Avant-propos
Cet article est une traduction de l’article de Keita Kurita : A Deep Dive into the Wonderful World of Preprocessing in NLP (le site de Keita Kurita n’existant plus, le lien renvoie vers une version capturée par Wayback Machine).
Merci à lui de m’avoir autorisé à effectuer cette traduction.
Introduction
Le prétraitement est peut-être l’un des éléments les plus sous-évalués et les plus négligés en traitement du langage naturel actuellement.
En effet, si par exemple vous utilisez des tranformers pré-entrainés, le travail a déjà été effectué pour nous. Les publications scientifiques n’entrent d’ailleurs que très rarement dans le détail au moment d’aborder cette étape et se focalisent davantage sur le modèle développé et les résultats obtenus avec.
Malgré qu’il puisse paraître trivial, le prétraitement est subtil et extrêmement important pour obtenir de bonnes performances et prévenir les bugs (cf. cette publication de Matt Post).
Dans cet article, nous nous focaliserons donc sur le prétraitement en passent en revue les principales techniques de tokenization comme le byte-pair encoding (BPE), le wordpiece et le sentencepiece, ainsi que les choses auxquelles il faut faire attention.
Vue d’ensemble
Les modèles d’apprentissage machine nécessitent des entrées sous la forme de nombre pour pouvoir fonctionner. Le prétraitement est essentiellement le processus qui consiste à prendre un morceau de texte brut et à le convertir en nombres. Par conséquent, pour la plupart des applications, le prétraitement peut être divisé en trois étapes :
- Étape 1 : Normalisation (nettoyage)
C’est là que nous nettoyons les données pour éliminer les entrées non désirées et pour convertir certains caractères/séquences en formes canoniques. - Etape 2 : Segmentation (tokenization)
C’est là que nous divisons le flux continu de caractères en entités. C’est probablement l’étape la plus complexe du processus et est un point majeur de l’article. - Étape 3 : Numérisation
C’est là que nous convertissons les entités textuelles en nombres/id pour pouvoir les donner à notre modèle. Bien que simple, cette étape peut introduire quelques problèmes désagréables dont nous parlerons plus tard.
Notez que ces étapes ne sont pas toujours clairement divisées. Par exemple, certains tokenizers contiennent des étapes de normalisation et la segmentation est souvent étroitement couplée à la numérisation. Néanmoins, penser à ces étapes séparément rend les choses beaucoup plus faciles à comprendre et à expliquer, c’est pourquoi je m’en tiendrai à cette division légèrement arbitraire pour la suite.
1. Étape 1 : Normalisation (nettoyage)
Dans le contexte du prétraitement en traitement du langage naturel, la normalisation se réfère au processus de nettoyage de l’entrée et de mise en correspondance des caractères/mots avec une forme canonique.
Un exemple très simple de normalisation est de mettre tous les caractères en minuscule. Cela permet d’éviter que des mots comme « Bonjour » et « bonjour » soient traités différemment. La similarité entre ces mots est claire pour un humain, mais lorsqu’ils sont simplement mis en correspondance avec un seul entier, le modèle en aval n’a aucun moyen de comprendre qu’il s’agit du même mot sous-jacent. La normalisation permet d’éviter cette divergence.
Voici quelques autres étapes de normalisation que vous pourriez vouloir utiliser :
- Gérer les caractères répétitifs (par exemple « cooooool » → « cool »)
- Manipulation des homoglyphes (par exemple « $tupide » → « stupide »)
- Transformation des entrées spéciales telles que les URL, les adresses e-mail et les balises HTML à une forme canonique (par exemple « https://lbourdois.github.io/blog/nlp/Les-tokenizers/ » → « [URL] »)
- Normalisation unicode Certains lecteurs n’ont peut-être jamais entendu parler de la normalisation unicode avant, faisons donc en un rapide aperçu. En unicode, certains caractères qui sont effectivement les mêmes peuvent être représentés de plusieurs façons. Par exemple, le caractère « ë » peut être représenté comme un seul caractère unicode (« ë » ou deux caractères unicode (le caractère « e » et un accent). La normalisation unicode fait correspondre ces deux caractères à une forme unique et canonique. Pour plus de détails vous pouvez lire ce post (en anglais).
Vient maintenant la question importante : quels types de normalisation devrions-nous réellement appliquer ? Bien sûr, il n’y a pas de réponse claire à cette question, mais voici quelques lignes directrices et facteurs à prendre en considération :
- Quelle quantité d’informations cruciales la normalisation supprime-t-elle ? Par exemple, dans les médias sociaux, dire « HELLO » et « Hello » peut avoir des nuances différentes. En même temps, traiter différemment « Hello world » et « hello world » peut ne pas avoir beaucoup de sens. La majuscule peut indiquer une information grammaticale importante, comme le fait qu’un mot est un nom propre (par exemple, « New York »).
- De combien de données disposez-vous ? Si vous avez beaucoup de données, vous aurez probablement besoin de moins de normalisation puisque le modèle pourrait simplement apprendre que « Hello » et « hello » sont le même mot sous-jacent à partir de leurs distributions. Si vous n’avez pas beaucoup de données alors pourriez vouloir une plus grande normalisation.
- Une grande taille de vocabulaire est-elle préjudiciable à votre application ? Moins de normalisation tend à conduire à un vocabulaire plus important, bien que cela dépende du type de tokenisation que vous utilisez. Si vous entraînez un modèle génératif, la couche de softmax de sortie peut être un goulot d’étranglement majeur. Une taille de vocabulaire plus importante peut ralentir l’entraînement de manière significative. Cela peut aussi causer des problèmes de mémoire, pouvant nécessiter des tailles de batch plus petites, ralentissant encore plus l’entraînement.
2. Étape 2 : Segmentation (tokenization)
La segmentation/tokénisation est probablement la partie la plus complexe du pipeline de prétraitement. Nous allons donc en discuter en profondeur. Nous allons d’abord passer en revue quelques algorithmes naïfs de tokenisation, puis discuter des tokenizers à base de règles, et enfin passer en revue des tokenizers de sous-mots plus modernes qui sont appris sur des données.
2.1 Tokeniser sur les espaces / la ponctuation
La forme la plus naïve de tokenisation (qui est utilisée étonnamment souvent puisque certaines applications utilisent simplement la fonction string.split en Python) est le fractionnement sur les espaces. Prenons la phrase suivante comme exemple :
“I saw a girl with a telescope.”
Elle est divisée en :
“I”, “saw”, “a”, “girl”, “with”, “a”, “telescope.”
Remarquez que le point est annexé au dernier mot. Nous ne voulons probablement pas cela, puisque le mot « télescope » a la même signification qu’il soit avec un point ou non. Cette approche est donc fortement déconseillée !
Une approche légèrement meilleure et qui fonctionne dans bien des cas consiste à utiliser des jetons basés sur la ponctuation comme :
“I”, “saw”, “a”, “girl”, “with”, “a”, “telescope”, “.”
Cependant, cette approche présente encore de nombreux problèmes. Que faites-vous, par exemple, avec les points de suspension ? Voulez-vous une division en trois points (".", ".", ".") ou préférez-vous un seul jeton ? Et pour les émoticônes comme :) et des abréviations comme U.S.A. ? Il est clair que le simple fait d’utiliser des signes de ponctuation et des espaces blancs est insuffisant si nous voulons obtenir la meilleure performance, ce qui nous motive à poursuivre des méthodes de tokenisation plus complexes, basées sur des règles.
2.2 Tokenization basée sur des règles
Les tokenizers à base de règles nous permettent de tokeniser plus intelligemment au cas par cas. Ici, couvrons deux principaux tokenizers basés sur des règles : le tokenizer Spacy et le tokenizer Moses.
2.2.1 Spacy
Le tokenizer Spacy est un tokenizer moderne qui est largement utilisé pour une bonne raison : il est rapide, fournit des valeurs par défaut raisonnables et est facilement personnalisable.
Spacy permet à l’utilisateur de spécifier des tokens spéciaux qui ne seront pas segmentés ou qui seront segmentés de certaines manières spécifiques. Par exemple, si vous voulez garder les points de suspension comme un seul token, vous pouvez le spécifier comme une règle et celle-ci aura la priorité sur les autres opérations de division. Pour en savoir plus sur le fonctionnement du tokenizer Spacy, Spacy divise en espaces et examine ensuite chaque sous-chaîne individuelle. Il recherche d’abord les tokens spéciaux et quand ils ne sont pas présents, il divise certains préfixes (comme la ponctuation), puis les suffixes et les infixes.
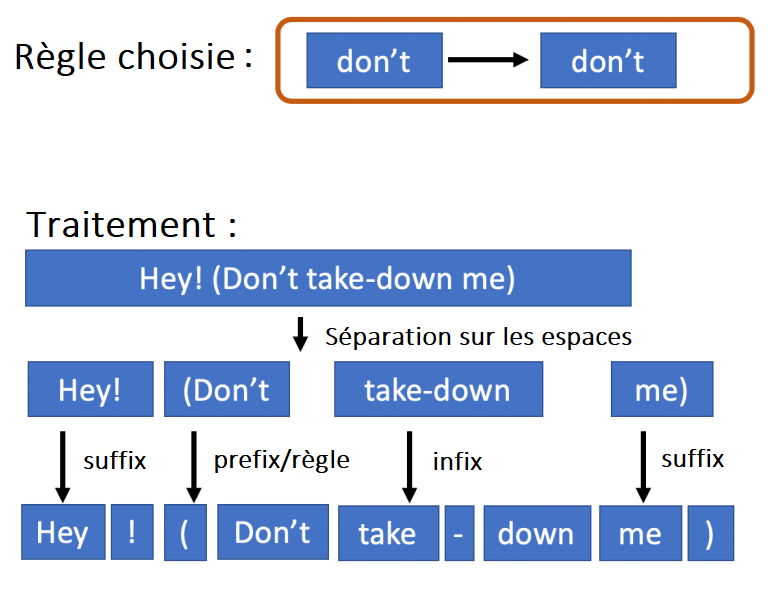
Toutes ces étapes sont personnalisables, ce qui signifie que vous pouvez adapter les règles de tokenisation à vos envies. Vous pouvez consulter la documentation officielle pour obtenir les informations les plus récentes et les plus approfondies.
2.2.2 Moses
Le tokenizer Moses est un tokenizer classique qui est beaucoup plus ancien que Spacy et qui est largement utilisé en traduction automatique. Comparé à Spacy il est moins personnalisable. Je n’entrerai pas dans les détails concernant les spécificités du tokenizer Moses, principalement parce qu’il s’agit d’une collection de logiques complexes de normalisation et de segmentation (vous pouvez jeter un oeil à une implémentation Python ici).
Le tokenizer Moses remplace en interne certains tokens spéciaux (par exemple des points de suspension) par des tokens personnalisés et est un bon exemple de la façon dont la normalisation et la tokenisation ne sont pas toujours proprement divisées.
Moses fonctionne assez bien sur une langue simple, mais si vous manipulez du texte comme du texte de médias sociaux, cela peut causer des problèmes avec certaines entrées comme les émoticônes.
2.2.3 Limitations des tokenizers basés sur des règles
Il y a quelques problèmes avec les tokenizers à base de règles. Le premier est leur capacité relativement limitée à gérer efficacement les mots rares. Par exemple, le mot « structurally » est relativement rare, mais le mot « structural » est commun, ce qui nous permet de déduire le sens de « structurellement » à partir d’un mot plus fréquent. Bien sûr, nous pourrions spécifier chaque mot rare comme une règle spéciale, mais cela devient clairement beaucoup trop complexe très rapidement. Cette incapacité à segmenter les mots en composantes significatives peut être particulièrement problématique pour des langues comme l’allemand où les mots sont souvent composés en mettant ensemble de nombreuses parties indépendantes (on parle alors de langues morphologiquement riches. Cet article en anglais montre l’exemple d’un mot allemand faisant plus de 63 lettres).
Un autre problème majeur est que toutes les langues ne divisent pas les mots via des espaces blancs. Le chinois et le japonais en sont d’excellents exemples. Ces langues exigent donc des règles beaucoup plus sophistiquées ce qui signifie plus de complexité et potentiellement d’erreurs.
Il existe une classe d’algorithmes qui tentent de résoudre ces problèmes, communément appelés méthodes de tokenization en subword, que nous allons aborder dans la suite.
2.3 3. Tokénisation en sous-mots (subword Tokenization)
Tous les algorithmes de tokenisation en sous-mots partagent l’idée fondamentale que les mots les plus fréquents devraient recevoir des identificateurs uniques, alors que les mots moins fréquents devraient être décomposés en sous-mots qui conservent le mieux leur signification. Par exemple, nous pouvons vouloir retenir le mot « wonderfully” comme un seul mot puisqu’il apparaît souvent dans notre jeu de données et que nous pouvons nous attendre à ce que le modèle en apprenne la signification. D’autre part, nous pouvons vouloir diviser « structurally » en « structural » et « ly » puisque « structurally » est peu courant et que nous voulons aider le modèle en lui donnant de l’information sur sa composition.
Nous allons passer en revue quatre algorithmes majeurs de tokenisation en sous-mots : le byte-pair encoding (BPE), le wordpiece, l’unigram language model, et le sentencepiece.
2.3.1 Le Byte-Pair Encoding (BPE)
Le Byte-pair encoding (BPE) pour sous-mots a été proposée dans cette publication par Sennrich, Haddow et Birch. L’idée de base (qui est un algorithme de compression) existe néanmoins depuis 1994. Ce n’est pas une coïncidence si le BPE tire ses racines du domaine de la théorie de l’information et de la compression. L’idée de représenter des mots fréquents avec moins de symboles, et des mots moins fréquents avec plus de symboles est exactement l’idée derrière de nombreux schémas d’encodage tels que l’encodage de Huffman. Le BPE applique simplement les mêmes principes et techniques de façon intelligente à la tokenization. BPE est un algorithme de tokenisation ascendante de sous-mots qui apprend un vocabulaire de sous-mots d’une certaine taille (la taille du vocabulaire étant un hyperparamètre). L’idée de base est la suivante :
-
Commencez par diviser tous les mots en caractères unicode. Chaque caractère unicode correspond à un symbole dans le vocabulaire final. Nous commencerons avec ce vocabulaire minimal et l’élargirons progressivement.
-
Tant qu’il reste de la place dans le vocabulaire, faites ce qui suit :
- Trouvez le symbole bigramme le plus fréquent (paire de symboles)
- Fusionnez ces symboles pour créer un nouveau symbole et ajoutez-le au vocabulaire. Ceci augmente la taille du vocabulaire de 1.
Pour illustrer cela, prenons un exemple. Supposons que nous ayons les mots « bed », « ted », « sad », « beds » et « mad » à partir desquels nous voulons construire un vocabulaire BPE de taille 10. Nous commençons avec le vocabulaire minimal et les mots segmentés en caractères individuels.
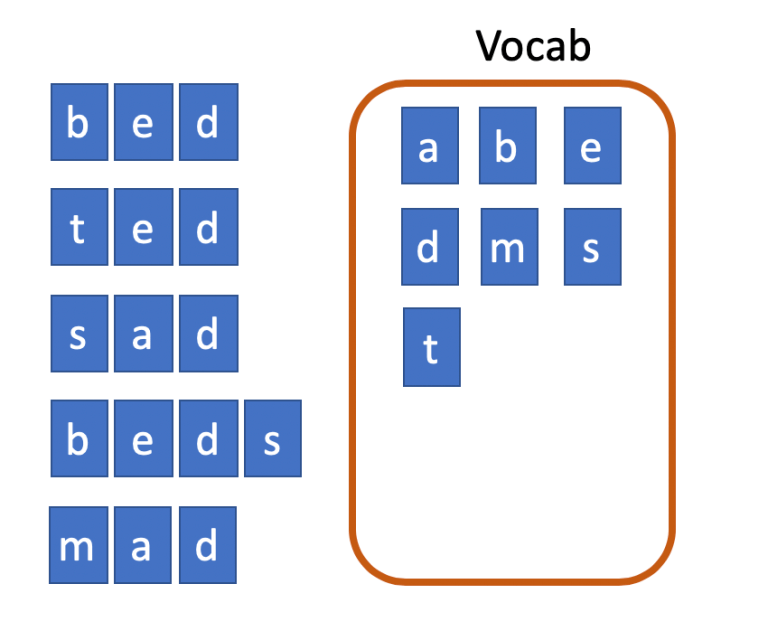
Le symbole bigramme le plus fréquent est « ed » qui apparaît 3 fois. Nous les fusionnons donc et ajoutons un nouveau symbole au vocabulaire.
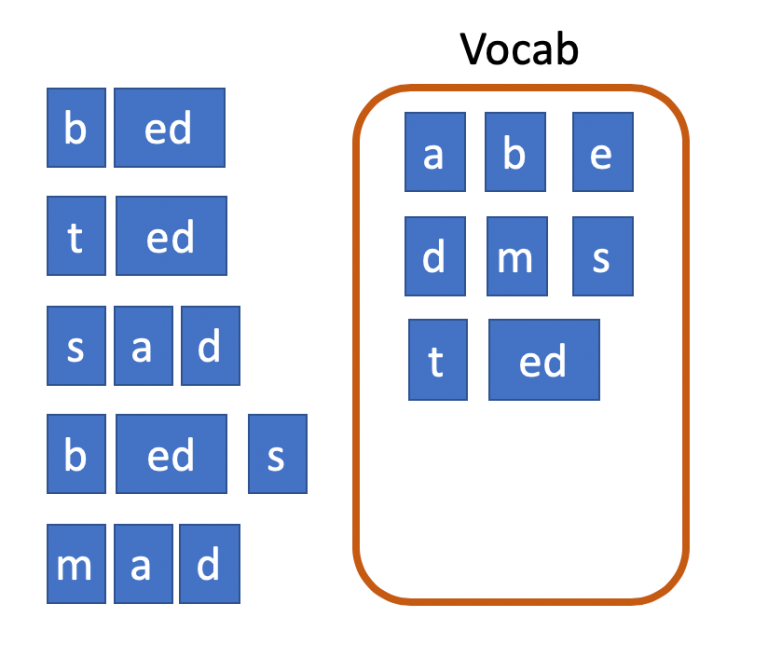
Le symbole suivant le plus fréquent (à égalité avec 2 apparitions) est « ad ». Nous les fusionnons et ajoutons le nouveau symbole au vocabulaire une fois de plus. Cela porte la taille du vocabulaire à 9.
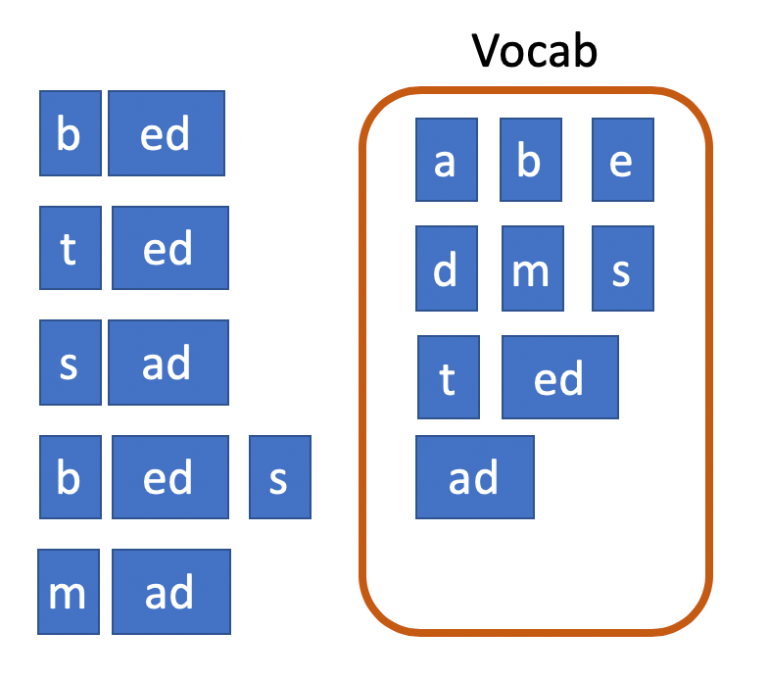
Enfin, nous fusionnons « b » et « ed » car cette paire de symboles apparaît également deux fois, ce qui porte la taille du vocabulaire à 10 et met fin à notre construction de vocabulaire. La segmentation qui en résulte est ce que nous utiliserons pour la tokenisation en utilisant notre modèle BPE appris.
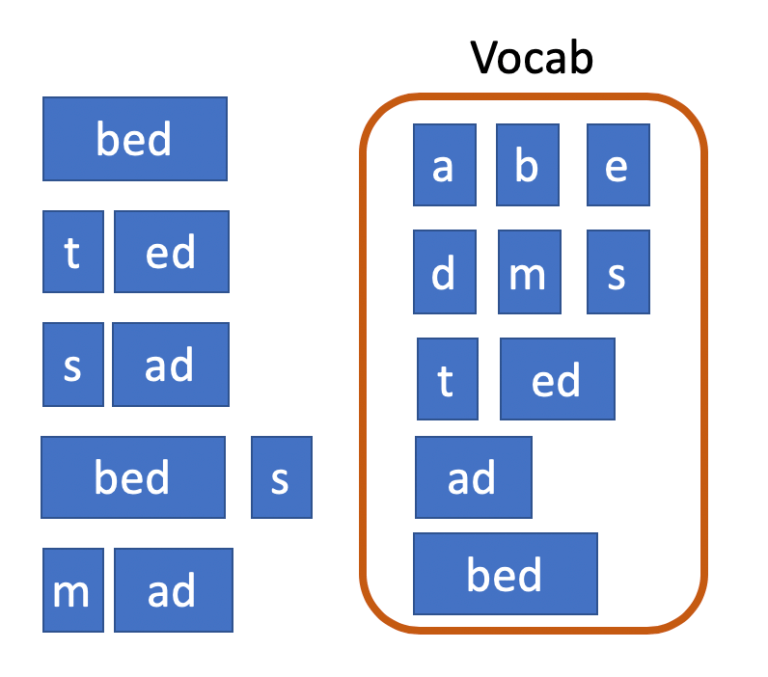
Bien sûr, nous voulons faire la distinction entre « ed » comme un seul mot et le suffixe « ed », donc en réalité nous représenterions le suffixe comme « ##ed ». (Si ce symbole « ## » préfixé vous semble familier, c’est parce que de nombreux modèles modernes pré-entrainés utilisent la tokenisation de sous-mots ; en d’autres termes, si vous voyez vos entrées tokénisées de cette façon, il est probable qu’il y ait une tokenisation en sous-mots qui se déroule quelque part dans les coulisses).
L’exemple ci-dessus utilise des mots individuels, ce qui soulève la question suivante : que se passe-t-il lorsque nous utilisons des phrases entières ? Une des caractéristiques délicates du BPE est qu’il commence par tokeniser l’entrée et ne fusionne que les bigrammes de symboles dans un seul token. C’est pour l’efficacité du calcul, puisque trouver le bigramme le plus fréquent est une opération coûteuse (s’il y a N symboles, c’est une opération O(N²)). Une autre question que vous pourriez vous poser est de savoir ce qui se passe si nous rencontrons un caractère unicode inédit dans le vocabulaire. Il existe plusieurs solutions à ce problème. L’une d’entre elles consiste simplement à associer des caractères invisibles à un token « unk » (pour inconnu). Une autre est d’allouer un id à chaque caractère unicode possible même si nous ne le rencontrons pas dans le texte (ce n’est clairement pas réaliste et c’est plus pour le plaisir de l’argumentation).
Une approche intelligente proposée par l’équipe d’Open AI dans son article sur le GPT-2 est de traiter l’entrée comme une séquence d’octets au lieu de caractères unicode et d’attribuer un identifiant à chaque octet possible. Puisque les caractères unicode sont représentés par un nombre variable d’octets, même si nous rencontrons un tout nouveau caractère, nous pouvons le décomposer en ses octets constitutifs dans le pire des cas, empêchant ainsi l’apparition de tokens inconnus.
2.3.2 Wordpiece
Peut-être le plus célèbre en raison de son utilisation dans BERT, wordpiece est un autre algorithme de tokenisation en sous-mots largement utilisé. L’algorithme (décrit dans la publication de Schuster et Kaisuke) est en fait pratiquement identique à BPE. La seule différence est qu’au lieu de fusionner le bigramme de symbole le plus fréquent, le modèle fusionne le bigramme qui, une fois fusionné, augmenterait la probabilité d’un modèle de langage unigramme entrainé sur les données d’entraînement.
Attention. Ici et jusqu’à la fin de cette section 2.3.2, je traduis ce que l’auteur de l’article original à compris de cette méthode. En effet, il précise qu’il n’a pas trouvé de code source d’une implémentation de cette méthode et n’a donc pas pu la décortiquer en entier. Il explique donc ce qu’il a compris mais précise qu’il n’exclut pas de s’être tromper en absence de code pour confirmer ou infirmer ses explications.
Si son raisonnement est correct, cela signifie qu’en plus de la fréquence du bigramme, la fréquence des symboles originaux qui constituent le bigramme est également prise en compte. Le logarithme de la probabilité d’une phrase dans un modèle de langage unigramme (en supposant l’indépendance entre les mots d’une phrase) est simplement la somme des logarithmes des fréquences des symboles qui la composent. Cela signifie que la fusion de deux symboles augmentera le logarithme de la probabilité totale du symbole fusionné et la diminuera le logarithme de la probabilité des deux symboles originaux. En supposant que nous fusionnons les symboles x et y, l’augmentation du logarithme de la probabilité est :
\[\log p(x,y) - \log p(x) - \log p(y) = \log \displaystyle \frac{\log p(x) }{\log p(x) \log p(y) }\]De nouveau, si le raisonnement est correct, ceci est donc équivalent à l’information mutuelle entre deux symboles, donc wordpiece peut être considéré comme une variante de BPE qui fusionne sur la base de l’information mutuelle au lieu de la fréquence.
RoBERTa est une version « optimisée » de BERT. Dans leur publication, les auteurs utilisent BPE au lieu du wordpiece de BERT et ont trouvé que cette décision ne faisait pas une grande différence.
2.3.3 Unigram Language Model
L’algorithme de tokenization de l’unigram language model a été proposé à l’origine dans cet article par Taku Kudo. Bien qu’il utilise des principes similaires aux méthodes décrites précédemment, il est en fait entraîné très différemment dans la pratique.
L’idée de base de ce tokenizer est d’entraîner un modèle de langage en unigramme, en supposant que tous les mots se produisent indépendamment les uns des autres. Il utilise ensuite ce modèle pour trouver la segmentation la plus probable de chaque mot. L’avantage de cette méthode est qu’elle utilise un modèle probabiliste, ce qui signifie qu’en plus de trouver la segmentation la plus probable, vous pouvez échantillonner des segmentations à partir d’une distribution de probabilités. Ceci est utilisé dans une méthode d’augmentation des données abordée plus loin dans la partie 3 de l’article.
La différence entre cette méthode et le wordpiece est que le wordpiece maximise la probabilité d’un modèle linguistique unigramme en fusionnant les symboles. Cela est possible car wordpiece ne fait pas directement référence au modèle de langue, ce qui rend la segmentation indépendante de celui-ci.
Dans le tokenizer de l’unigram language model, la segmentation dépend du modèle de langue. Cela crée une dépendance cyclique : pour entraîner un modèle de langue, nous devons compter la fréquence de tous les mots d’un vocabulaire, ce qui nécessite de savoir comment segmenter le texte dans le corpus d’entraînement en premier lieu. Mais pour savoir comment segmenter le texte dans le corpus d’entraînement, nous avons besoin du modèle de langue ! Pour gérer cette dépendance cyclique, le modèle de langue unigramme est entraîné selon le processus suivant :
- Initialiser un grand vocabulaire provisoire. Ce vocabulaire pourrait être construit en utilisant un simple tokenizer à base de règles.
- Entraîner le modèle de langage unigramme en utilisant l’algorithme EM.
- Réduire la taille du vocabulaire en supprimant les symboles qui contribuent le moins à la probabilité globale du modèle de langage sur l’ensemble d’apprentissage.
- Répétez les étapes 2 à 4 jusqu’à ce que la taille du vocabulaire soit suffisamment réduite.
L’unigram language model prend également soin de conserver les caractères individuels pour minimiser la probabilité de tokens hors du vocabulaire.
2.3.4 Sentencepiece
Toutes les méthodes que nous avons étudiées jusqu’à présent nécessitent une forme de prétokenisation. Vous remarquerez que cela ne résout pas l’un des problèmes que nous avons exposés au début : toutes les langues ne peuvent pas être facilement tokenizées, en particulier celles qui ne sont pas séparées par des espaces. C’est un problème particulièrement épineux pour les applications multilingues, car cela signifie que vous devez potentiellement utiliser un token séparé pour chaque langue que vous traitez.
Un autre problème créé par la prétokenisation est qu’elle rend la détokenisation impossible dans certains cas. Par exemple, si un tokenizer se divise sur les espaces et la ponctuation, il va tokeniser les phrases :
I like natural language processing
et
I like natural language processing
de la même manière, ce qui signifie que nous ne pouvons pas récupérer la forme de la phrase originale.
Sentencepiece résout les deux problèmes en traitant l’entrée comme un flux brut de caractères unicode. Il utilise ensuite soit le codage BPE, soit le codage de l’unigram language model au niveau des caractères pour construire le vocabulaire approprié. Cela signifie que les espaces sont inclus dans la tokenisation. Par exemple, avec l’unigram language model, I like natural language processing peut être tokénissé comme
“I”, “_like”, “_natural”, “_lang”, “uage”, “_process”, “ing”
où le caractère espace est remplacé par le trait de soulignement (“ _ “) pour plus de clarté.
Notez la distinction avec BPE, où la séquence ci-dessus avec les mêmes sous-mots est tokénisée par
“I”, “like”, “natural”, “lang”, “##uage”, “process”, “##ing”
où les sous-mots sont précédés d’un marqueur spécial.
L’ajout de sous-mots avec un marqueur spécial n’a de sens qu’avec un modèle de prétokenisation, puisque sentencepiece ne connaît pas les limites des mots.
Maintenant, vous vous demandez peut-être pourquoi sentencepiece peut se permettre de traiter l’entrée comme un seul flux de caractères alors que nous avons établi plus tôt que trouver le symbole bigramme le plus fréquent est une opération d’un coût prohibitif avec BPE. La raison est que sentencepiece utilise un algorithme basé sur une file d’attente prioritaire, réduisant le temps d’exécution asymétrique de O(N²) à O(NlogN).
Notez également que sentencepiece permet en fait l’utilisation de la prétokenisation (dans ce cas, il devient essentiellement le même que le BPE/l’unigram language model).
Un point où il faut être vigilant est que sentencepiece applique une certaine normalisation unicode en interne (il utilise la normalisation unicode NFKC par défaut). Ceci peut être personnalisé, donc si vous avez besoin de règles de normalisation personnalisées qui sont en contradiction avec la normalisation NFKC, alors vous devriez regarder cette fonctionnalité.
2.3.5 Limitations des Subword Tokenizers
Comme les tokenizers de sous-mots sont appris à partir de données, la qualité et la quantité des données sont cruciales pour obtenir de bonnes performances. Lorsque vous n’avez pas beaucoup de données, il peut être préférable d’utiliser un tokenizer basé sur des règles, tout comme les systèmes basés sur des règles peuvent être meilleurs que les systèmes basés sur l’apprentissage machine lorsque les données sont rares.
Un autre problème avec certains tokenizers en sous-mots qui fonctionnent sur des flux de caractères/octets est qu’ils peuvent allouer de l’espace de vocabulaire à de multiples variations d’un même mot (par exemple « chien », « chien ! », « chien ? »). Pour éviter cela, les auteurs du GPT-2 proposent d’empêcher la fusion entre différents types de caractères (par exemple les caractères et la ponctuation) à l’exception des espaces.
Un autre facteur à prendre en compte est que l’apprentissage d’un tokenizer est beaucoup plus coûteux que la tokenization réelle et peut être assez intensif en mémoire et coûteux en calcul puisqu’il doit garder les données en mémoire pour un comptage et une génération rapide de statistiques. Par conséquent, même si vous avez des téraoctets de données pour apprendre un modèle de phrase, cela peut ne pas être possible de tout utiliser.
3. Étape 3 : Numérisation
Une fois que nous avons les données tokénisées, la construction du vocabulaire semble relativement simple. En particulier pour les méthodes comme BPE et sentencepiece, le vocabulaire est construit automatiquement. Donc, fin de l’histoire, n’est-ce pas ? Eh bien, pas tout à fait. Il y a encore pas mal de questions auxquelles nous devons réfléchir.
3.1 Manipulation des entrées inconnues
Dans l’ensemble de test ou dans les données futures, nous pouvons rencontrer des caractères que nous n’avons pas rencontrés dans l’ensemble d’entraînement. Comme la plupart des frameworks de NLP modernes gèrent ces caractères inconnus en coulisses, cela peut conduire à des bugs insidieux dans votre code. Il est alors conseillé de vérifier périodiquement quels types de mots sont traités comme inconnus.
L’utilisation de l’encodage d’Open AI qui s’effectue au niveau de l’octet peut légèrement résoudre ce problème, mais même avec l’encodage au niveau de l’octet, vous rencontrerez des caractères qui n’ont jamais été trouvés dans le jeu d’entraînement. Cela signifie que l’enchâssement de ces caractères sera le même que lorsqu’ils ont été initialisés et donc probablement très différent de la distribution des enchâssements entrainés. Le simple fait que vous ayez un identifiant pour les caractères non vus ne signifie pas que votre modèle peut ou a appris à les manipuler, vous devez donc faire attention à ne pas vous laisser bercer par un faux sentiment de sécurité.
3.2 Gestion du vocabulaire
Un décalage entre le vocabulaire utilisé pour coder le jeu d’entraînement et celui du jeu de test est une erreur étonnamment courante. Cela peut se produire particulièrement facilement lorsque vous reconstruisez périodiquement le vocabulaire, ce qui peut être inévitable dans des domaines comme les médias sociaux où la distribution de la langue peut changer rapidement.
S’assurer que chaque modèle est explicitement lié à un ensemble de vocabulaire est une façon d’éviter ce problème. Un autre moyen est d’assurer la rétrocompatibilité entre les différents vocabulaires de sorte que les mots qui sont dans les deux vocabulaires soient toujours associés au même identifiant. Cependant, empêcher le vocabulaire d’exploser en taille et de manipuler des tokens inconnus devient un problème dans cette approche. Une autre solution (qui est utile dans d’autres contextes également) est d’utiliser des vocabulaires ouverts, décris dans le prochain paragraphe.
3.3 Vocabulaires ouverts
Les vocabulaires ouverts sont essentiellement des paramètres où vous ne préconstruisez pas un vocabulaire mais où vous associez plutôt des tokens à des ids à la volée.
C’est particulièrement utile dans les situations où vous devez gérer des flux de texte continus et où l’actualisation du vocabulaire est coûteuse et sujette à erreur. Les vocabulaires ouverts utilisent l’astuce du hachage, une méthode intelligente de numérisation qui fait correspondre les tokens aux ids en fonction de leurs valeurs de hachage. Par exemple, avec un id maximum de 100 000, vous pouvez utiliser une simple fonction de hachage (comme le hachage md5) pour transformer toute séquence de caractères unicode (ou d’octets) en un entier compris entre 0 et 100 000. Ce serait l’id du token. Puisque le vocabulaire est déterminé uniquement par la fonction de hachage, il n’a jamais besoin d’être reconstruit.
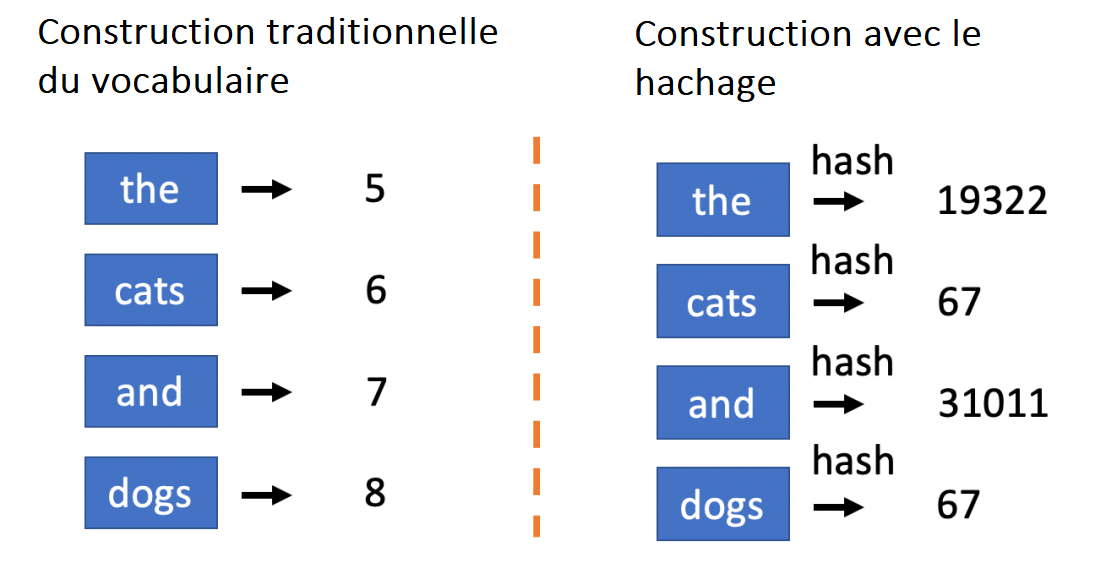
Cette approche simple a le problème évident des collisions de hachage : un seul identifiant pourrait correspondre à plusieurs tokens ayant des significations très différentes. La probabilité que cela arrive (étant donné une taille de vocabulaire suffisamment importante) est cependant extrêmement faible, d’autant plus que la plupart des mots sont très peu fréquents (les fréquences des mots obéissent typiquement à la loi de Zipf qui stipule que la fréquence d’un mot est à peu près inversement proportionnelle à son classement en termes de fréquence). Par conséquent, pour certaines applications, quelques collisions de hachage pourraient être un petit prix à payer pour la simplicité d’un vocabulaire ouvert.
3.4 Surentraînement du vocabulaire au jeu d’entraînement
Une illustration du surentraînement du vocabulaire est la suivante. Imaginons la création d’un vocabulaire utilisant tous les mots du jeu d’entraînement sans en limiter la taille. Dans ce cas, tous les mots que le modèle verra pendant l’entraînement auront un identifiant unique associé à celui-ci. Cela signifie que le modèle ne rencontrera jamais un mot inconnu et n’apprendra donc jamais à le manipuler. Par conséquent, lorsque nous lui donnerons le jeu de test (qui contiendra très probablement des mots inconnus auparavant), il aura probablement de mauvaises performances sur les exemples avec des mots nouveaux. Comparons cela avec l’entraînement du vocabulaire sur un ensemble de validation. Dans ce cas, le modèle devrait apprendre à traiter les mots de l’ensemble d’entraînement qui ne sont pas dans le vocabulaire, peut-être en déduisant leur signification ou en les ignorant.
Cela peut aussi se produire dans le cas d’algorithmes comme le BPE, même s’il n’y a pas de tokens inconnus : le vocabulaire sera ajusté sur les fréquences du jeu d’entraînement, donc tous les tokens que le modèle voit pendant l’entraînement ont une fréquence artificiellement élevée. Cela peut faire que des mots qui ne sont pas courants en général ne soient pas tokenisés, ce qui empêche le modèle d’apprendre à utiliser efficacement les sous-mots.
Une solution potentielle à cela est d’entraîner un tokenizer en sous-mots sur un énorme corpus non labélisé afin qu’il puisse extraire des sous-mots pertinents pour la langue dans son ensemble et non pour un jeu de données particulier. C’est probablement la meilleure approche si vous avez suffisamment de données non étiquetées.
Lorsque vous n’avez pas assez de données non étiquetées, il y a quelques approches que vous pouvez effectuer. L’une d’elles consiste à utiliser le jeu d’entraînement pour entraîner votre token et votre vocabulaire et à espérer que tout ira bien. Une autre est d’utiliser un échantillon du jeu d’entraînement pour entraîner le token et le vocabulaire de sorte que le modèle rencontre des tokens inconnus avec une certaine probabilité. Vous pouvez également définir un seuil pour le vocabulaire afin que les mots ne reçoivent un identifiant unique que s’ils dépassent une certaine fréquence. Notez que cela suppose que la distribution des nouveaux mots dans le jeu de test reflétera la distribution des mots à faible fréquence dans le jeu d’entraînement, une hypothèse qui n’est pas toujours vraie.
3.5 Changement des vocabulaires préfabriqués
Malgré toute la discussion ci-dessus sur la façon de gérer et de construire des vocabulaires, dans certains cas, nous n’avons même pas notre mot à dire sur le vocabulaire. Par exemple, si nous utilisons BERT, nous sommes la plupart du temps coincés avec le vocabulaire que les auteurs nous ont donné. Cela peut être un problème, par exemple, si nous voulons réduire la taille du vocabulaire pour tronquer la matrice d’enchâssement afin que le modèle tienne sur un téléphone.
Cet article propose une approche intéressante pour résoudre ce problème. Il utilise une approche élève-enseignant (student-teacher) pour distiller un modèle enseignant, et entraine un modèle élève avec un vocabulaire réduit en donnant au modèle enseignant un mélange d’entrées tokénisées par le modèle élève et le modèle enseignant. Cette idée de mélanger les vocabulaires de l’élève et de l’enseignant est intéressante et semble être une idée qui mérite d’être explorée en dehors de la simple compression du modèle.
4. Divers
Terminons par quelques points non classables dans les parties précédentes.
4.1 Filtrage des données de faible qualité
Jusqu’à présent, nous avons discuté de la façon de traiter les données quand vous avez déjà un jeu de données en place. Cependant, parfois, vous devez effectuer un filtrage supplémentaire avant/pendant la construction du jeu de données. Par exemple, si vous voulez entraîner un modèle de langage basé sur un grand corpus, vous pouvez utiliser les données de Twitter. Cependant, les données de Twitter peuvent être très bruitées, contenant du charabia, du contenu dupliqué, d’autres langues et d’autres données de mauvaise qualité/non pertinentes que vous voulez exclure.
Cet article de G.Wenzek, M-A. Lachaux et al., traite de diverses préoccupations et méthodes concernant la construction de corpus monolingues de haute qualité pour diverses langues à l’aide de données Common Crawl. Leurs principales étapes de prétraitement comprennent la déduplication des documents à l’aide du hachage, la détection de la langue et le filtrage du contenu en fonction de leur score de perplexité sur un modèle linguistique.
4.2 Preprocessing comme augmentation de données
Le fait que les décisions de prétraitement sont quelque peu arbitraires et peuvent causer du bruit peut en fait être utilisé à notre avantage. Par exemple, un modèle qui est entrainé sur des données d’entrée entièrement en minuscules et un modèle qui est entrainé avec du surajustements peuvent être assemblés efficacement. Keita Kurita (l’auteur de l’article dont fait l’objet cette traduction) a utilisé cette technique pour se classer dans le top 1% d’une compétition Kaggle. Dans certains concours Kaggle de NLP, l’assemblage de plusieurs modèles en utilisant différentes étapes de prétraitement a été la clé de la victoire.
L’idée d’utiliser le prétraitement comme augmentation des données est explorée dans cet article de Taku Kudo où l’auteur utilise un modèle de langage unigramme pour échantillonner des tokenisations légèrement différentes du même texte.
4.3 Stemming et Lemmatization
Le stemming et la lemmatization sont des formes extrêmes de normalisation qui ne sont généralement pas rentables en traitement du langage moderne (depuis l’apparition des transformers). La plupart des problèmes que le stemming et la lemmatization adressent peuvent être résolus en utilisant des sous-mots symboliques, il n’y a donc tout simplement aucune raison d’utiliser ces étapes de prétraitement.
Conclusion
Résumons l’article avec les principaux points évoqués :
- Utilisez l’unicode. Cela permet de gérer à peut prêt toutes les langues.
- Si vous utilisez un transformer, assurez-vous que votre prétraitement correspond à celui utilisé par le modèle.
- Inspectez toujours manuellement vos entrées prétraitées. Vous serez surpris du nombre de bugs que vous pouvez attraper.
- La normalisation est la première étape du prétraitement, et une considération majeure à cette étape est la quantité de données que vous avez. Plus vous avez de données, moins vous avez besoin de normalisation.
- Les tokenizers à base de règles sont un bon point de départ pour de nombreuses langues mais peuvent être difficiles à mettre à l’échelle.
- Les tokenizers en sous-mots apprennent les segmentations qui divisent les mots rares en sous-mots significatifs. Ils sont appris à partir de données et sont généralement efficaces pour traiter les mots rares et les langues riches comme l’allemand.
- Les tokenizers BPE, wordpiece, et unigram language model ont besoin d’une précréation. Sentencepiece n’en a pas besoin.
- La construction du vocabulaire comporte de nombreuses subtilités. En particulier, faites attention au surentraînement avec les données d’entraînement.
Références
-
What Is the Longest German Word ? de Flippo (2020)
-
SentencePiece: A simple and language independent subword tokenizerand detokenizer for Neural Text Processing de Kudo et Richardson (2018)
-
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates de Taku Kudo (2018)
-
A Deep Dive into the Wonderful World of Preprocessing in NLP de Keita Kurita (2020)
-
RoBERTa: A Robustly Optimized BERT Pretraining Approach de Liu et al. (2019)
-
A Call for Clarity in Reporting BLEU Scores de Matt Post (2018)
-
Language Models are Unsupervised Multitask Learners de Radford et al. (2019)
-
Japanese and Korean voice search de Schuster et Nakajima (2012)
-
When “Zoë” !== “Zoë”. Or why you need to normalize Unicode strings de Alessandro Segala (2019)
-
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data de Wenzek, Lachaux et al. (2019)
-
Extreme Language Model Compression with Optimal Subwords and Shared Projections de Sanqiang Zhao et al. (2019)
Citation
@inproceedings{tokenizers_blog_post,
author = {Loïck BOURDOIS},
title = {Le prétraitement et les tokenizers en NLP},
year = {2020},
url = {https://lbourdois.github.io/blog/nlp/Les-tokenizers/}
}