Avant-propos
Cet article est une traduction de toute la partie de l’article de Jay Alammar The illustrated BERT, ELMo, and co. (How NLP cracked transfer learning) en lien avec le modèle BERT.
La partie en lien avec le modèle ELMo a été traduite dans un autre article du blog (voir ici).
Merci à lui de m’avoir autorisé à effectuer cette traduction.
Introduction
L’année 2018 a été un point d’inflexion en traitement du langage naturel (NLP). Notre compréhension conceptuelle de la façon de représenter les mots et les phrases d’une manière qui reflète le mieux les significations et les relations sous-jacentes évolue rapidement.
L’une des dernières étapes de ce développement est la parution de BERT (Bidirectional Encoder Representations from Transformers), un événement décrit comme marquant le début d’une nouvelle ère pour le NLP.
BERT est un modèle ayant battu plusieurs records sur des tâches basées sur le langage.
Peu après la publication de l’article, l’équipe a rendu son code public et a mis à disposition des versions du modèle pré-entrainées sur d’énormes ensembles de données.
Il s’agit d’un développement capital car il permet à quiconque qui construit un modèle d’apprentissage machine en NLP d’utiliser ces poids pré-entraînés économisant ainsi le temps, l’énergie, les connaissances et les ressources qui auraient été consacrés à l’entraînement d’un modèle de zéro.
BERT s’appuie sur un certain nombre d’idées qui ont récemment fait leur apparition dans la communauté du NLP, notamment l’apprentissage séquentiel semi-supervisé (par Andrew Dai et Quoc Le), ELMo (par Matthew Peters et des chercheurs de AI2 et UW CSE), ULMFiT (par Fast.ai Jeremy Howard et Sebastian Ruder), le OpenAI transformer (par les chercheurs Radford, Narasimhan, Salimans et Sutskever) et le Transformer (Vaswani et al).
1. Les travaux ayant aboutis aux raisonnements utilisés dans BERT
1.1 Récapitulatif sur l’enchâssement de mots
Pour que les mots soient traités par les modèles d’apprentissage automatique, ils ont besoin d’une représentation numérique. Word2Vec a montré que nous pouvons utiliser un vecteur (une liste de nombres) pour représenter correctement les mots d’une manière capturant les relations sémantiques ou liées au sens. Par exemple la capacité de dire si les mots sont similaires, ou opposés, ou si une paire de mots comme « Stockholm » et « Suède » ont la même relation entre eux que « Le Caire » et « Egypte » ont entre eux. Cela prendre aussi en compte des relations syntaxiques, ou grammaticales (par exemple, la relation entre « avait » et « a » est la même que celle entre « était » et « est »).
La pratique a fait émergée la pertinence et l’utilité d’utiliser des enchâssements pré-entrainés sur de grandes quantités de données textuelles au lieu de les entraîner avec le modèle sur un petit jeu de données. Il est donc devenu possible de télécharger une liste de mots et leurs enchâssements générées par le pré-entraînement avec Word2Vec ou GloVe. Voici un exemple de l’enchâssement de GloVe pour le mot « stick » (avec une taille de vecteur de 200) :

Puisqu’ils sont longs et pleins de nombres, nous utiliserons dans la suite de l’article, la forme suivante dans les figures afin d’illustrer les vecteurs :

Pour plus de détails, voir l’article du blog dédié au word embedding
1.2 ELMo (l’importance du contexte)
Pour plus de détails, voir l’article du blog dédié à ELMo.
1.3 ULM-FiT
ULM-FiT a introduit des méthodes permettant d’utiliser efficacement une grande partie de ce que le modèle apprend au cours du pré-entrainement (plus que de simples enchâssements et plus que des enchâssements contextualisés). ULM-FiT est ainsi un moyen de transférer l’apprentissage probablement aussi bien que ce qui se faisait alors en vision par ordinateur.
1.4 Le transformer (aller au-delà des LSTMs)
La publication de l’article et du code sur le transformer, mais surtout les résultats obtenus sur des tâches telles que la traduction automatique l’ont fait émerger comme un substitut aux LSTMs.
Cette situation s’est accentuée du fait que que les transformers traitent mieux les dépendances à long terme que les LSTMs.
Pour plus de détails, voir l’article du blog dédié au Transformer
La structure encodeur-décodeur du transformer le rend très efficace pour la traduction automatique.
Mais comment l’utilisez pour la classification de phrases ?
Plus généralement comment finetuner sur d’autres tâches un modèle linguistique pré-entrainé ?
1.5 L’Open AI Transformer : le GPT-1
Il s’avère que nous n’avons pas besoin d’un transformer complet pour adopter l’apprentissage par transfert dans le cadre de taches de NLP. Nous pouvons nous contenter de la partie decodeur du transformer. Le décodeur est un bon choix car naturel pour la modélisation du langage (prédire le mot suivant). En effet il est construit en masqueant les tokens futurs, ce qui est une fonction précieuse pour générer une traduction mot à mot.
Le modèle empile douze couches décodeur. Puisqu’il n’y a pas d’encodeur, les couches décodeur n’ont pas la sous-couche d’attention encodeur-décodeur comme dans le transformer classique. Ils ont cependant toujours la couche d’auto-attention.
Avec cette structure, nous pouvons procéder à l’entraînement du modèle sur la même tâche de modélisation du langage : prédire le mot suivant en utilisant un jeu de données massif (sans label). L’entraînement est réalisé sur 7 000 livres car ils permettent au modèle d’apprendre à associer des informations connexes même si elles sont séparées par beaucoup de texte. C’est quelque chose que vous n’obtenez pas, par exemple, lorsque vous effectuez un entraînement avec des tweets ou des articles.
Maintenant que le GPT est pré-entrainé et que ses couches ont été ajustées pour gérer raisonnablement le langage, nous pouvons commencer à l’utiliser pour des tâches plus spécialisées. L’article d’OpenAI décrit la structure à adopter différentes tâches :
La version 2 du GPT est présentée dans un article du blog qui lui est dédié : Illustration du GPT-2
2. BERT : du décodeur à l’encodeur
Le GPT est un modèle pré-entraîné basé sur le transformer. Cependant il manque quelque chose dans cette transition entre les LSTMs le transformer.
Le modèle linguistique d’ELMo est bidirectionnel alor que le GPT n’entraîne qu’un modèle linguistique prédictif. Pourrions-nous construire un modèle basé sur un transformer dont le modèle linguistique regarde à la fois vers l’avant et vers l’arrière (c’est-à-dire conditionné à la fois par le contexte gauche et droit) ? BERT a été conçu pour réaliser cela !
2.1 Architecture du modèle
L’article original présente deux tailles de modèles pour BERT :
- BERT BASE de taille comparable à celle du GPT afin de comparer les performances.
- BERT LARGE, un modèle beaucoup plus grand qui a atteint l’état de l’art dans les résultats rapportés dans l’article.
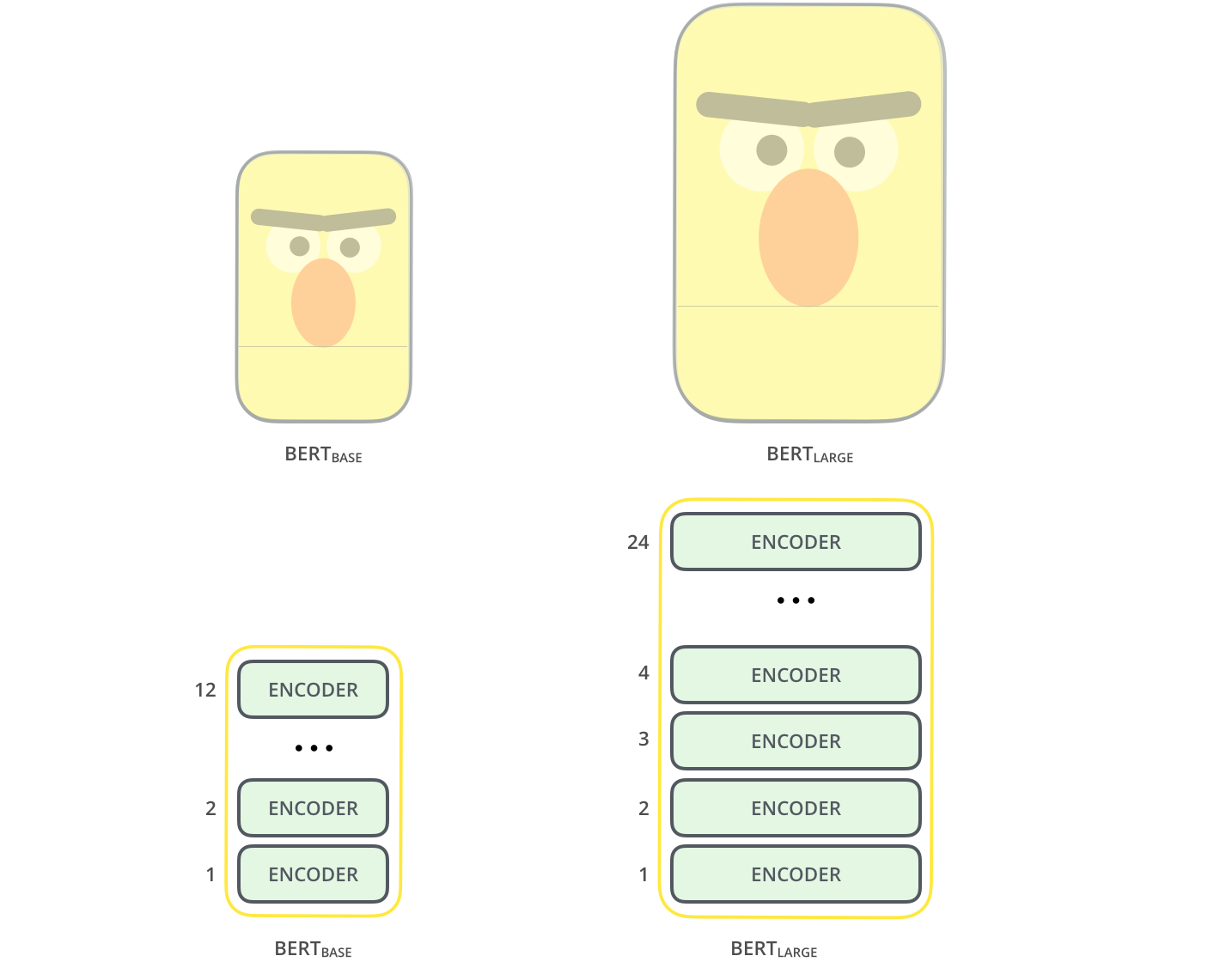
Les deux modèles BERT ont un grand nombre de couches d’encodeurs (appellées Transformer Block dans l’article d’origine) : douze pour la version de base et vingt-quatre pour la version large. Ils ont également des réseaux feed-forward plus grands (768 et 1024 unités cachées respectivement) et plus de têtes d’attention (12 et 16 respectivement) que la configuration par défaut dans l’implémentation initial du Transformer de Vaswani et al. (6 couches de codeurs, 512 unités cachées, et 8 têtes d’attention).
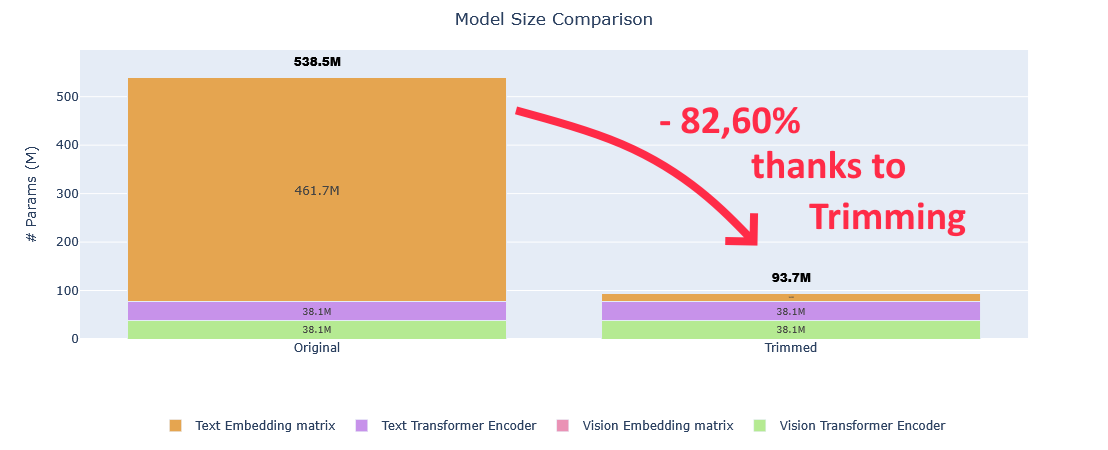
Depuis d’autres tailles de modèles ont été créé pour BERT, allant de 4.4 millions de paramètres pour le BERT-Tiny (utilisable sur un CPU), à 1270M pour le XLarge. Un tableau récapitulatif des modèles plus petits que le BERT Base :
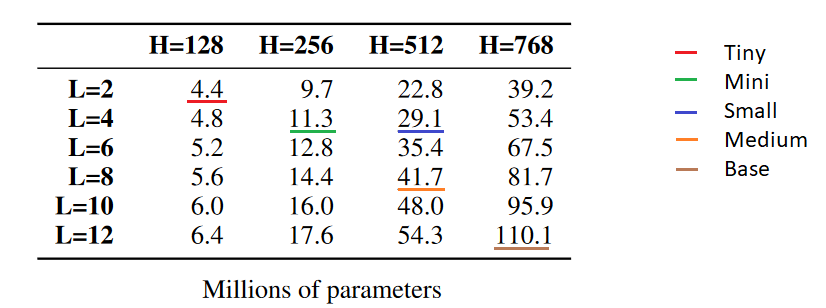
Tableau issu de la publication de Iulia Turc et al.
2.2 Entrées du modèle
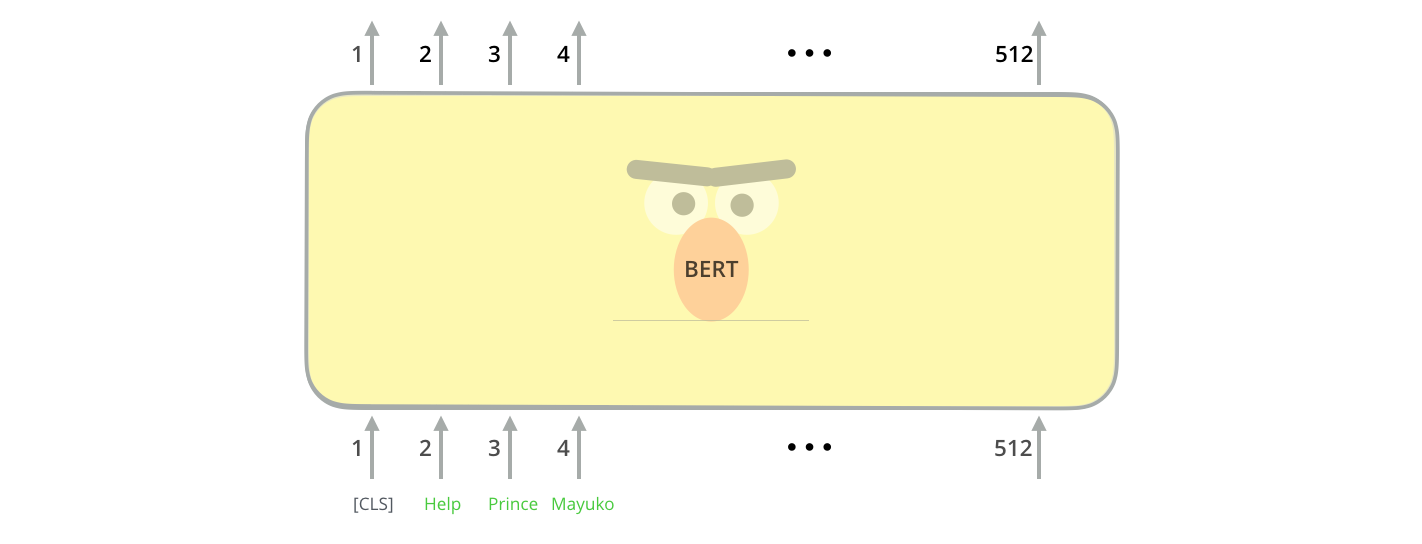
Le premier token d’entrée est un jeton spécial [CLS] pour des raisons qui apparaîtront plus tard. CLS est ici l’abréviation de classification.
Tout comme l’encodeur du transformer, BERT prend une séquence de mots en entrée qui remonte dans la pile. Chaque couche applique l’auto-attention et transmet ses résultats à un réseau feed-forward, puis les transmet à l’encodeur suivant.
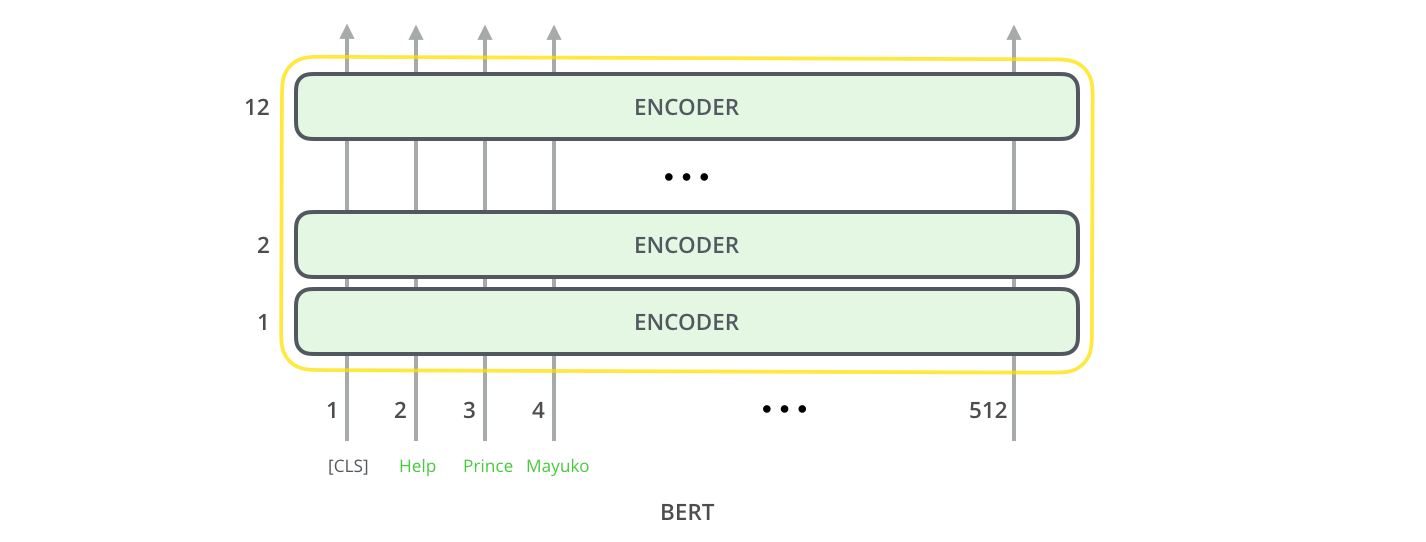
L’architecture est identique au transformer jusqu’à présent (à part la taille qui est une configuration que nous pouvons définir).
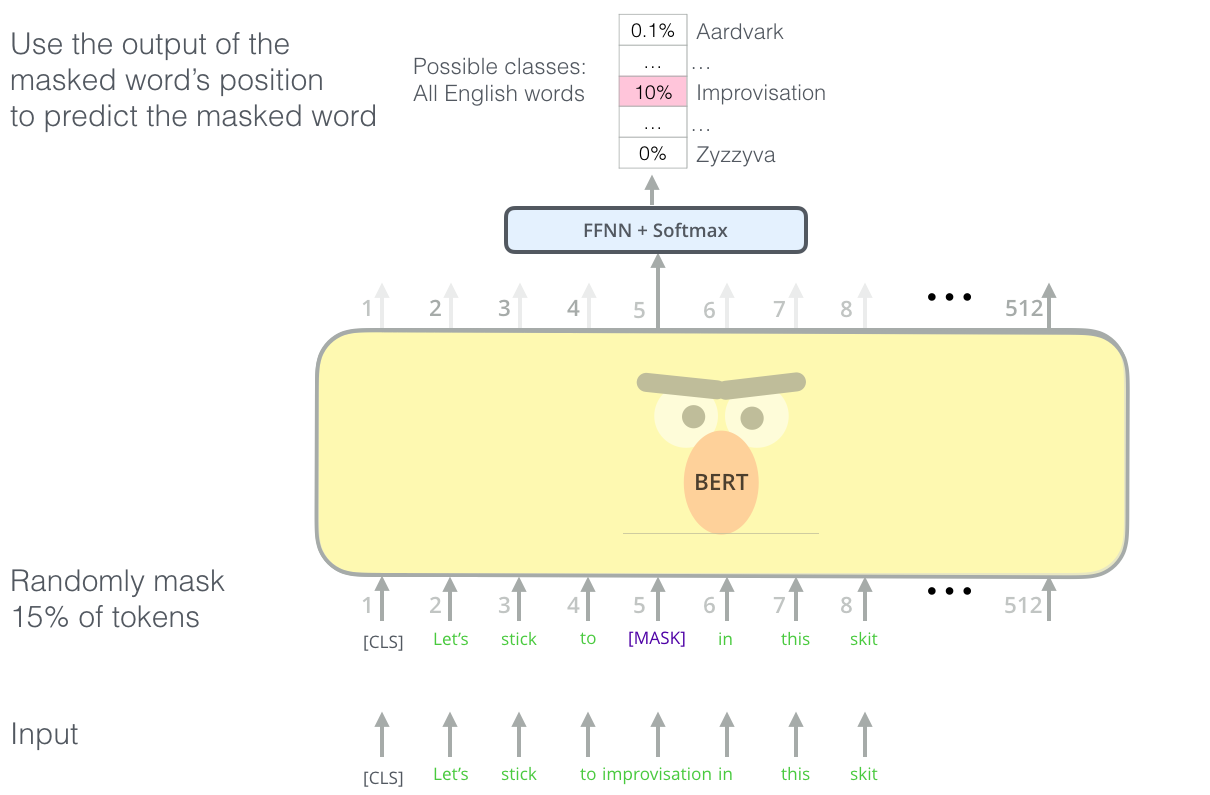
Trouver la bonne manière d’entraîner une pile d’encodeurs est un obstacle complexe que BERT résout en adoptant un concept de « modèle de langage masqué » (Masked LM en anglais) tiré de la littérature antérieure (il s’agit d’une Cloze task). Cette procédure consiste à prendre aléatoirement 15% des tokens en entrée puis à masquer 80% d’entre eux, en remplacer 10% par un autre token complètement aléatoire et de ne rien faire dans le cas des 10% restant. L’objectif est que le modèle prédise correctement le token original modifié (via la perte d’entropie croisée). Le modèle est donc obligé de conserver une représentation contextuelle distributionnelle de chaque jeton d’entrée.
Afin d’améliorer BERT dans la gestion des relations existant entre plusieurs phrases, le processus de pré-entraînement comprend une tâche supplémentaire : étant donné deux phrases (A et B), B est-il susceptible d’être la phrase qui suit A, ou non ?

La deuxième tâche sur laquelle BERT est pré-entraîné est une tâche de classification. La tokenisation est simplifiée à l’extrême dans ce graphique car BERT utilise en fait wordpiece comme tokens plutôt que des mots. Ainsi certains mots sont décomposés en plus petits morceaux. Vous pouvez lire cet article du blog sur la tokenisation pour plus de détails.
2.3 Sorties du modèle
Chaque position fournit un vecteur de taille hidden_size (768 dans BERT Base). Pour l’exemple de classification des phrases que nous avons examiné ci-dessus, nous nous concentrons uniquement sur la sortie de la première position (à laquelle nous avons passé le jeton spécial [CLS]).
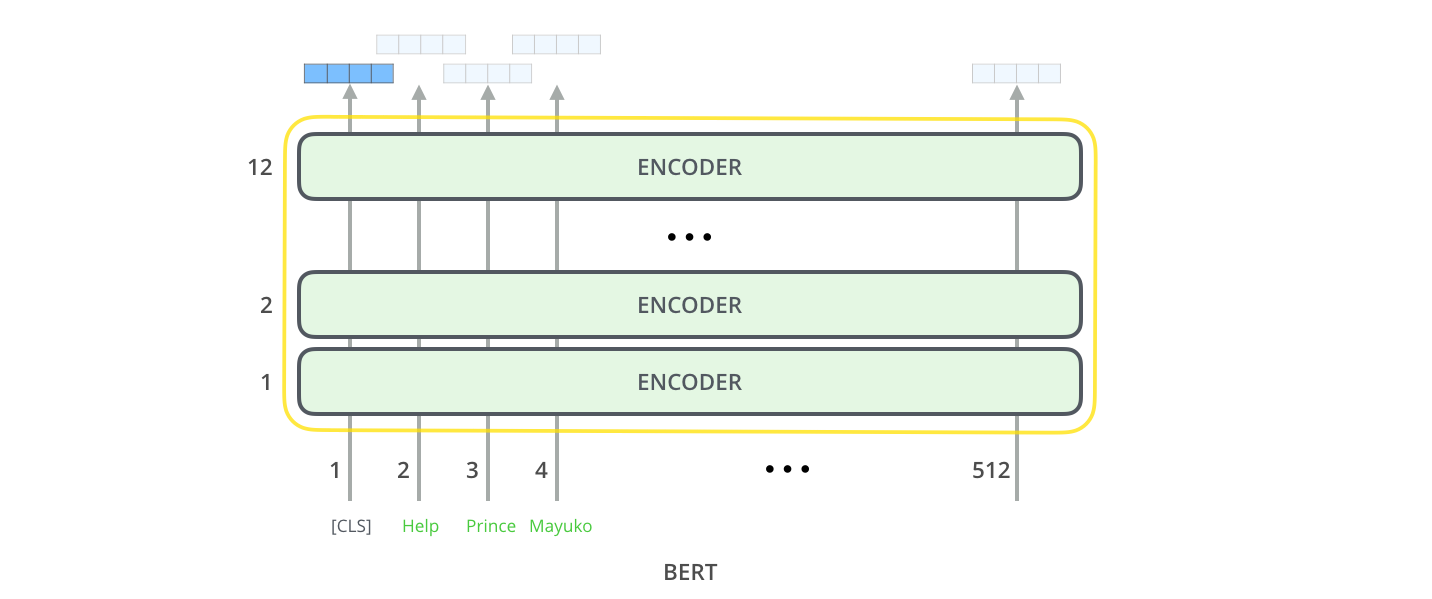
Ce vecteur peut maintenant être utilisé comme entrée pour un classifieur de notre choix. L’article obtient d’excellents résultats en utilisant simplement un réseau neuronal à une seule couche comme classifieur.
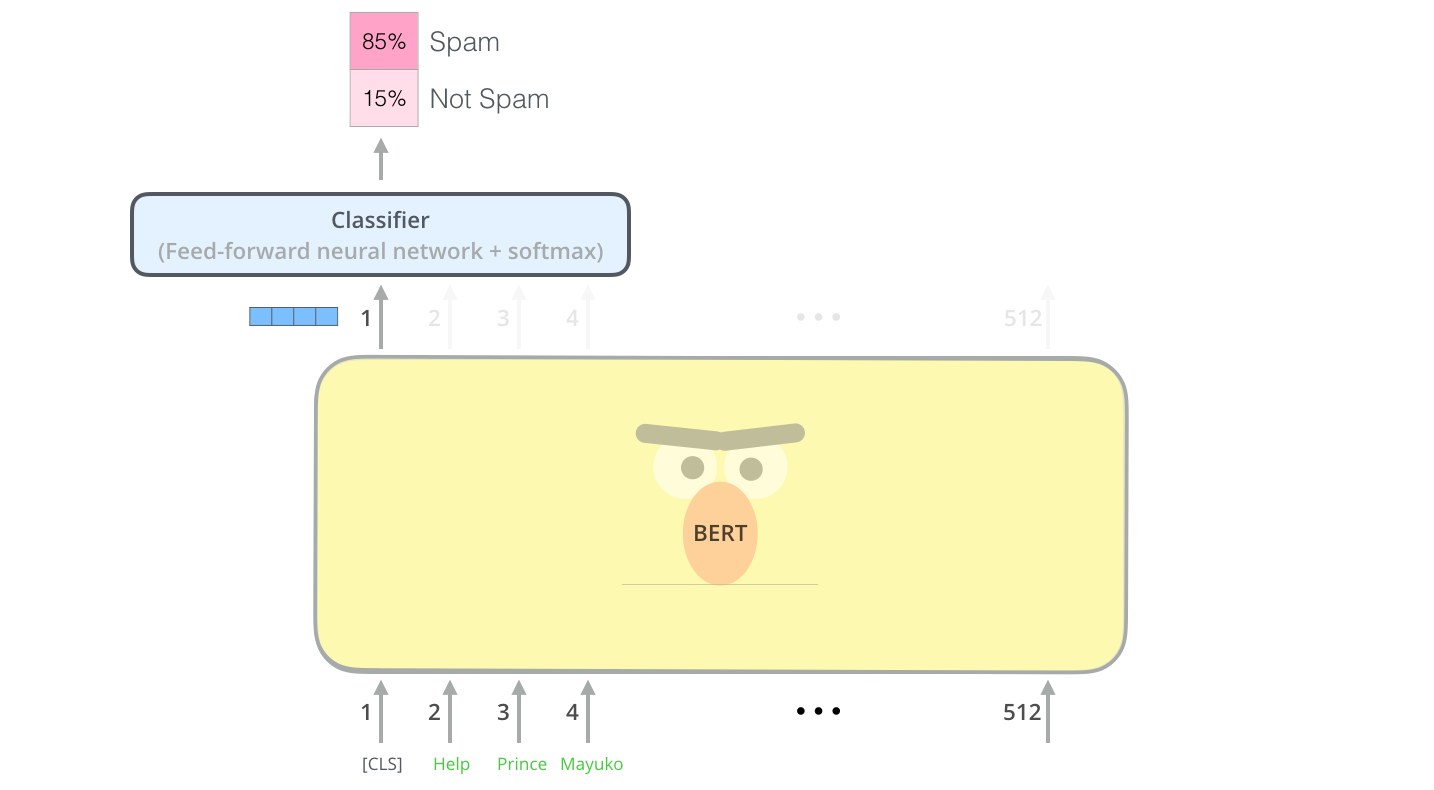
Si vous avez plus de labels (par exemple si vous êtes un service de messagerie qui marque les e-mails avec « spam », « not spam », « social » et « promotion »), vous n’avez qu’à modifier le réseau du classifieur pour avoir plus de neurones de sortie qui passent ensuite par la couche softmax.
2.4 Modèles spécifiques à une tâche
A la page 7 de leur publication, les auteurs de BERT précisent les approches de finetuning appliquées pour quatre tâches de NLP différentes. Dans les quatre figures suivantes, \(E\) représente l’enchâssement d’entrée, \(T_i\) représente la représentation contextuelle du token, \([CLS]\) est le symbole spécial pour la sortie de la classification, et \([SEP]\) est le symbole spécial pour séparer les séquences de tokens non consécutives.
2.4.1 La classification
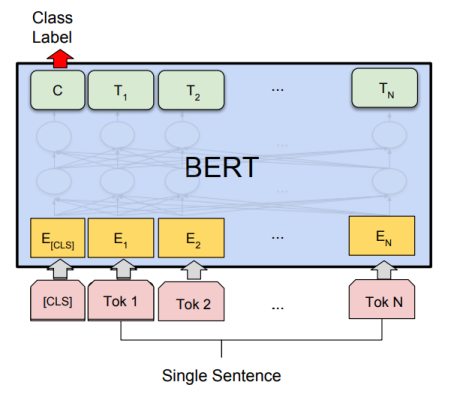
Applicable par exemple sur les jeux de données SST-2 ou CoLA. Ces jeux de données sont décrits dans l’article Taches et jeux de données test fréquemment utilisés dans les publications de NLP du blog.
2.4.2 Tests de logique
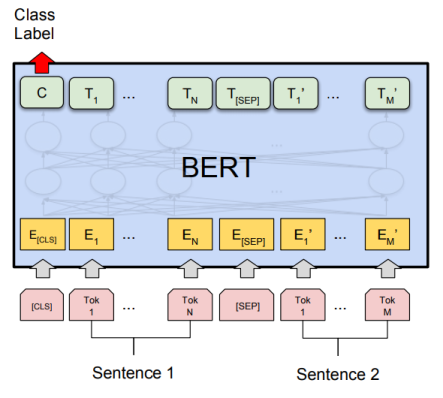
Applicable par exemple sur les jeux de données MNLI, RTE ou SWAG. Ces jeux de données sont décrits dans l’article Taches et jeux de données test fréquemment utilisés dans les publications de NLP du blog.
2.4.3 Le Question-Answering
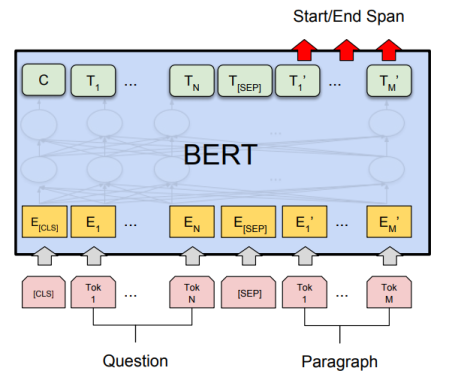
Applicable par exemple sur le jeu de données SQUAD. Ces jeux de données sont décrits dans l’article Taches et jeux de données test fréquemment utilisés dans les publications de NLP du blog.
2.4.4 Reconnaissance d’entités nommées
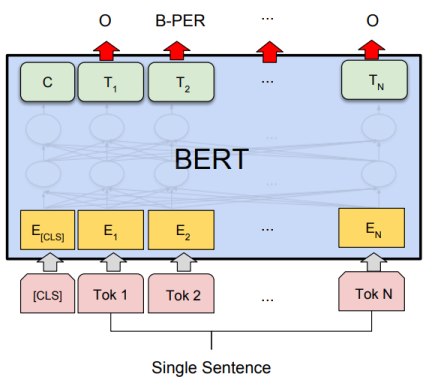
Applicable par exemple sur le jeu de données CoNLL-2003 NER. Ces jeux de données sont décrits dans l’article Taches et jeux de données test fréquemment utilisés dans les publications de NLP du blog.
2.5 BERT pour l’extraction de caractéristiques
L’approche via finetuning n’est pas l’unique manière d’utiliser BERT. Tout comme ELMo, vous pouvez utiliser un BERT pré-entrainé pour créer des enchâssements de mots contextualisés. Vous pouvez ensuite intégrer ces enchâssements à votre modèle existant.
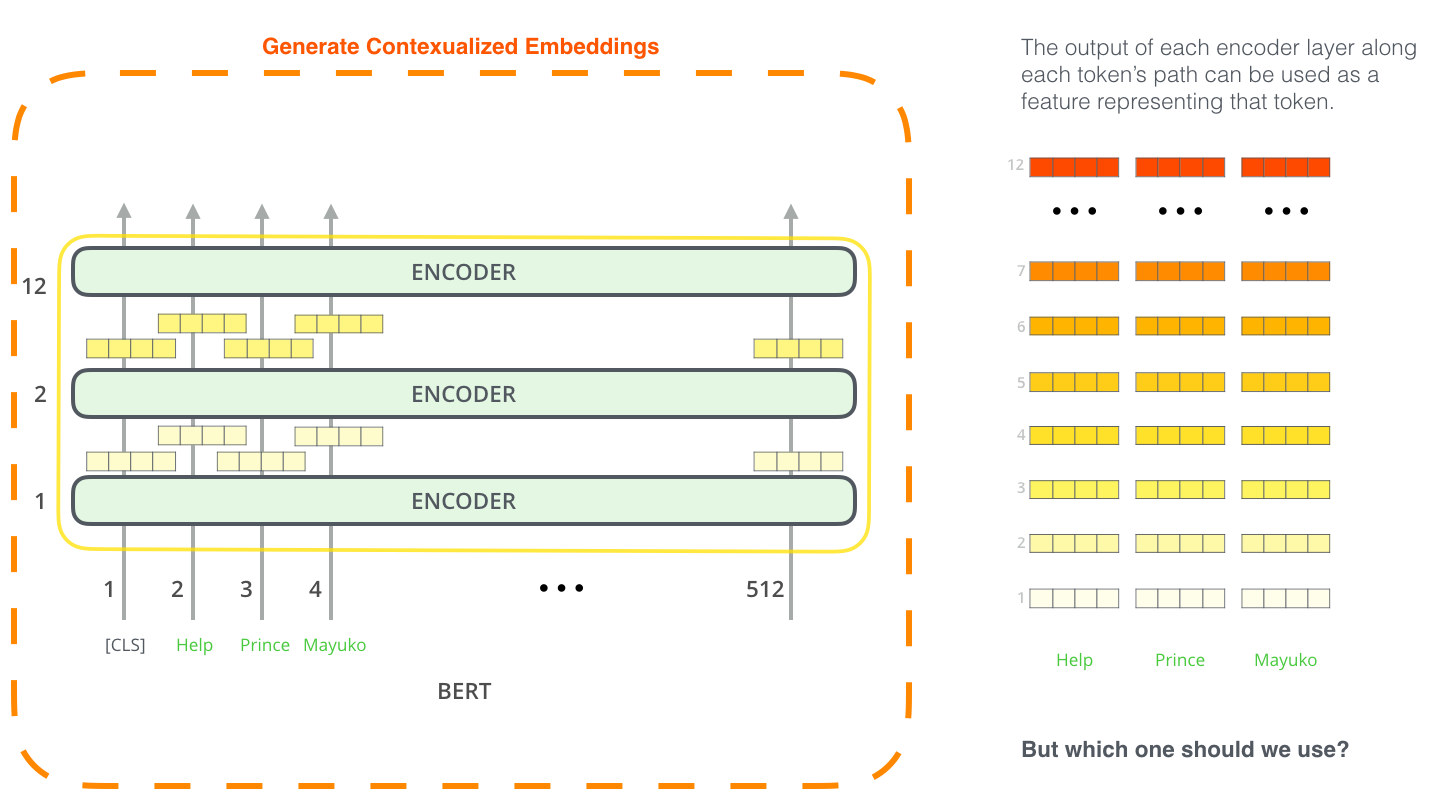
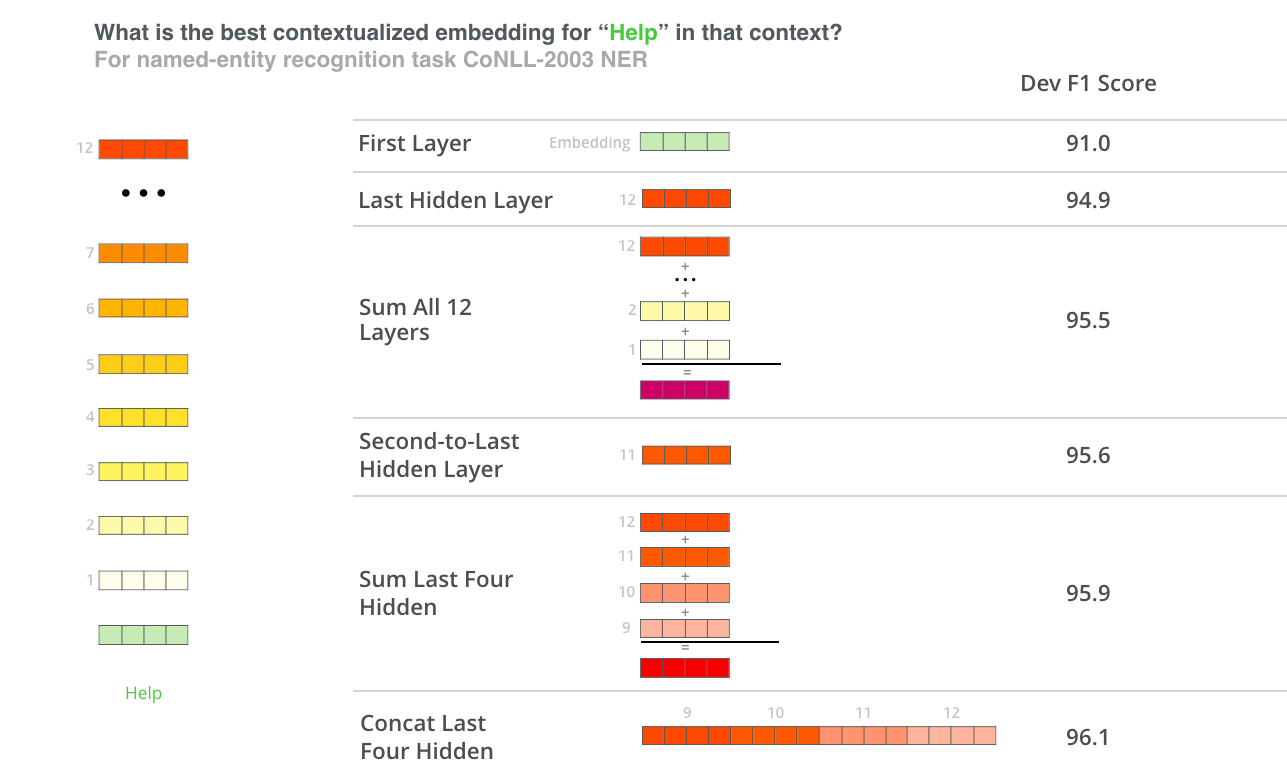
Quel vecteur fonctionne le mieux comme enchâssement contextualisé ? Cela dépend de la tâche. L’article examine six choix (par rapport au modèle finetuné ayant obtenu un F1-score de 96,4) :
2.6 Tester BERT
La meilleure façon d’essayer BERT est d’utiliser sur Google Colab le notebook BERT FineTuning with Cloud TPUs. Si vous n’avez jamais utilisé de TPU Cloud auparavant, c’est aussi un bon point de départ pour les essayer.
L’étape suivante consisterait à examiner plus en détails le code contenu sur le GitHub de la publication de BERT :
- Le modèle est construit dans modeling.py (
class BertModel) et est pratiquement identique à un encodeur du transformer de base. - run_classifier.py est un exemple du processus de finetuning. Il construit également la couche de classification pour le modèle supervisé. Si vous voulez construire votre propre classifieur, vérifiez la méthode
create_model()dans ce fichier. - Plusieurs modèles pré-entraînés sont disponibles en téléchargement pour BERT Base et BERT Large : pour l’anglais, le chinois et un modèle multilingue couvrant 102 langues entraînés sur Wikipedia.
Pour le français, vous pouvez consulter le modèle FlauBERT développé par une équipe composée des Universités de Grenoble, de Paris Diderot et par le CNRS. Il s’agit de BERT pré-entraîné sur un vocabulaire en français.
Vous pouvez aussi voir le modèle CamemBERT développé par l’Inria et Facebook (le modèle appliqué est roBERTa qui est une version optimisée de BERT) - BERT ne considère pas les mots comme des tokens. Il regarde plutôt les wordpieces (par exemple : playing donne play + ##ing). tokenization.py est le tokenizer qui transforme vos mots en wordPieces appropriés pour BERT.
Un article sur les différents tokenizers utilisés dans la littérature scientifique est disponible sur le blog : ici
Conclusion
J’espère que cette présentation vous aura permis de comprendre les idées principales du modèle BERT.
Les auteurs de BERT réalise une comparaison avec ELMo et le GPT dans l’appendix de leur article.
Cette appendix permet aussi de savoir comment est paramétrée chacune des étapes (le learning rate d’Adam utilisé, le nombre d’époque appliqué, la taille des batchs, etc.).
Références
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) de Jay Alammar (2018)
- Semi-supervised Sequence Learning de Dai et al. (2015)
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding de Devlin et al. (2018)
- Universal Language Model Fine-tuning for Text Classification de Howard et Ruder (2018)
- FlauBERT: Unsupervised Language Model Pre-training for French de Le et al. (2019)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach de Liu et al. (2019)
- CamemBERT: a Tasty French Language Model de Martin et al. (2019)
- Deep contextualized word representations de Peters et al. (2018)
- Improving Language Understandingby Generative Pre-Training de Radford et al. (2018)
- Well-Read Students Learn Better: On the Importance of Pre-training Compact Models de Turc et al. (2019)
- Attention Is All You Need de Vaswani et al. (2017)
Citation
@inproceedings{bert_blog_post,
author = {Loïck BOURDOIS},
title = {Illustration de BERT},
year = {2019},
url = {https://lbourdois.github.io/blog/nlp/BERT/}
}