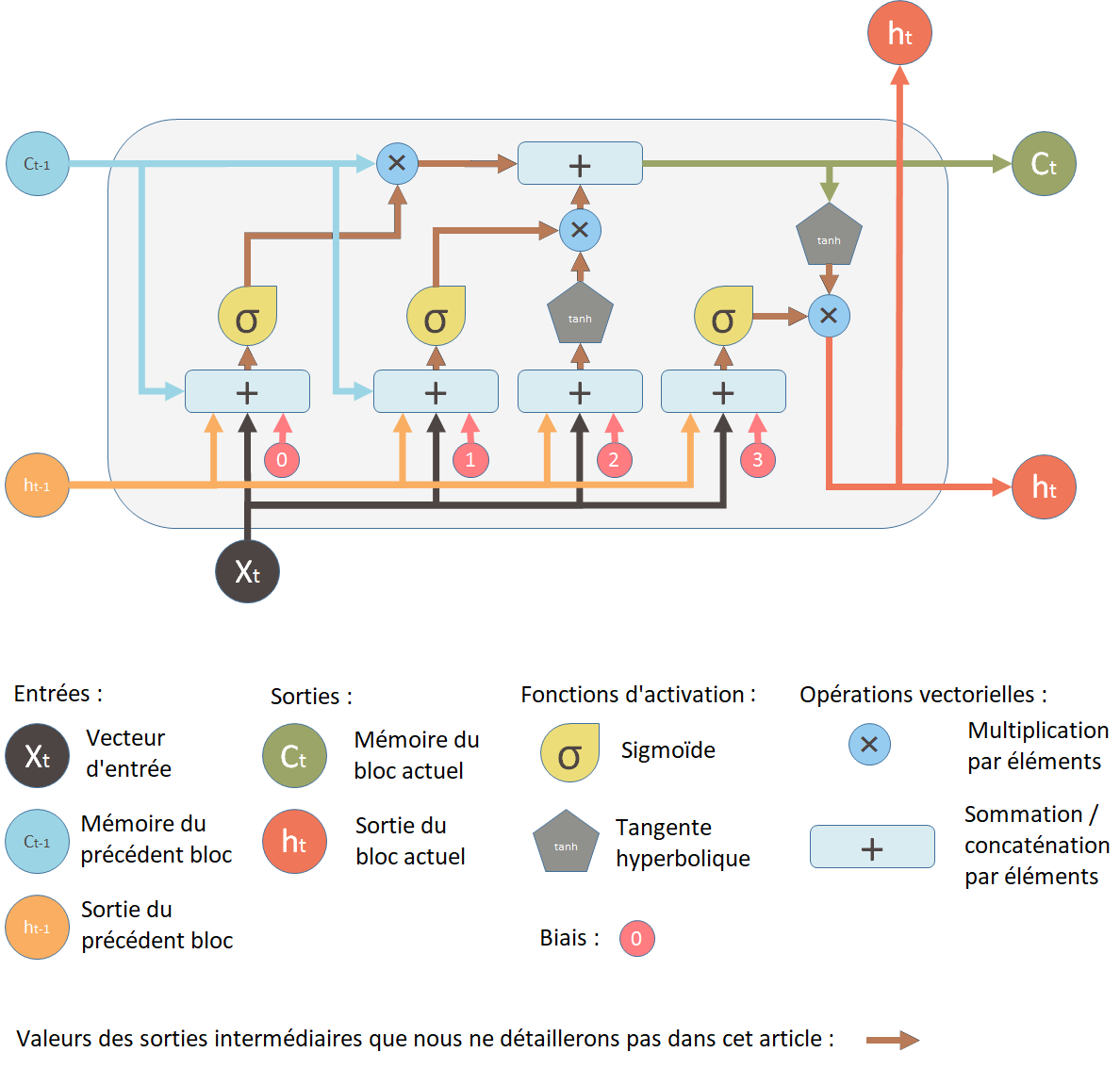
Une variante des LSTMs sont les GRUs (Gated Recurrent Unit) développées par Cho et al. Cette structure est plus simple que les LSTMs au sens où moins de paramètres entrent en jeu. Le nombre de portes passe à 2 et celui d’état à 1 :
- Reset gate (porte de réinitialisation)
- Update gate (porte de mise à jour)
- Cell state (état de la cellule)
En pratique, les GRUs et les LSTMs permettent d’obtenir des résultats comparables. L’intérêt des GRUs par rapport aux LSTMs étant le temps d’exécution qui est plus rapide puisque moins de paramètres doivent être calculés.
Pour plus de détails, je vous invite à lire ou visionner selon votre choix les sources suivantes :
- l’article Medium de Charles Crouspeyre qui est une traduction de la vidéo de Brandon Rohrer (ex-senior Datascientist chez Facebook). Il est illustré d’exemples mais n’évoque pas les mathématiques sous-jacentes.
- l’article Medium de Youcef Messaoud qui explique les LSTMs avec des illustrations.
- les deux vidéos de Thibault Neveu : celle sur les RNNs et celle sur les LSTMs.
- la page Wikipédia consacré au sujet (explication courte avec les formules mathématiques).
Une vidéo réalisée par un doctorant dans le domaine qui récapitule l’ensemble de l’article (principes généraux mais aussi mathématiques) est disponible un peu plus loin dans la conclusion.
ELMo (l’importance du contexte)
Pour apporter un peu de valeur ajoutée par rapport aux articles cités dans la partie précédente, j’évoque dans celle-ci le modèle ELMo (Embeddings from Language Models) qui est basé sur une LSTM bidirectionnelle.
Pour cette partie, je me base sur un article du blog de Jay Alammar : The illustrated BERT, ELMo, and co. (How NLP cracked transfer learning).
Entrons dans le vif du sujet.
Si par exemple nous utilisons la représentation GloVe du mot « stick », alors ce mot est représenté par un unique vecteur, peu importe le contexte.
« Attendez une minute ! » disent plusieurs chercheurs (Peters et. al., 2017, McCann et. al., 2017, et encore une fois Peters et. al., 2018 dans le papier d’ELMo), « stick » a plusieurs sens selon la manière dont où il est utilisé (cf. toutes les définitions de traduction proposées par le Larousse). Pourquoi ne pas lui donner un enchâssement basé sur le contexte dans lequel il est utilisé ? A la fois pour capturer le sens du mot dans ce contexte ainsi que d’autres informations contextuelles. C’est ainsi qu’ont vu le jour les contextualized word-embeddings (enchâssement de mot contextualisés).
Au lieu d’utiliser un enchâssement fixe pour chaque mot, ELMo examine l’ensemble de la phrase avant d’assigner un enchâssement à chaque mot qu’elle contient. Il utilise une LSTM bidirectionnelle entraînée sur une tâche spécifique pour pouvoir créer ces enchâssements.
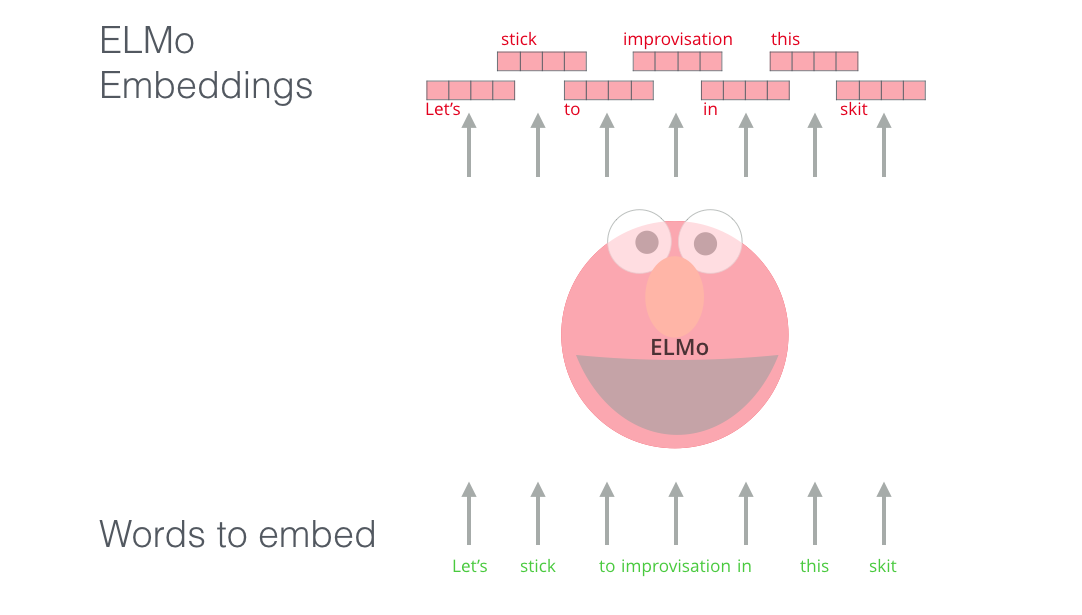
ELMo a constitué un pas important vers le pré-entraînement dans le contexte du NLP. En effet, nous pouvons l’entraîner sur un ensemble massif de données dans la langue de notre choix, et ensuite nous pouvons l’utiliser comme un composant dans d’autres modèles qui ont besoin de traiter le langage.
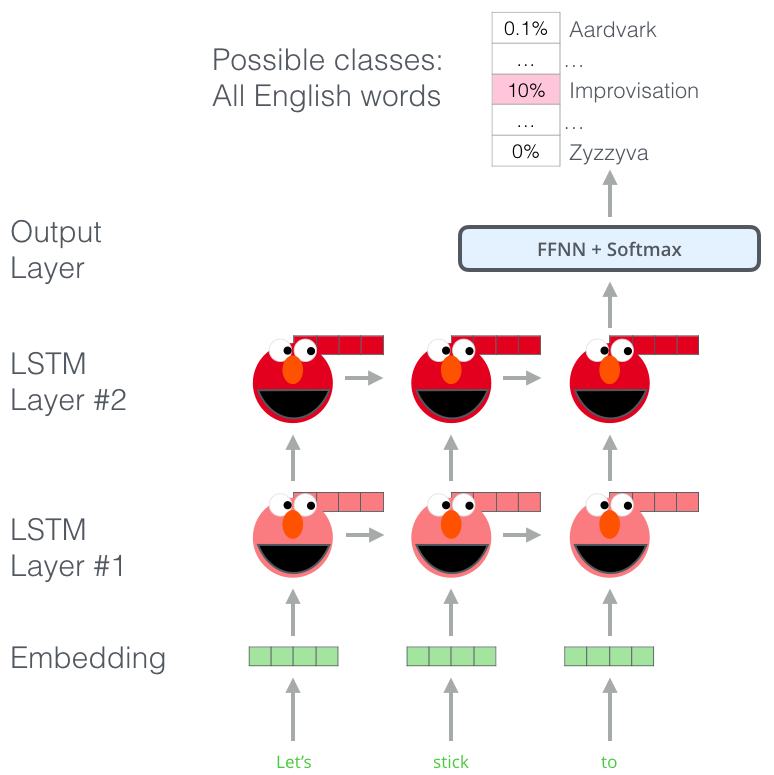
Plus précisément, ELMo est entraîné à prédire le mot suivant dans une séquence de mots, une tâche appelée modélisation du langage (language modeling). C’est pratique car nous disposons d’une grande quantité de données textuelles dont un tel modèle peut s’inspirer sans avoir besoin de labellisation.
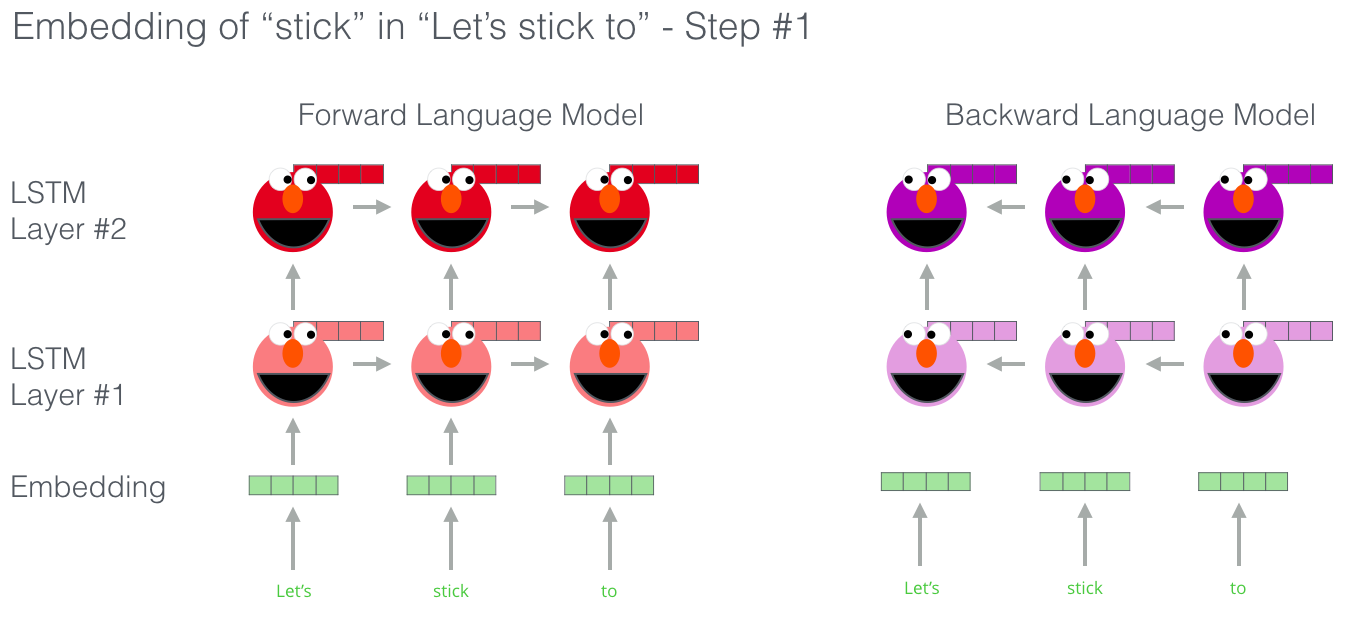
ELMo va même plus loin avec sa LSTM bidirectionnelle puisque son modèle de langage n’a pas seulement le sens du mot suivant, mais aussi du mot précédent.
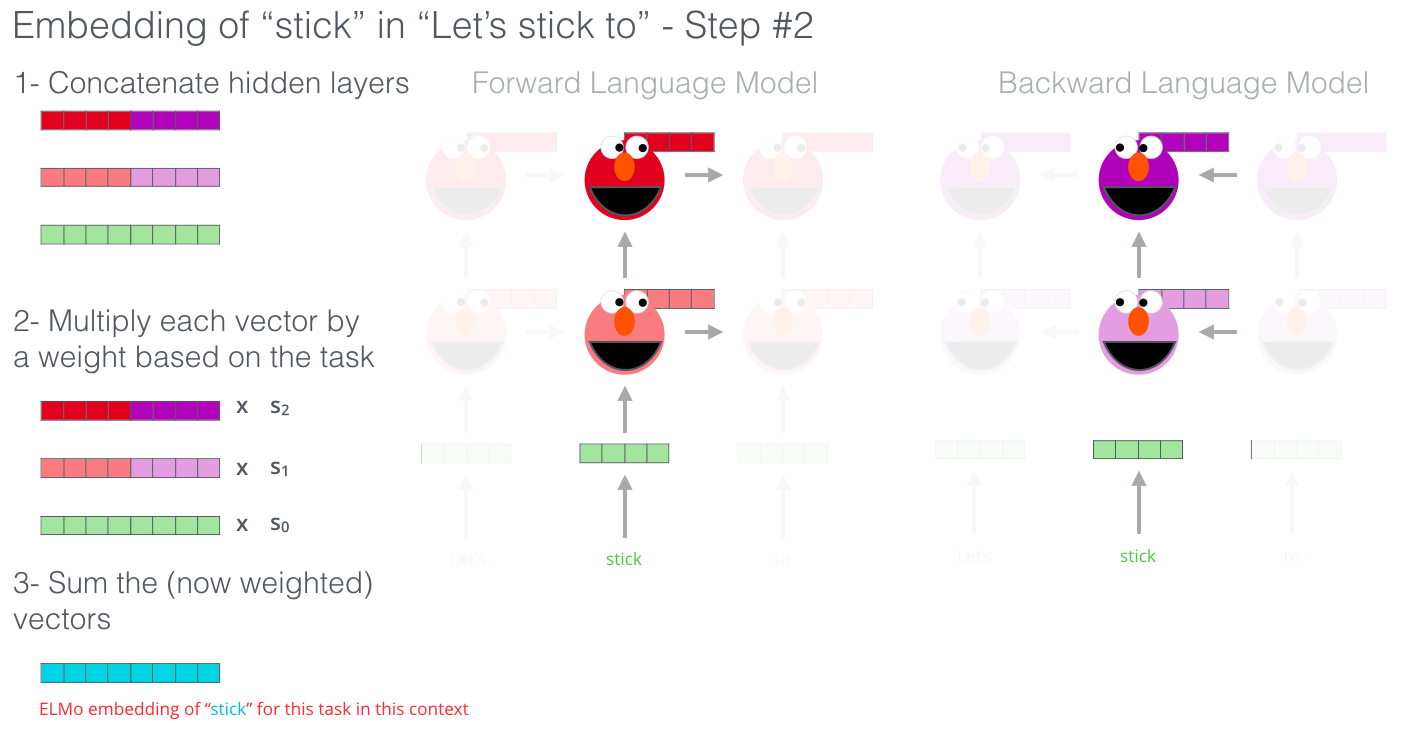
ELMo propose l’enchâssement contextualisé en regroupant les états cachés (et l’enchâssement initial) d’une certaine manière (concaténation suivie d’une sommation pondérée).
En mai 2020, Ortiz Suárez et al. ont dévoilé six ELMo différents entraînés respectivement sur du français, du bulgare, du catalan, du danois, du finnois et de l’indonésien. Ces modèles sont disponibles à la page suivante dans la partie « Models ».
Conclusion
Si vous préférez regarder des vidéos plutôt que de lire, je vous conseille très fortement de regarder celle effectué par César Laurent.
Il résume en un peu plus d’une heure tout ce qu’il faut savoir sur le sujet.
César Laurent étant doctorant au MILA sous la co-direction de Pascal Vincent et Yoshua Bengio : https://www.youtube.com/watch?v=dOpgDv88UOo
Enfin, même si ces techniques ne sont plus à la mode dans la communauté NLP depuis 2017/2018 du fait de l’apparition des différentes architectures liées au transformer, il ne faut pas les enterrer. En effet, la recherche avance très vite. Par exemple en 2020, Katharopoulos et al. ont montré dans leur papier Transformers are RNNs : Fast Autoregressive Transformers with Linear Attention que les transformers pouvaient être considérés comme des RNNs.
Références
- Long Short-term Memory de Hochreiter et Schmidhuber (1997)
- Learning Phrase Representations using RNN Encoder–Decoderfor Statistical Machine Translation de Cho et al. (2014)
- Transformers are RNNs:Fast Autoregressive Transformers with Linear Attention de Katharopoulos et al. (2020)
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) de Jay Alammar (2018)
- Comment les Réseaux de neurones récurrents et Long Short-Term Memory fonctionnent de Charles Crouspeyre (2017)
- EH2018-10 - Modèle : Réseaux récurrents (Partie 1) de César Laurent (2018)
- Learned in Translation: Contextualized Word Vectors de McCann et al. (2017)
- Single Headed Attention RNN: Stop Thinking With Your Head de Stephen Merity (2019)
- LSTM, Intelligence artificielle sur des données chronologiques de Youcef Messaoud (2018)
- Comprendre les LSTM - Réseaux de neurones récurrents de Thibault Neveu (2019)
- Comprendre les réseaux de neurones récurrents (RNN) de Thibault Neveu (2019)
- A Monolingual Approach to Contextualized Word Embeddingsfor Mid-Resource Languages de Ortiz Suárez et al. (2020)
- Deep contextualized word representations de Peters et al. (2018)
- Semi-supervised sequence tagging with bidirectional language models de Peters et al. (2017)
- Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) de Brandon Rohrer (2017)
- Understanding LSTM and its diagrams de Shi Yan (2016)
Citation
@inproceedings{rnn_blog_post,
author = {Loïck BOURDOIS},
title = {Les RNN, les LSTM, les GRU et ELMO},
year = {2019},
url = {https://lbourdois.github.io/blog/nlp/RNN-LSTM-GRU-ELMO/}
}