Avant-propos
Cet article est une traduction de l’article de Amit Chaudhary : Visual Paper Summary: ALBERT (A Lite BERT).
Merci à lui de m’avoir autorisé à effectuer cette traduction.
J’ai ajouté des éléments supplémentaires quand j’estimais que cela était pertinent.
Introduction
Considérons une phrase donnée ci-dessous. En tant qu’humains, lorsque nous rencontrons le mot « orange », nous pourrions :
- associer le mot « orange » à notre représentation mentale du fruit,
- associer « orange » au fruit plutôt qu’à l’entreprise en fonction du contexte
- comprendre la situation globale : « Il mange une orange »
Le principe de base des derniers développements en NLP est de donner aux machines la possibilité d’apprendre de telles représentations.
En 2018, Google a publié BERT tentant d’apprendre des représentations en se basant sur quelques idées nouvelles.
Dans cet article, nous allons succinctement rappeler ces approches pour ensuite nous focaliser sur leurs problèmes mais aussi les solutions apporter par les auteurs d’ALBERT afin de les résoudre.
1. Récapitulatif des points importants de BERT
1.1 Modélisation du langage masqué (MLM)
La modélisation du langage consiste essentiellement à prédire un mot en fonction de son contexte pour apprendre la représentation. Traditionnellement, il s’agit de prédire le mot suivant dans une phrase donnée, compte tenu des mots.

BERT utilise quant à lui un modèle de langage masqué, dans lequel nous masquons aléatoirement des mots dans un document et essayons de les prédire en fonction du contexte environnant.

1.2 Prédiction de la phrase suivante
L’idée de la prédiction de la phrase suivante est de détecter si deux phrases sont cohérentes ou non lorsqu’elles sont placées l’une après l’autre.

Pour faire cela, des phrases consécutives tirées des données d’entraînement sont utilisées comme exemple positif.
Pour l’exemple négatif, nous prenons une phrase donnée et plaçons à la suite une phrase aléatoire prise dans un autre document.
Le modèle BERT est entraîné à cette tâche afin de déterminer si deux phrases peuvent être placées l’une à côté de l’autre.
1.3 Architecture du transformer
Pour résoudre les deux tâches ci-dessus, BERT utilise une pile de couches de blocs encodeurs du transformer. Des vecteurs de mots sont passés à travers les couches pour capturer la signification et créer un vecteur de taille 768 pour le modèle de base.
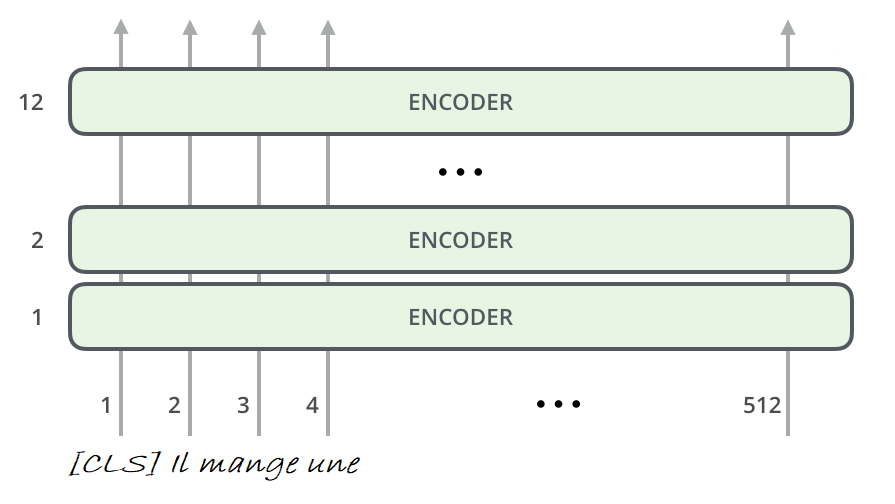
Pour plus de détails, je vous invite à lire les articles du blog consacré au transformer et à BERT.
2. Les problèmes de BERT
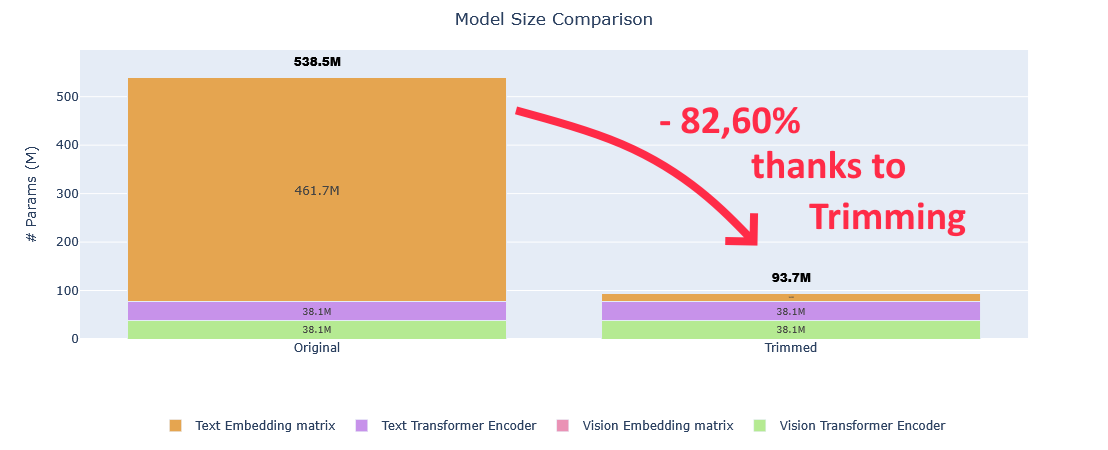
Lors de sa publication BERT a produit des résultats de pointe sur de nombreuses tâches de NLP. Cependant ce modèle est de très grande taille, ce qui a entraîné quelques problèmes. Le modèle ALBERT met en évidence ces problèmes dans deux catégories :
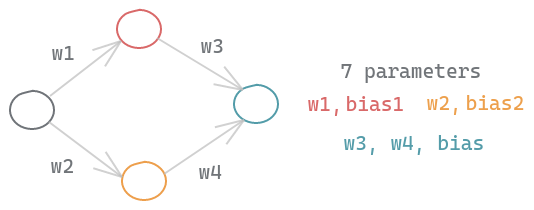
2.1 Limitation de la mémoire et coût de communication
Considérons un simple réseau neuronal avec un neurone d’entrée, deux cachés et un de sortie. En tenant compte des poids et des biais de chaque neurone, ce réseau très simple a 7 paramètres à apprendre :
BERT-large a 340 millions de paramètres en raison de ses 24 couches cachées, des têtes d’attentions et des neurones dans le réseau feed-forward.
Si vous vouliez vous appuyer sur le travail effectué sur BERT et y apporter des améliorations, vous auriez besoin de grosses capacités de calcul pour l’entraîner à partir de zéro.
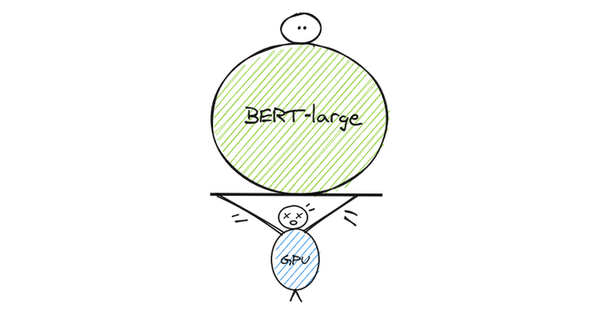
Ces besoins de calcul concernent principalement les GPUs et les TPUs, mais ces dispositifs ont une limitation de mémoire. Il y a donc une limite à la taille des modèles.
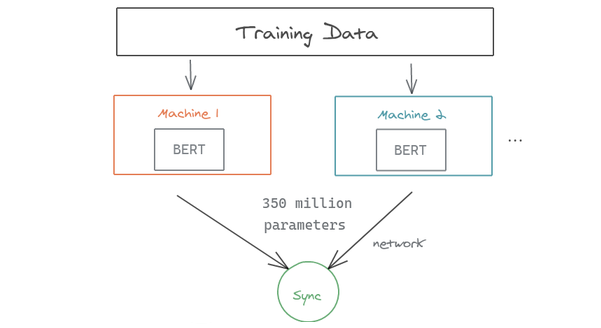
Pour entraîner, BERT-large, les auteurs ont dû procéder à du parallélisme : les données d’entraînement ont été divisées en deux machines.
Comme le montre la figure ci-dessous, vous pouvez remarquer comment le grand nombre de paramètres à transférer lors de la synchronisation des gradients peut ralentir le processus d’entraînement. Il est également nécessaire de stocker les différentes parties du modèle (paramètres) sur différentes machines.
2.2 Dégradation du modèle
La tendance récente dans la communauté des chercheurs en NLP est d’utiliser des modèles de plus en plus grands afin d’obtenir de meilleures performances. Les auteurs d’ALBERT montre que cela peut au contraire dégrader les résultats.
En effet, dans leur article, ils ont réalisé une expérience intéressante : si des modèles plus grands conduisent à de meilleures performances, pourquoi ne pas doubler les unités de la couche cachée du plus grand modèle BERT disponible (BERT-large) de 1024 unités à 2048 unités ?
Ils l’appellent BERT-xlarge. Celui-ci se révèle moins performant que le modèle BERT-large, aussi bien pour les tâches de modélisation linguistique que pour les tests de compréhension de la lecture (RACE).

3. De BERT à ALBERT
3.1 Factorisation des enchâssements
3.1.1 La logique appliquée par les auteurs
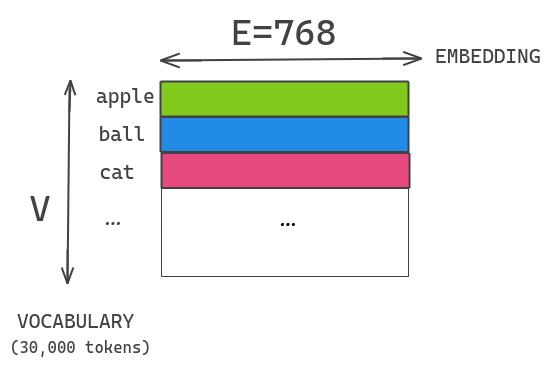
Dans BERT, la taille des enchâssements utilisés (word piece embeddings) est liée à la taille des couches cachées des blocs transformer. Les word piece embeddings ont été entraîné à partir de la représentation one hot d’un vocabulaire de taille 30 000 et sont projetées directement sur l’espace caché de la couche cachée.
Supposons que nous avons un vocabulaire de taille 30K, un word piece embedding de dimension E=768 et une couche cachée de taille H=768. Si nous augmentons les unités cachées dans le bloc, alors nous devons également ajouter une nouvelle dimension à chaque enchâssement. Ce problème se pose également pour XLNET et ROBERTA.
ALBERT résout ce problème en factorisant la matrice des enchâssements en deux matrices plus petites. Cela permet de séparer la taille des couches cachées de la taille des embedding du vocabulaire et de passer d’une complexité O(V×H) à une complexité en O(V×E+E×H). Cette réduction a un intérêt lorsque H > > E.
Illustration : nous projetons le vecteur one hot encoding dans l’espace de dimension inférieure de taille E=100 et ensuite cet espace d’enchâssement dans l’espace caché H=768.
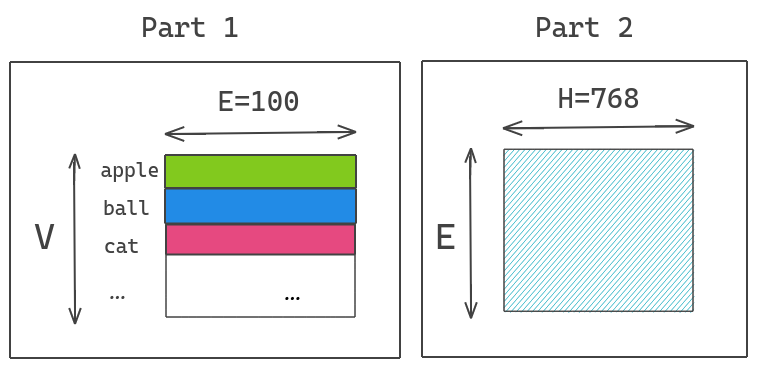
Ainsi ce qu’il faut retenir de ce point, est que nous pouvons augmenter la taille des couches cachées sans augmenter de manière significative la taille des paramètres des enchâssements du vocabulaire.
3.1.2 Les résultats
Pour effectuer leur comparaison avec BERT, les auteurs d’ALBERT ont suivis les mêmes configurations : vocabulaire de taille 30K, entraînement sur les textes de BOOKCORPUS et Wikipédia (en anglais), limitation à des séquences de 512 tokens.
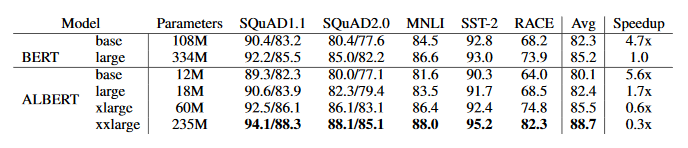
En analysant le tableau ci-dessus, nous pouvons remarquer une importante diminution du nombre de paramètres à configuration égale (par exemple ALBERT large a 18 fois moins de paramètres que BERT large). Cette diminution s’accompagne d’une accélération du temps de calcul (à TPUs identiques).
3.2 Partage des paramètres entre les couches
3.2.1 La logique appliquée par les auteurs
BERT large a 24 couches alors que sa version de base en a 12. Plus nous ajoutons de couches, plus le nombre de paramètres augmente de manière exponentielle :

Pour résoudre ce problème, ALBERT utilise le concept de partage des paramètres entre les couches.
Pour illustrer cela, prenons l’exemple du modèle BERT-base à 12 couches. Au lieu d’apprendre des paramètres uniques pour chacune des 12 couches, nous n’apprenons des paramètres que pour le premier bloc, et nous réutilisons le bloc dans les 11 couches suivantes.
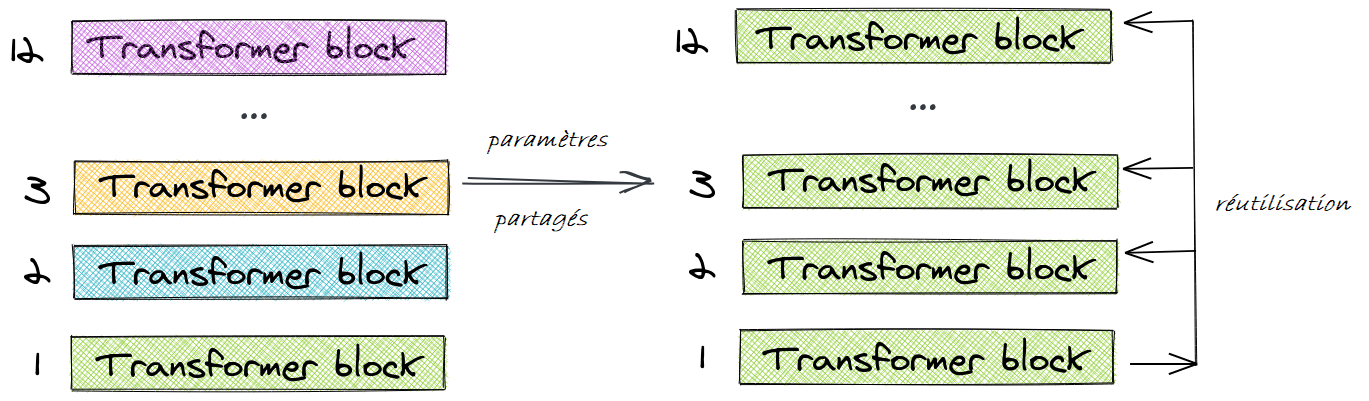
Nous pouvons procéder à différents partages de paramètres. Par exemple :
- partager uniquement les paramètres de la couche feed-forward (shared-FFN dans le tableau ci-après),
- partager uniquement les paramètres d’attention (shared-attention dans le tableau ci-après)
- partager les paramètres de l’ensemble du bloc (all-shared dans le tableau ci-après).
3.2.2 Les résultats
Par rapport aux 110 millions de paramètres de BERT-base, le modèle ALBERT ne compte alors plus que 31 millions de paramètres tout en utilisant le même nombre de couches et 768 unités cachées.

Vous pouvez constater que pour tous les cas où les auteurs ont procédé à un partage de paramètres, une taille d’enchâssement E=128 permet d’obtenir de meilleurs résultats qu’une taille E=768.
Ainsi dans la suite, tous les résultats indiqués correspondent à une taille E=128.
3.3 Prédiciton de l’ordre des phrases
3.3.1 La logique appliquée par les auteurs
La prédiction de la phrase suivante (NSP pour introduit Next Sentence Prediction) par BERT a été spécifiquement créée pour améliorer les performances des tâches qui utilisent des paires de phrases comme l’inférence en langage naturel (NLI). Des publications comme ROBERTA et XLNET ont mis en lumière l’inefficacité de la NSP et ont constaté que son impact n’était pas fiable. En éliminant la tâche de NSP, la performance de plusieurs tâches s’est améliorée.
ALBERT propose quant à lui une tâche alternative appelée prédiciton de l’ordre des phrases (SOP pour Sentence Order Prediction). L’idée clé est la suivante :
- Prendre deux segments consécutifs du même document comme classe positive
- Échanger l’ordre du même segment et utiliser cela comme exemple négatif
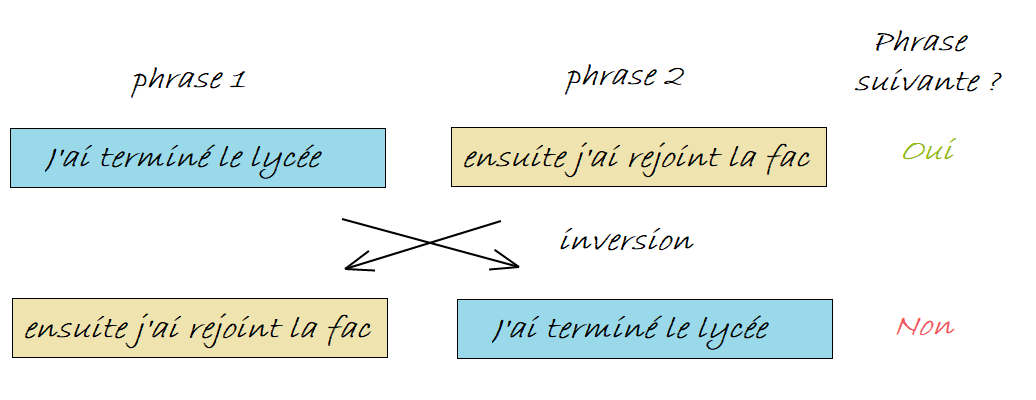
Cela oblige le modèle à apprendre une distinction plus fine des propriétés de cohérence au niveau du discours.
Les auteurs d’ALBERT affirment que la NSP est inefficace car c’est une tâche non difficile à mettre en œuvre par rapport à la modélisation masquée du langage. Elle mélange à la fois la prédiction du sujet et la prédiction de la cohérence. La partie prédiction du sujet est facile à apprendre car elle chevauche la perte du modèle de langage masqué. Ainsi, la NSP donnera des scores plus élevés même s’il n’a pas appris la prédiction de cohérence.
3.3.2 Les résultats
La SOP améliore les performances des tâches de SQUAD 1.1, 2.0, MNLI et RACE :

4. Autres résultats
4.1 Comparaison basée sur le temps d’entraînement
Comme un entraînement plus long entraîne généralement de meilleures performances, les auteurs ont effectué une comparaison dans laquelle, au lieu de contrôler le nombre d’étapes d’entraînement, ils ont contrôlé le temps d’entraînement. Le but étant de comparer les performances à temps d’entraînement égaux.

On peut alors constater qu’ALBERT obtient de meilleur résultat que BERT et notamment sur la base RACE.
4.2 Ajout de données
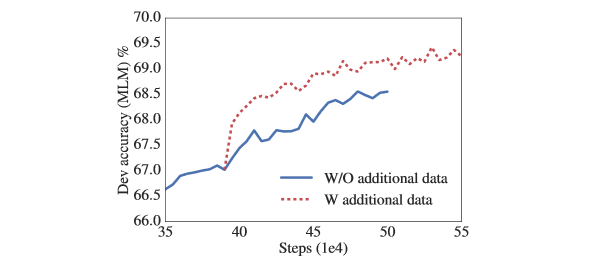
Les expériences réalisées jusqu’à présent utilisent les jeux de données Wikipedia et BOOKCORPUS, comme dans BERT. Les auteurs ont testé d’ajouter les données d’entraînement supplémentaires utilisées par XLNet et RoBERTa.
Ils ont obtenu les résultats suivants :

Nous observons une amélioration des performances à l’exception des repères SQuAD (qui sont basés sur Wikipédia et sont donc affectés négativement par les données d’entraînement hors domaine).
Visuellement, cet ajout de données est observable sur la phase d’entraînement :
4.3 L’impact du dropout
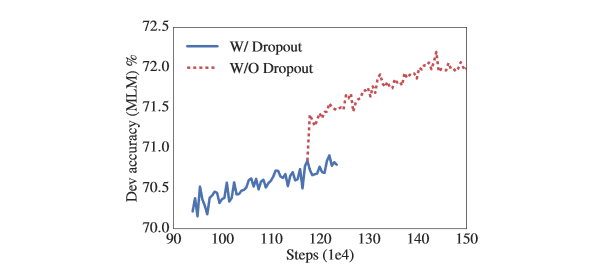
Les auteurs ont constaté que même après un entraînement de 1 million d’étapes, leurs plus grands modèles ne se sont toujours pas adaptés à leurs données d’entraînement.
Ils ont alors décidé de supprimer le dropout afin d’augmenter la capacité des modèles. Le graphique ci-dessous montre que la suppression du dropout améliore considérablement la précision du MLM.

Cela s’observe également lors des applications aux différentes bases de données :
Il existe des preuves empiriques (Szegedy et al., 2017) et théoriques (Liet al., 2019) montrant qu’une combinaison de batch normalization et de dropout peut avoir des résultats néfastes sur les réseaux de neurones convolutifs.
À la connaissance des auteurs d’ALBERT, il s’agit des premiers à montrer que le dropout peut nuire aux performances des grands modèles basés sur des transformers. Cependant, la structure du réseau sous-jacent d’ALBERT est un cas particulier de transformer et des expériences supplémentaires sont nécessaires pour voir si ce phénomène apparaît ou non avec d’autres architectures.
Conclusion
ALBERT-xxlarge a moins de paramètres que BERT-large et obtient des résultats nettement meilleurs.
Néanmoins il est plus coûteux en termes de calcul en raison de sa structure plus large.
Les auteurs indiquent en conclusion de leur publication, qu’ils prévoient de travailler à accélérer l’entraînement et la vitesse d’inférence de leurs modèles avec des méthodes telles que la sparse attention (Child et al.(2019)) et la block attention (Shen et al. (2018)).
Pour ma part, je vous invite à aller lire la publication, notamment les benchmarks dans la partie 4.9 (p.9 et 10) qui sont consacrés à GLUE, SQuAD et RACE et que je n’ai pas abordé dans cet article.
L’appendix de la publication indique est également intéressante puisqu’elle aborde la configuration des hyperparamètres utilisés ainsi que l’impact du nombre de couches sur les résultats.
Références
- Visual Paper Summary: ALBERT (A Lite BERT) de Amit Chaudhary (2020)
- Generating Long Sequences with Sparse Transformers de Child et al. (2019)
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding de Devlin et al. (2018)
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations de Lan et al. (2019)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach de Liu et al. (2019)
- Bi-Directional Block Self-Attention for Fast and Memory-Efficient Sequence Modeling de Shen at al. (2018)
- XLNet: Generalized Autoregressive Pretrainingfor Language Understanding de Yang, Dai et Al. (2019)
Citation
@inproceedings{albert_blog_post,
author = {Loïck BOURDOIS},
title = {Illustration d'ALBERT},
year = {2020},
url = {https://lbourdois.github.io/blog/nlp/ALBERT}
}