Avant-propos
Cet article est une traduction de l’article de Jay Alammar : The illustrated GPT-2 (Visualizing transformer language model).
Merci à lui de m’avoir autorisé à effectuer cette traduction.
Introduction
Cette année (2019), le GPT-2 (Generative Pretrained Transformer 2) de Radford et al. a fait preuve d’une impressionnante capacité à rédiger des essais cohérents et passionnés dépassant ce qui était envisageable avec les modèles linguistiques jusqu’ici à notre disposition. Le GPT-2 n’est pas une architecture particulièrement nouvelle (le GTP-2 étant la version 2 du GPT dévoilé en juin 2018 par Radford et al.), elle est très similaire à celle du decodeur du Transformer de Vaswani et al. Le GPT-2 est cependant basé sur un transformer entraîné sur un corpus massif de données. Dans cet article, nous allons nous intéresser à l’architecture qui a permis au modèle de produire ces résultats.
Le but ici est également de compléter l’article sur les transformer avec plus de visuels expliquant leur fonctionnement interne et comment ils ont évolué depuis l’article original.
1. GPT-2 et modélisation du langage
1.1 Qu’est-ce qu’un modèle linguistique ?
Dans la partie 4 de l’article sur le word embedding, nous avons examiné ce qu’est un modèle linguistique. Essentiellement un modèle d’apprentissage automatique qui est capable de regarder une partie d’une phrase et de prédire le mot suivant. Les modèles les plus connus sont les claviers de smartphones qui suggèrent le mot suivant en fonction de ce que vous avez déjà tapé.
En ce sens, nous pouvons dire que le GPT-2 est fondamentalement une fonction de prédiction de mots d’une application de clavier mais qui est beaucoup plus sophistiqué que ce que votre téléphone a. Le GPT-2 a été entraîné sur un énorme jeu de données de 40 Go appelé WebText que les chercheurs d’OpenAI ont trouvé sur internet. Pour comparer en termes de taille de stockage, l’application clavier que j’utilise, SwiftKey, occupe 78MBs d’espace. La plus petite variante du GPT-2 occupe 500MBs de stockage pour stocker tous ses paramètres. La plus grande variante de GPT-2 est 13 fois plus grande, prenant ainsi plus de 6,5 Go d’espace de stockage.

Une excellente façon d’expérimenter le GPT-2 est d’utiliser Write with Transformer d’Hugging face qui affiche dix prédictions possibles pour le mot suivant (avec leur score de probabilité).
Vous pouvez sélectionner un mot puis voir la liste suivante des prédictions pour continuer à écrire votre extrait.
1.2 Transformers pour la modélisation du langage
Comme nous l’avons vu dans l’article sur le Transformer, le transformer basique est composé d’un encodeur et d’un décodeur (chacun est une pile de ce que nous pouvons appeler des « transformer blocks »). Cette architecture est appropriée pour la traduction automatique, un problème où les architectures encodeur-décodeur ont connu du succès dans le passé.
Une grande partie des travaux de recherche apparus depuis a vu l’architecture se débarrasser de l’encodeur ou du décodeur et n’utiliser qu’une seule pile de « transformer blocks ». Empilant les piles aussi haut que possible, leur fournissant des textes en quantité massive pour l’entraînement.
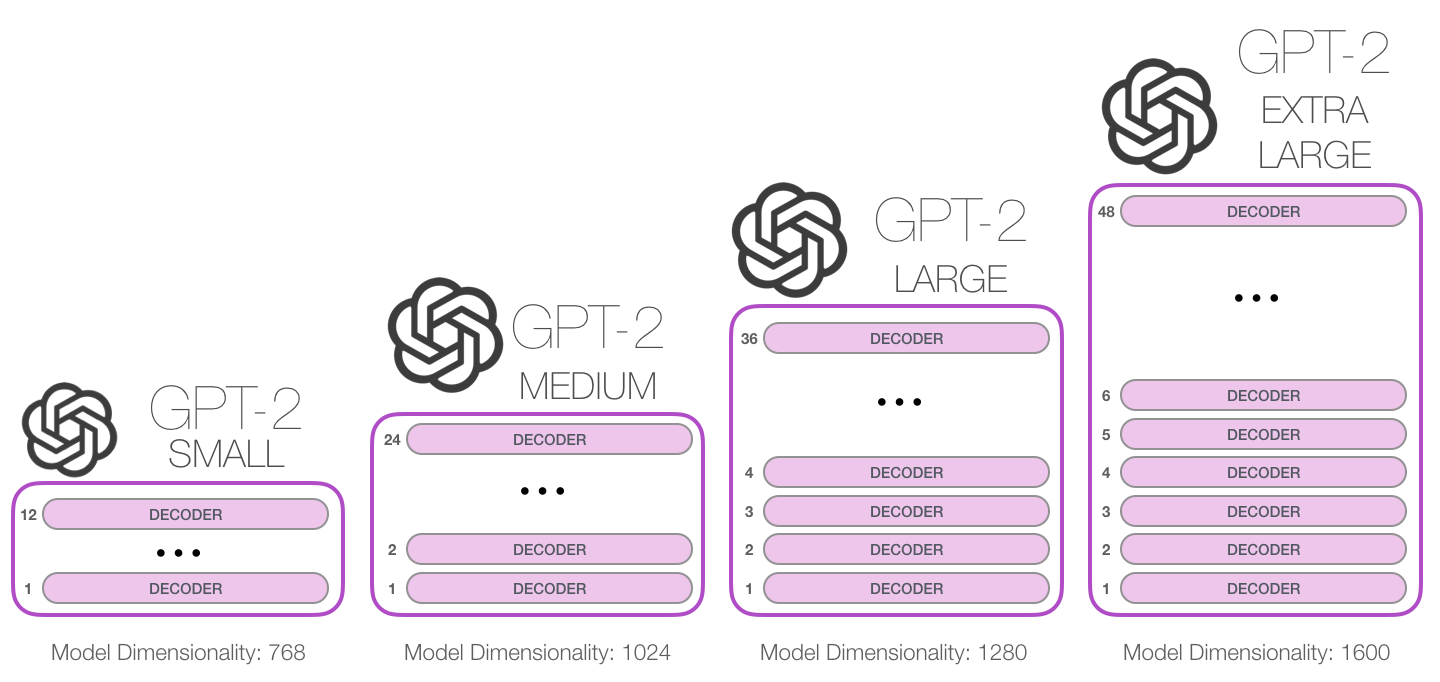
A quelle hauteur peut-on empiler ces blocs ? Il s’avère que c’est l’un des principaux facteurs de distinction entre les différentes tailles de modèles du GPT2 :
1.3 Une différence par rapport à BERT
Le GPT-2 est construit à l’aide de blocs décodeurs. BERT, pour sa part, utilise des blocs d’encodeurs. Nous examinerons la différence dans une section suivante. Mais l’une des principales différences entre les deux est que le GPT-2, comme les modèles de langage traditionnels, produit un seul token à la fois. Invitons par exemple un GPT-2 bien entraîné à réciter la première loi de la robotique : « A robot may not injure a human being or, through inaction, allow a human being to come to harm » (un robot ne peut pas blesser un être humain ou, par son inaction, permettre qu’un être humain soit blessé).
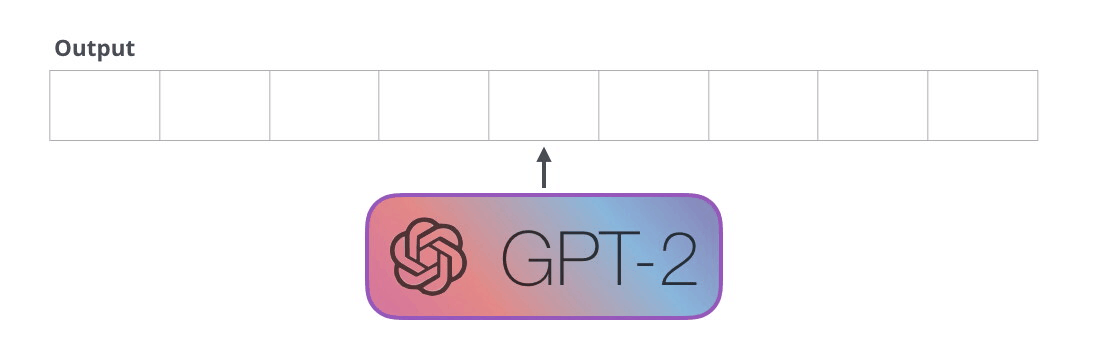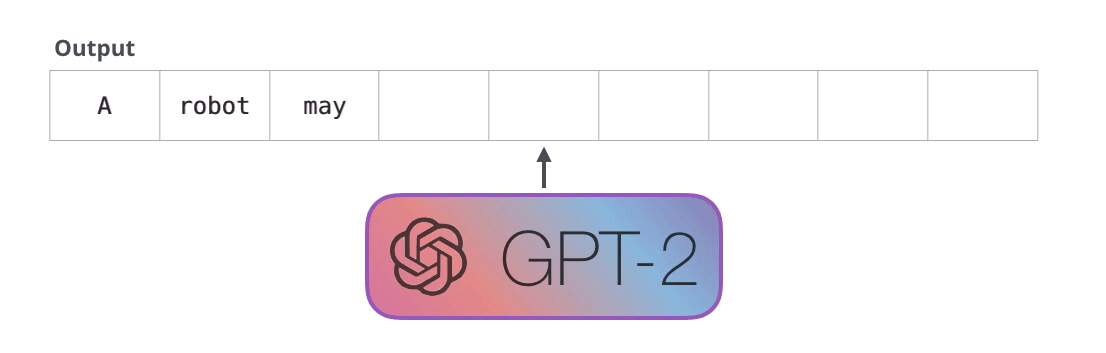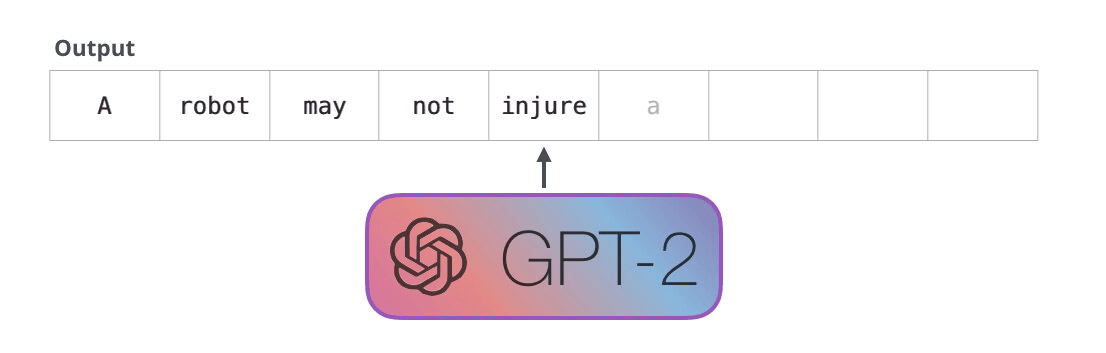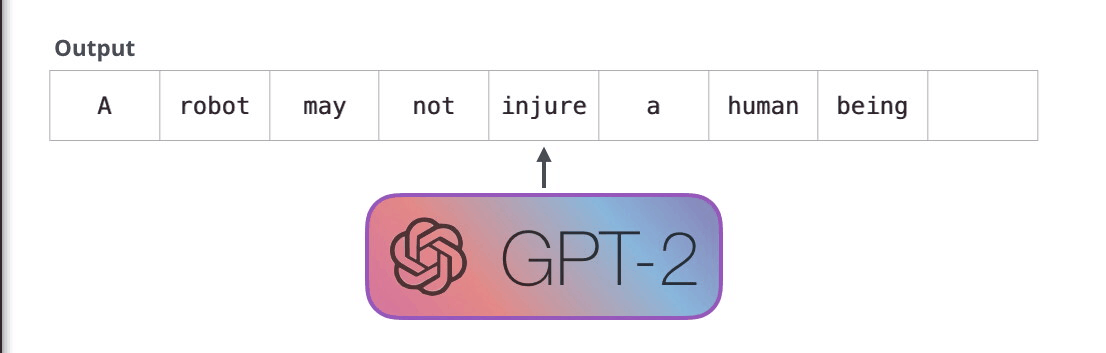
La façon dont fonctionnent réellement ces modèles est qu’après chaque token produit, le token est ajouté à la séquence d’entrée. Cette nouvelle séquence devient l’entrée du modèle pour l’étape suivante. Cette idée est appelée « autorégression » et a permis aux RNNs d’être efficaces.
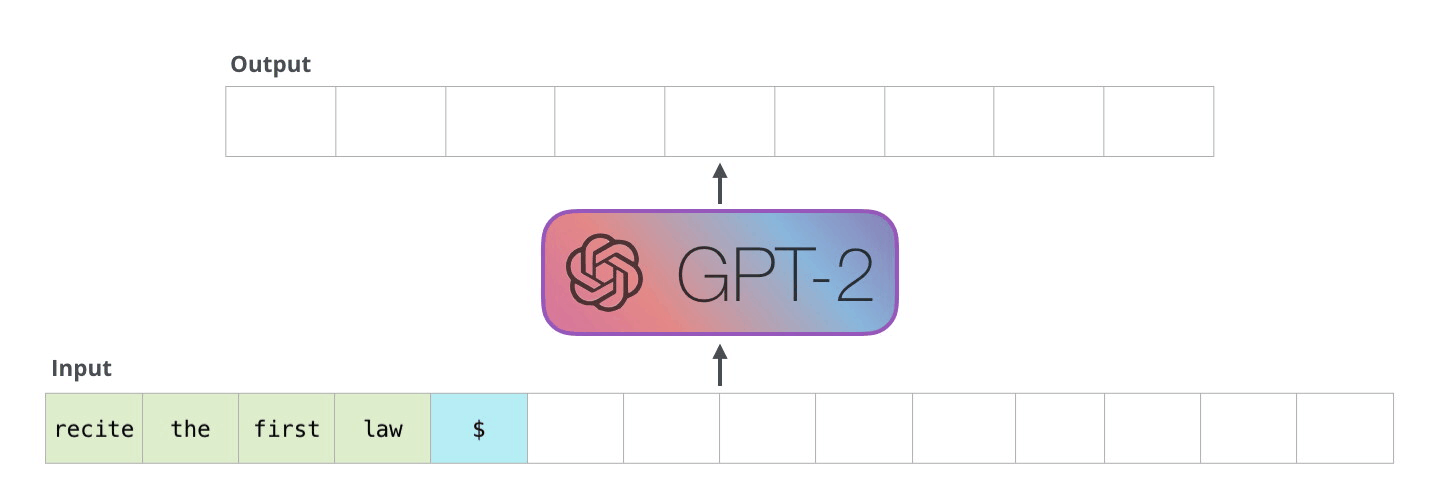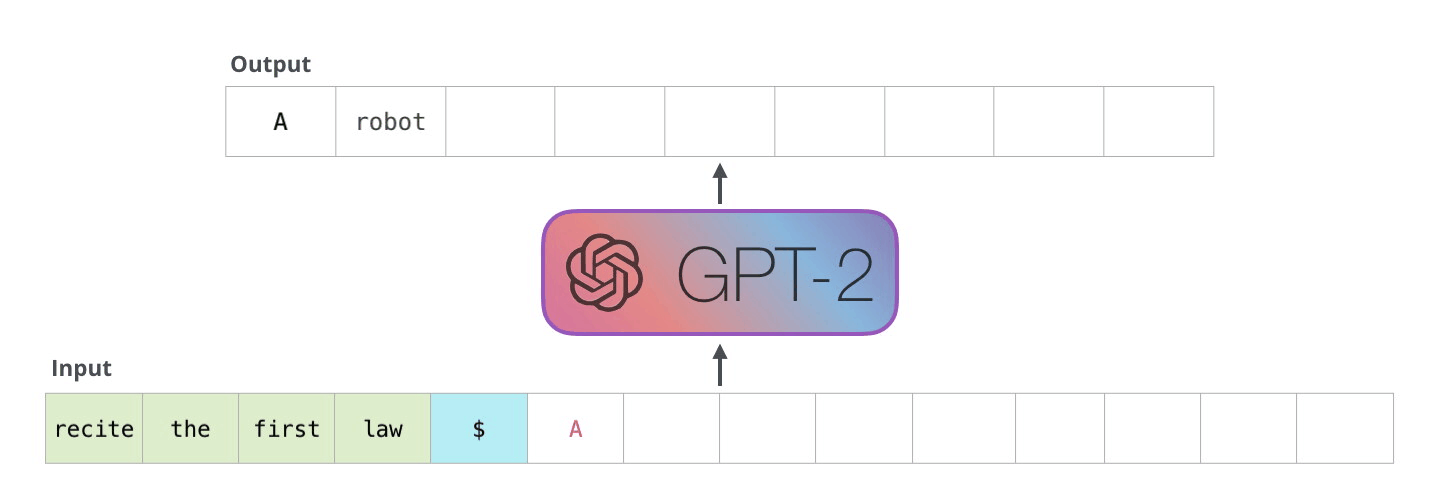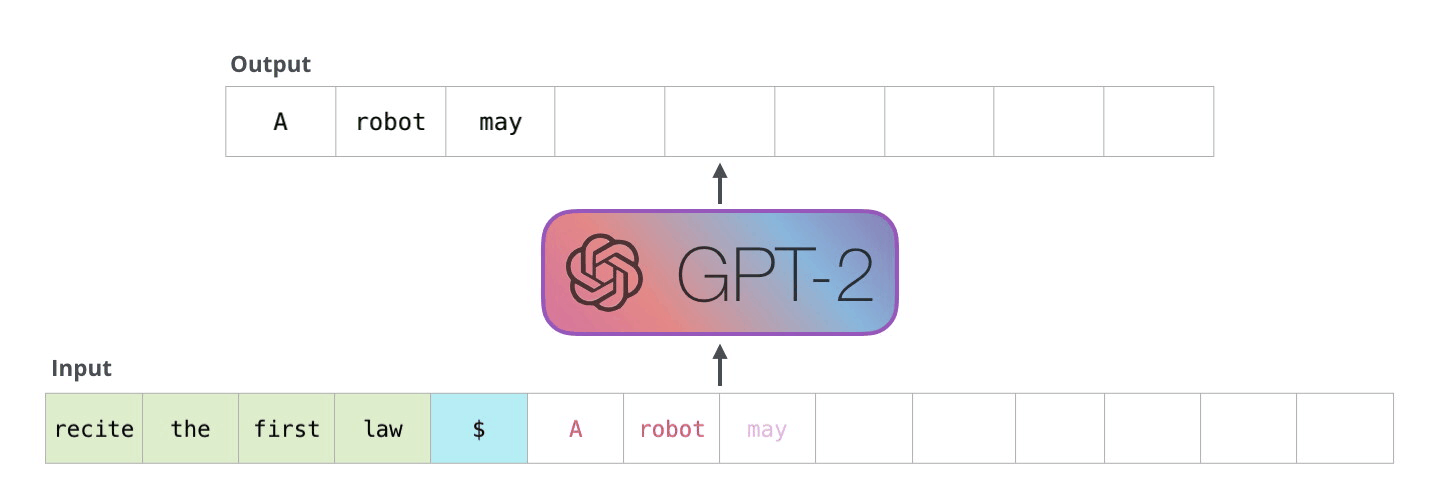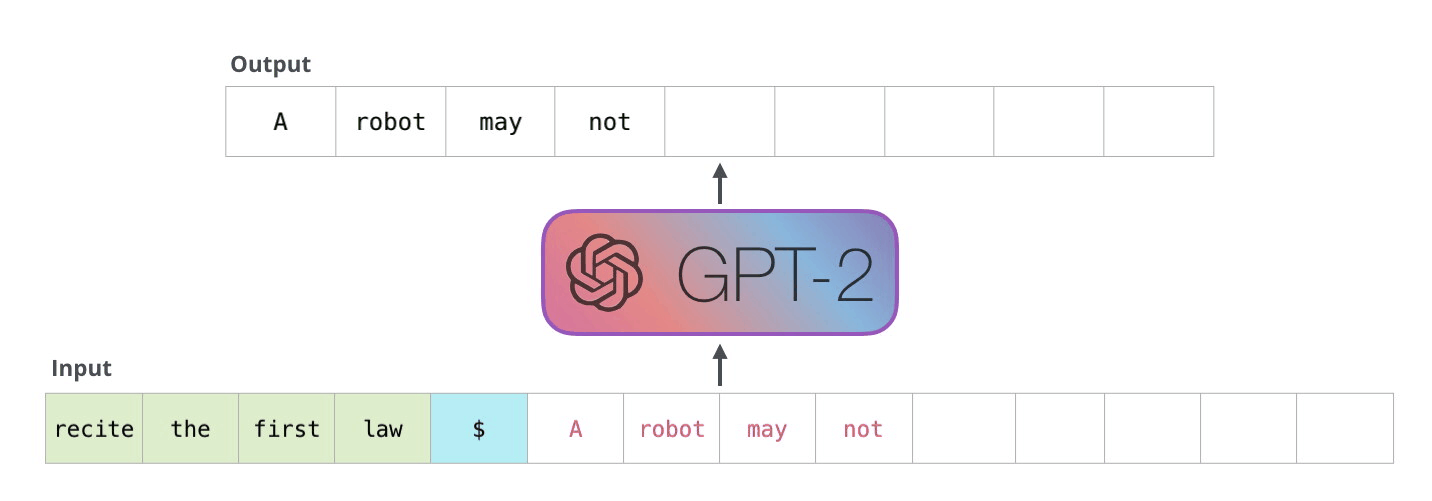
Le GPT2 et certains modèles plus récents comme TransformerXL et XLNet sont de nature autorégressive. BERT ne l’est pas. C’est un compromis. En perdant l’autorégression, BERT a acquis la capacité d’enchâsser le contexte des deux côtés d’un mot pour obtenir de meilleurs résultats. XLNet ramène l’autorégression tout en trouvant une autre façon d’intégrer le contexte des deux côtés.
1.4 L’évolution des blocs du transformer
La publication initiale sur les transformers introduisait deux types de blocs :
1.4.1 Le bloc encodeur
1.4.2 Le bloc décodeur
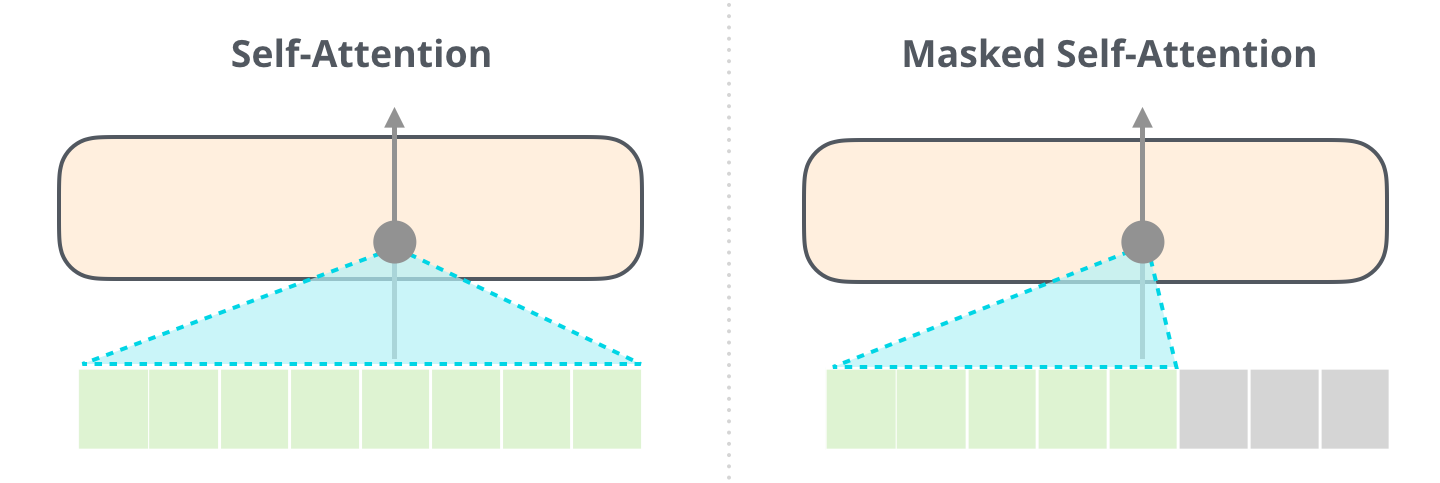
Une différence clé dans la couche d’auto-attention est qu’elle masque les tokens futurs. Non pas en changeant le mot en [mask] comme BERT, mais en interférant dans le calcul de l’auto-attention en bloquant les informations des tokens qui sont à la droite de la position à calculer.
Par exemple, si nous devons mettre en évidence le chemin de la position #4, nous pouvons voir qu’il est seulement permis de regarder le token présent et les précédents :
Il est important que la distinction entre l’auto-attention (ce que BERT utilise) et l’auto-attention masquée (ce que le GPT-2 utilise) soit claire. Un bloc d’auto-attention normal permet à une position d’atteindre le sommet des tokens à sa droite. L’auto-attention masquée empêche que cela se produise :
1.4.3 Que le bloc décodeur
Suite à l’article original, Generating Wikipedia by Summarizing Long Sequences a proposé une autre disposition du transformer qui est capable de faire de la modélisation linguistique. Ce modèle s’est débarrassé de l’encodeur pour ne garder que le décodeur. Pour cette raison, appelons le modèle « Transformer-Décodeur ». Ce premier modèle de langage était constitué d’une pile de six blocs décodeurs :
Ces blocs sont très similaires aux blocs décodeurs d’origine sauf qu’ils suppriment la deuxième couche d’auto-attention. Le GPT-2 d’OpenAI utilise uniquement ces blocs décodeurs.
1.5 L’intérieur du GPT-2
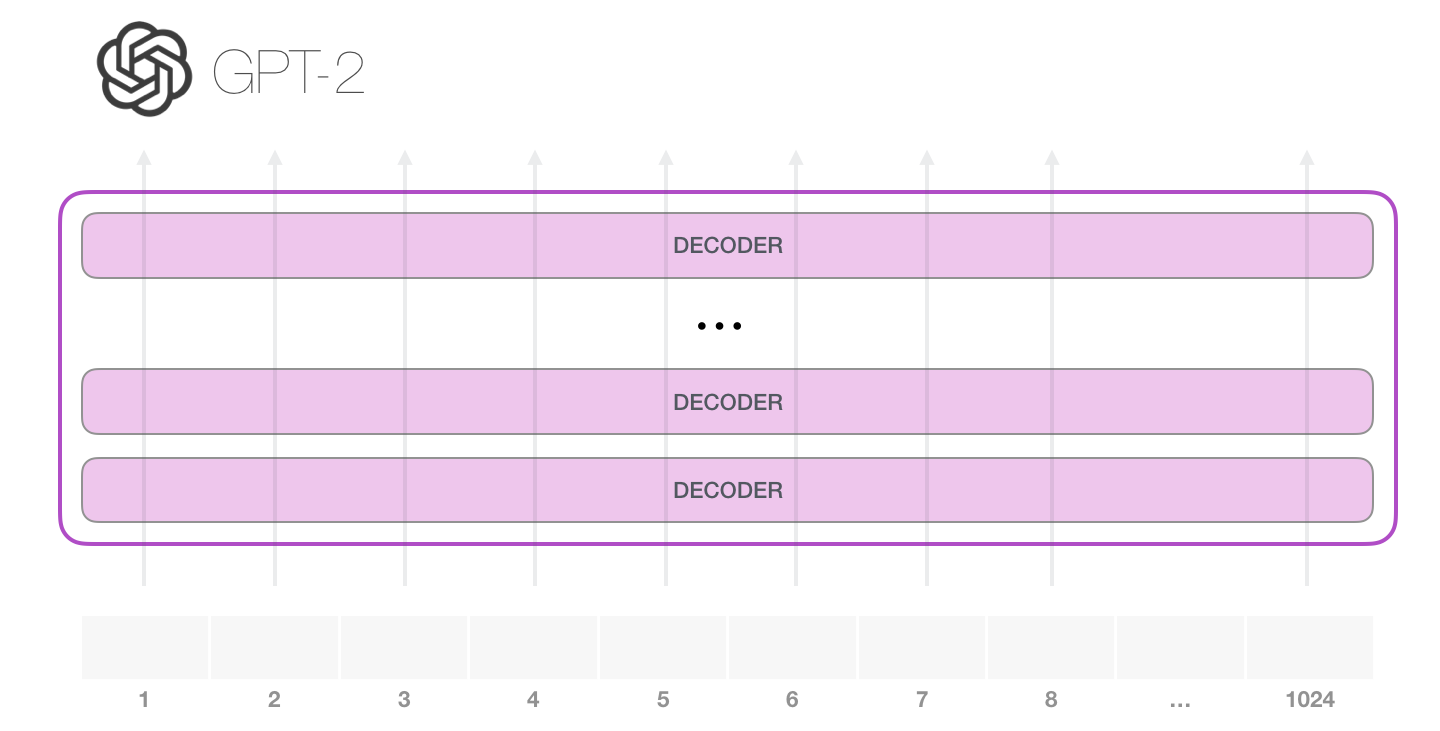
La façon la plus simple d’exécuter un GPT-2 entraîné est de lui permettre de se promener de lui-même (ce qui est techniquement appelé generating unconditional samples). Nous pouvons aussi le pousser à ce qu’il parle d’un certain sujet (generating interactive conditional samples). Dans le premier cas, nous pouvons simplement lui donner le token de démarrage et lui faire commencer à générer des mots. A noter que le GPT2 utilise <|endoftext|> comme token de démarrage. Appelons-le <s> à la place dans la suite afin de simplifier les graphiques.
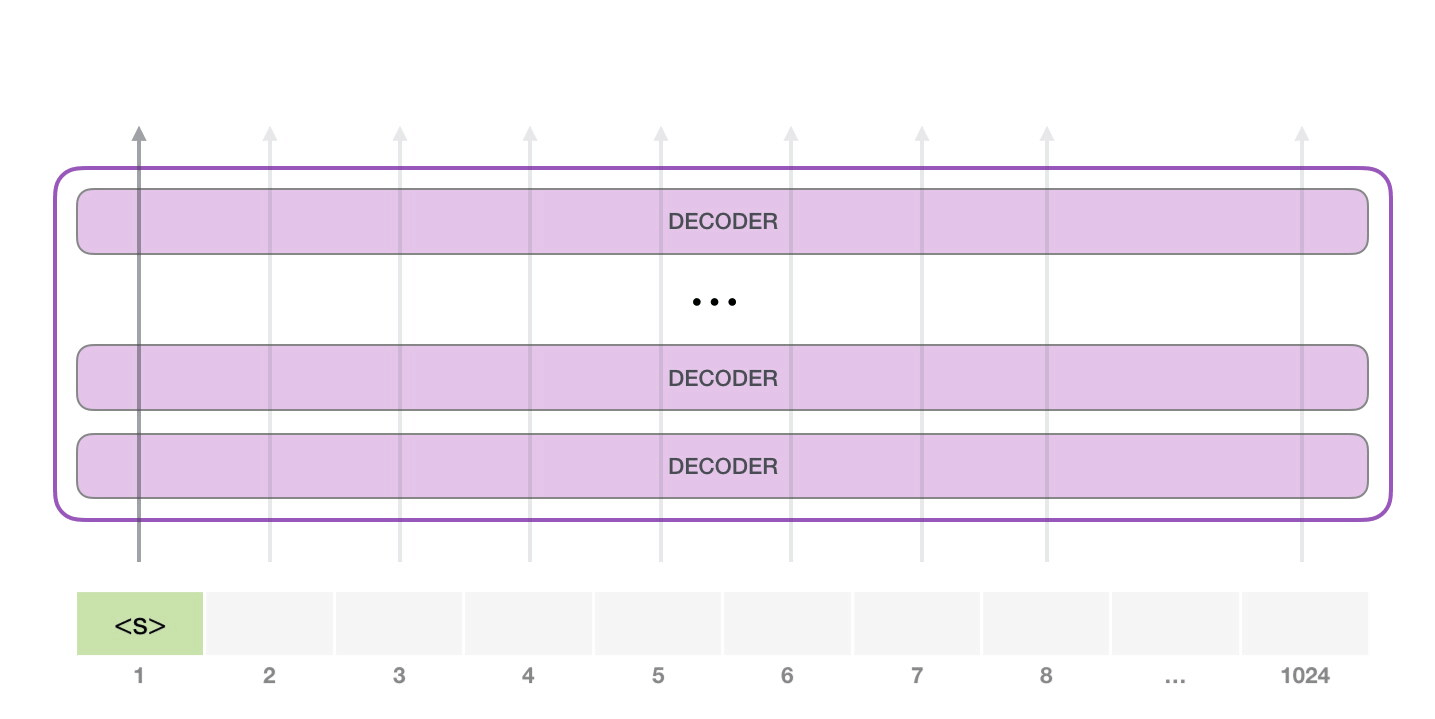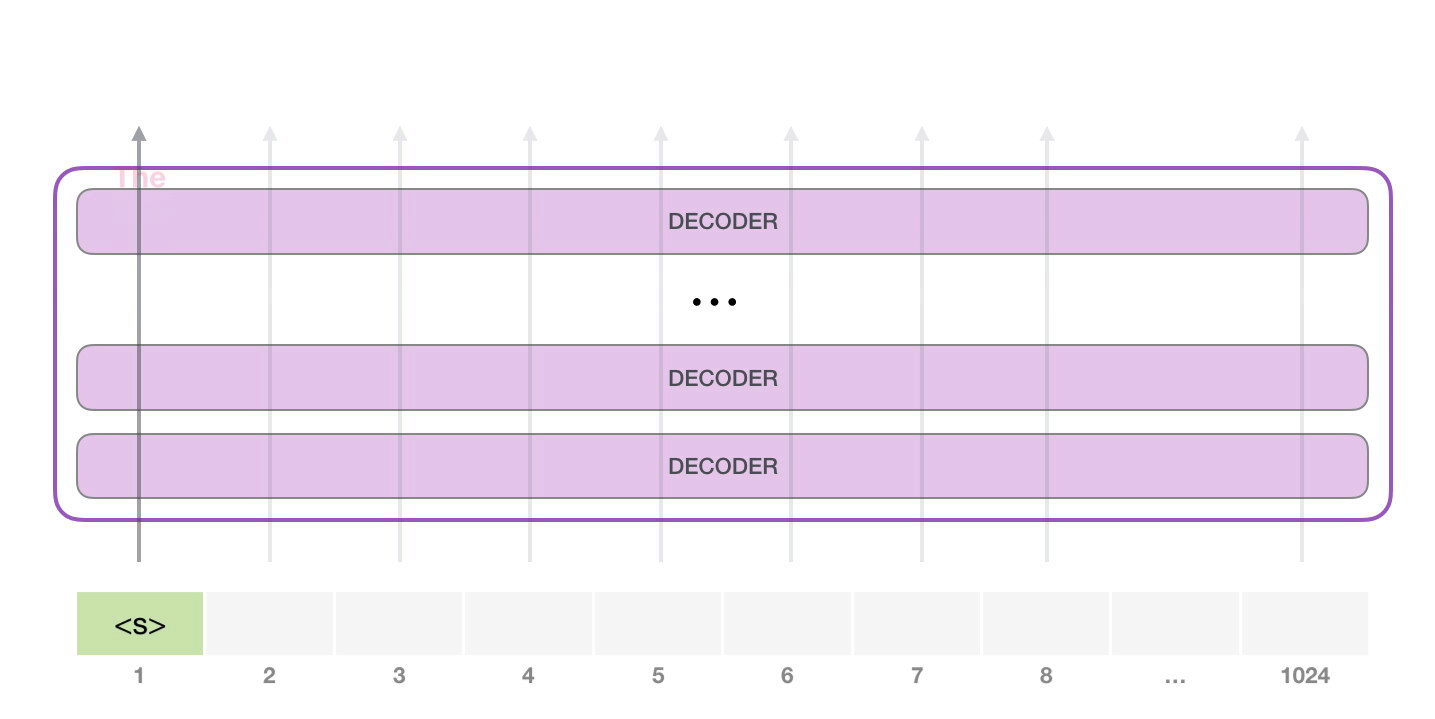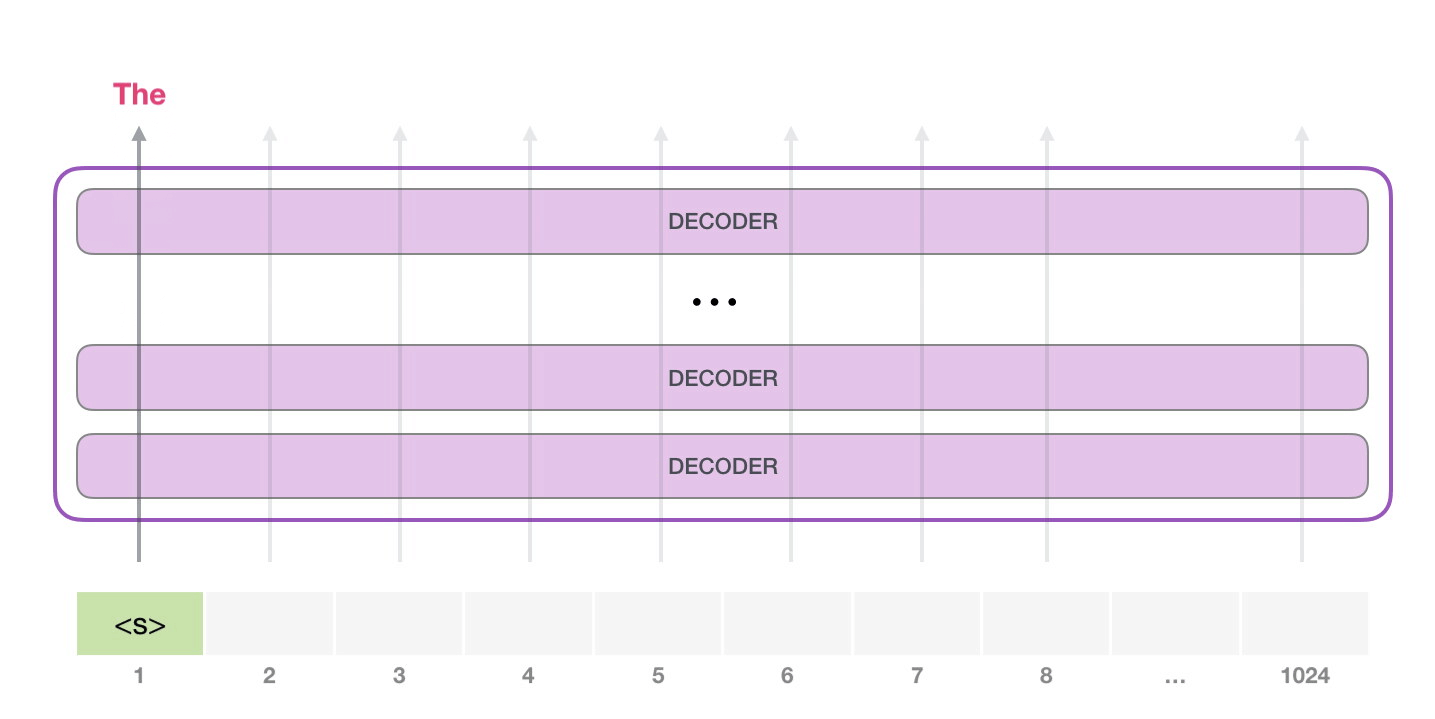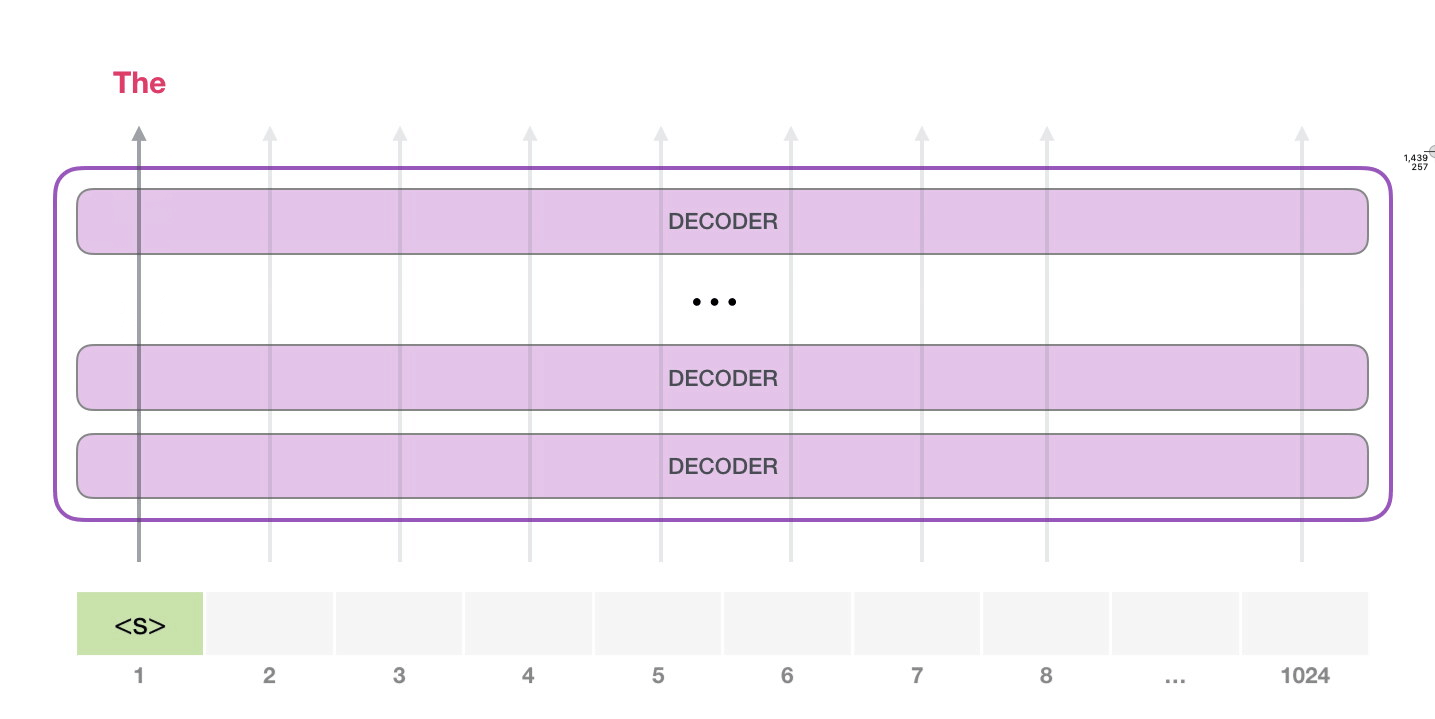
Le token est traité successivement à travers toutes les couches puis un vecteur est produit le long de ce chemin. Ce vecteur peut être évalué par rapport au vocabulaire du modèle (tous les mots que le modèle connaît, 50 000 mots dans le cas du GTP-2). Dans ce cas, nous avons sélectionné le token ayant la probabilité la plus élevée : « the ».
Sur votre téléphone, si vous cliquez à chaque fois sur le mot suggéré par votre application clavier, la suggestion peut parfois restée coincée dans des boucles répétitives où la seule issue est de cliquer sur le deuxième ou le troisième mot suggéré. La même chose peut se produire ici.
GPT-2 a un paramètre appelé top-k que nous pouvons utiliser pour que le modèle considère d’autres mots d’échantillonnage autres que le top mot (ce qui est le cas lorsque top-k = 1).
Dans l’étape suivante nous ajoutons le résultat de la première étape à notre séquence d’entrée et le modèle fait sa prochaine prédiction :
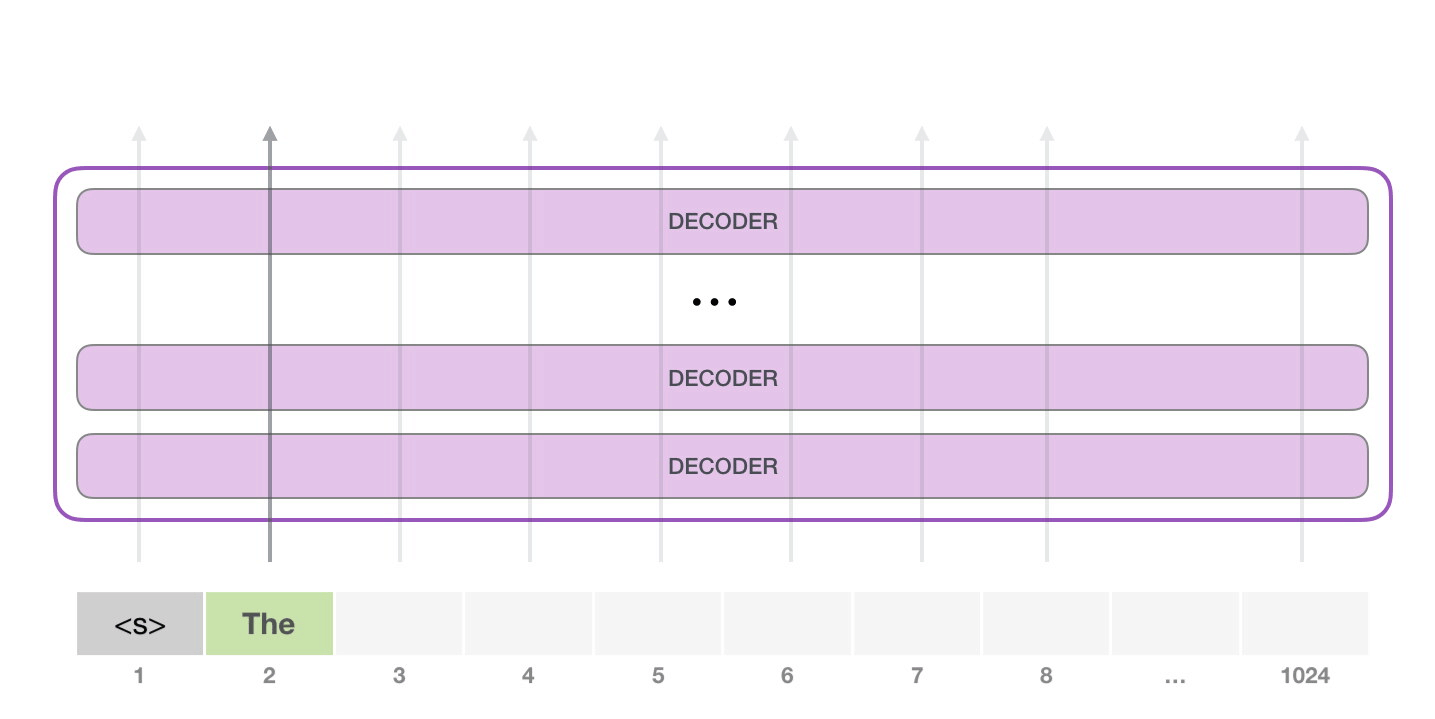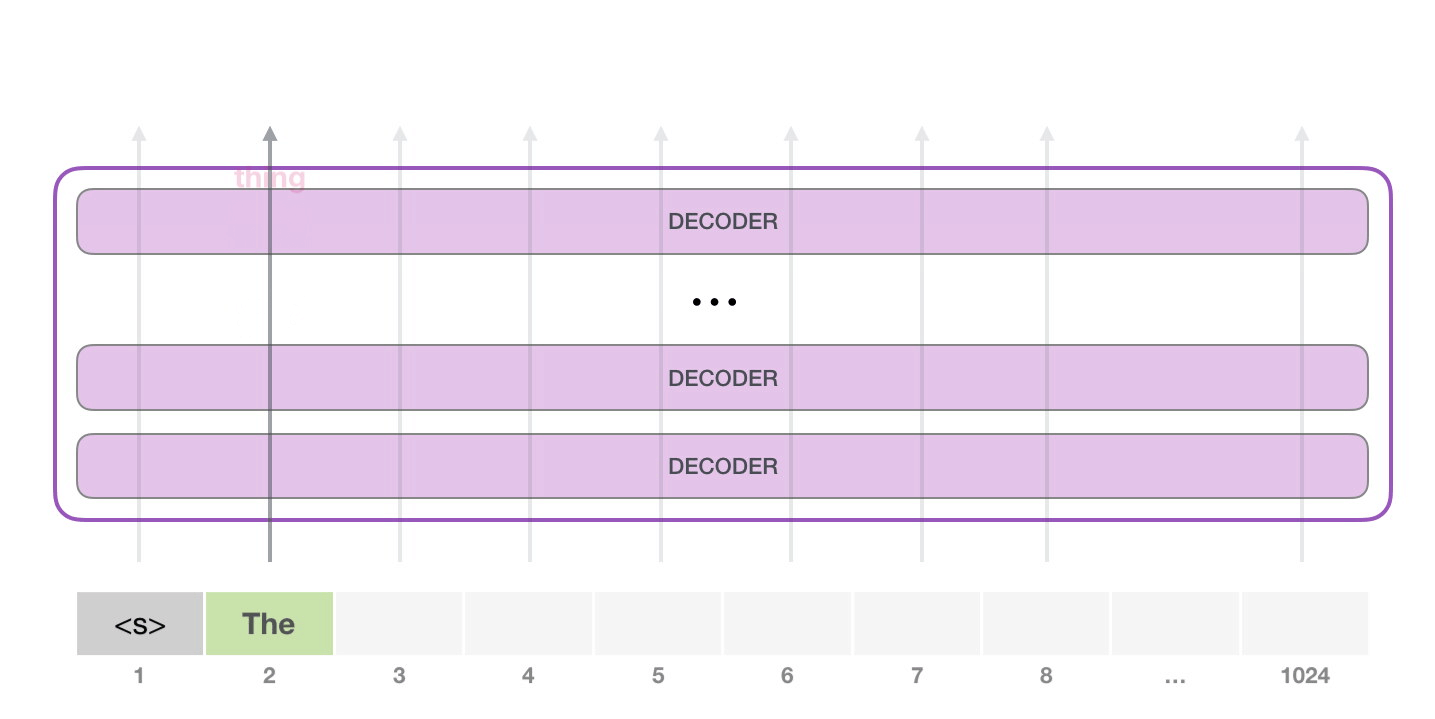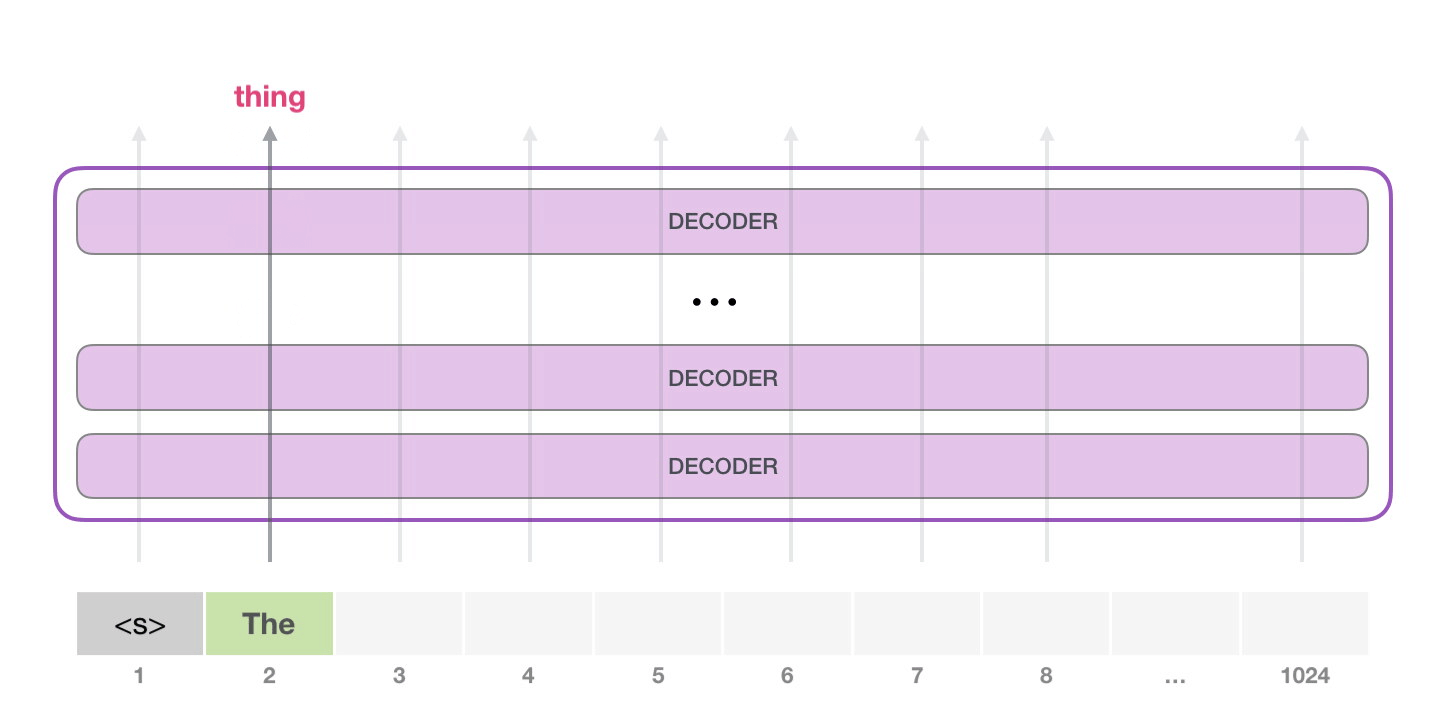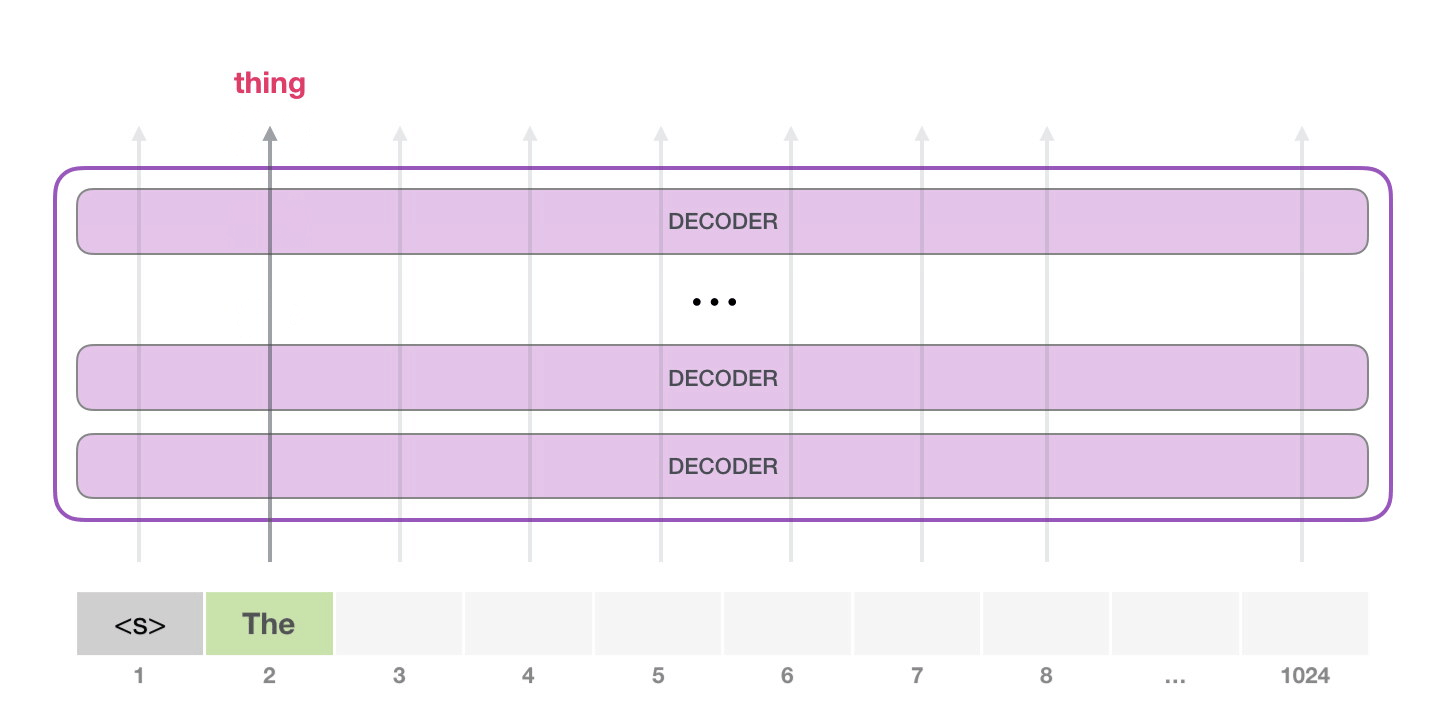
Notez que la deuxième étape est la seule qui est active dans ce calcul. Chaque couche du GPT-2 a conservé sa propre interprétation du premier token et l’utilisera dans le traitement du deuxième token (nous y reviendrons plus en détail dans la section suivante sur l’auto-attention). GPT-2 ne réinterprète pas le premier token à la lumière du second.
1.5.1 Encodage de l’entrée
Regardons plus en détail pour mieux comprendre le modèle. Commençons par l’entrée.
Comme dans d’autres modèles de NLP dont nous avons déjà parlé, le GPT-2 recherche l’enchâssement du mot d’entrée dans sa matrice d’enchâssement (obtenue après entraînement).
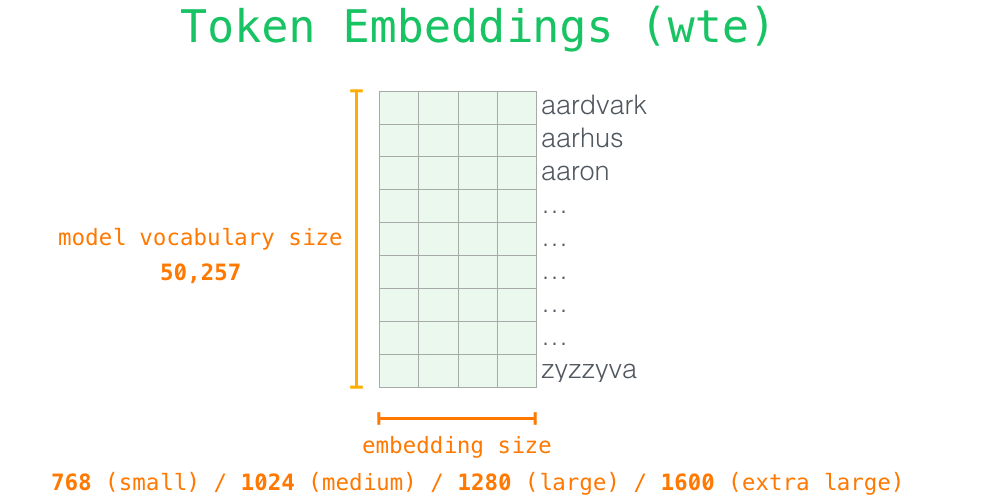
Ainsi au début nous recherchons l’enchâssement du token de départ <s> dans la matrice. Avant de le transmettre au premier bloc du modèle, nous devons enchâsser l’encodage positionnel (un signal qui indique aux blocs l’ordre des mots dans la séquence). Une partie du modèle entraîné contient une matrice ayant un vecteur d’encodage positionnel pour chacune des 1024 positions de l’entrée.
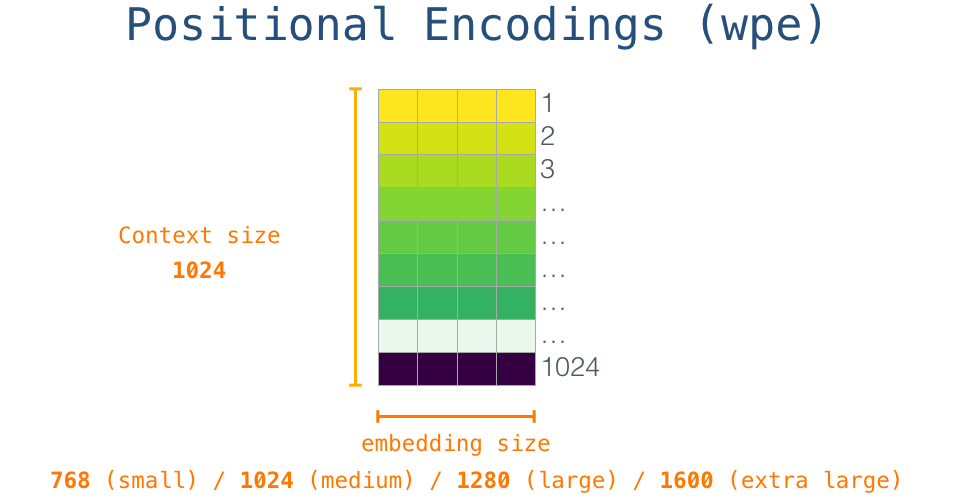
Schématiquement :

1.5.2 Voyage dans le bloc
Le premier bloc peut maintenant traiter le premier token en le faisant passer d’abord par le processus d’auto-attention puis par sa couche feed-forward. Une fois le traitement effectué, le bloc envoie le vecteur résultant pour qu’il soit traité par le bloc suivant. Le processus est identique dans chaque bloc mais chaque bloc a des poids qui lui sont propres dans l’auto-attention et dans les sous-couches du réseau neuronal.
1.5.3 Rappel de l’auto-attention
Le langage dépend beaucoup du contexte. Par exemple, regardez la deuxième loi de la robotique :
« A robot must obey the orders given it by human beings except where such orders would conflict with the First Law »
(Un robot doit obéir aux ordres donnés par les êtres humains, sauf si ces ordres entrent en conflit avec la première loi.)
A trois endroits dans la phrase des mots renvoient à d’autres mots. Il n’y a aucun moyen de comprendre ou de traiter ces mots sans enchâsser le contexte auquel ils font référence. Lorsqu’un modèle traite cette phrase, il doit pouvoir savoir que :
- it se réfère au robot
- such orders se réfèrent à la partie antérieure de la loi, à savoir « les ordres donnés par des êtres humains »
- First Law se réfère à l’ensemble de la première loi
C’est ce que réalise l’auto-attention. Pour ce faire, on attribue des scores à la pertinence de chaque mot du segment et on additionne leur représentation vectorielle.
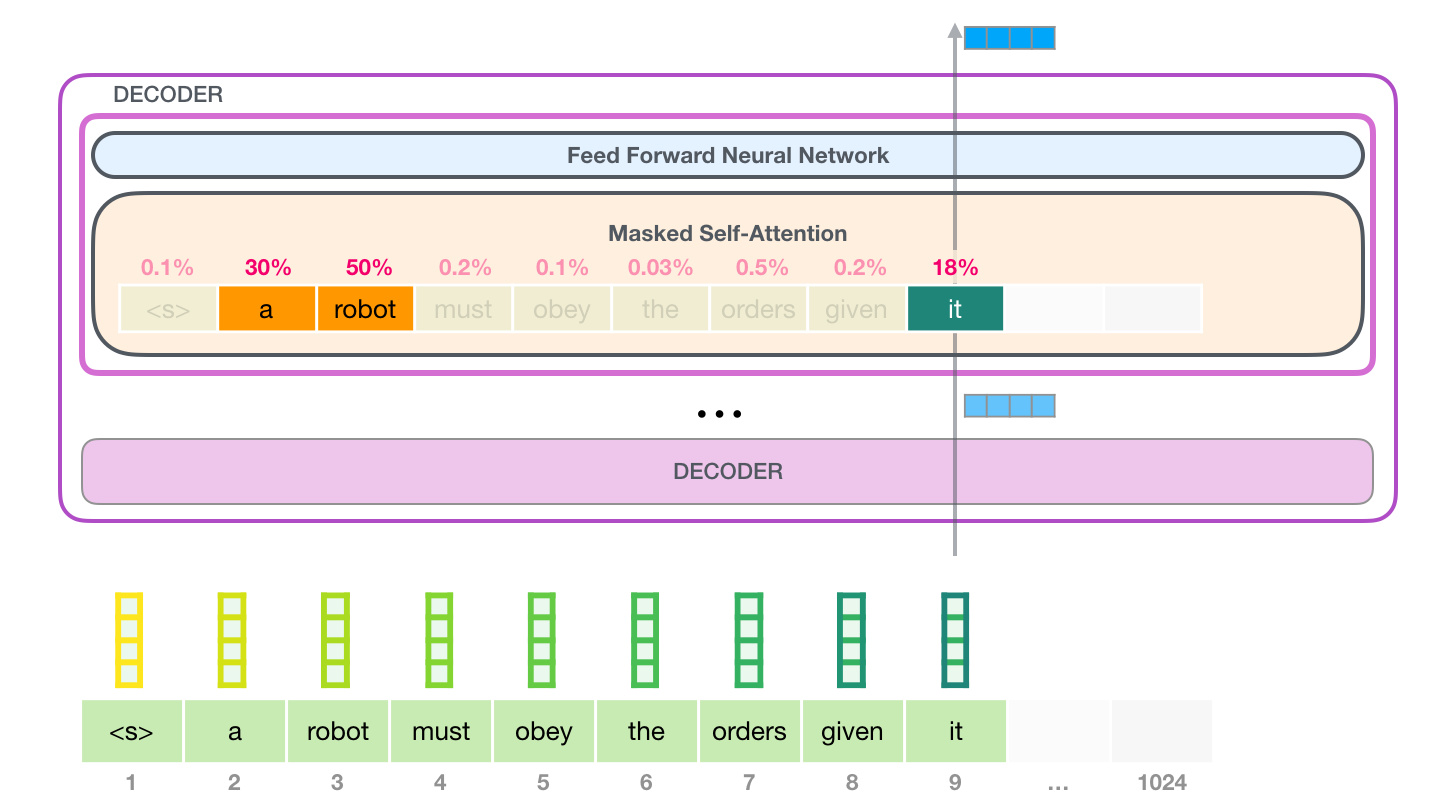
A titre d’exemple, la couche d’auto-attention dans le bloc du haut fait attention à « a robot » lorsqu’elle traite le mot « it ». Le vecteur qui est ensuite passer au réseau feed-forward est la somme des vecteurs de chacun des trois mots multipliés par leurs scores.
1.5.4 Le processus de l’auto-attention
L’auto-attention est traitée le long du parcours de chaque token. Les composantes significatives sont trois vecteurs :
- Query : la requête est une représentation du mot courant. Elle est utilisée pour donner un score au mot vis-à-vis des autres mots (en utilisant leurs clés).
- Key : les vecteurs clés sont comme des labels pour tous les mots de la séquence. C’est contre eux que nous nous mesurons dans notre recherche de mots pertinents.
- Value : les vecteurs de valeurs sont des représentations de mots réels. Une fois que nous avons évalué la pertinence de chaque mot, ce sont les valeurs que nous additionnons pour représenter le mot courant.
Une analogie grossière est de penser à la recherche dans un classeur. La requête (query) est le sujet que vous recherchez. Les clés (key) sont comme les étiquettes des chemises à l’intérieur de l’armoire. Lorsque vous faites correspondre la requête et la clé, nous enlevons le contenu du dossier. Le contenu correspond au vecteur de valeur (value). Sauf que vous ne recherchez pas seulement une valeur, mais un mélange de valeurs à partir d’un mélange de dossiers.
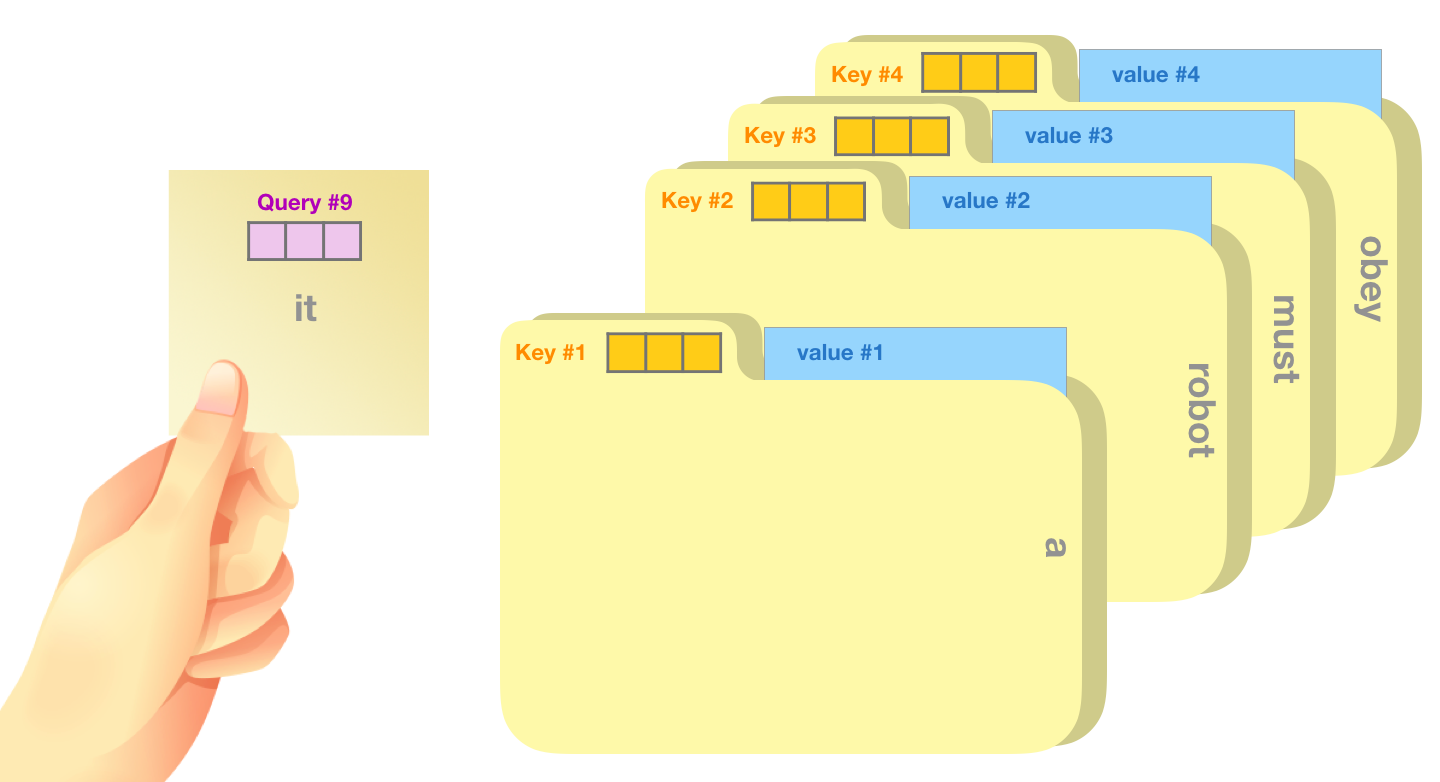
Multiplier le vecteur de requête par chaque vecteur clé produit un score pour chaque dossier (techniquement : le produit scalaire suivi de la fonction softmax).
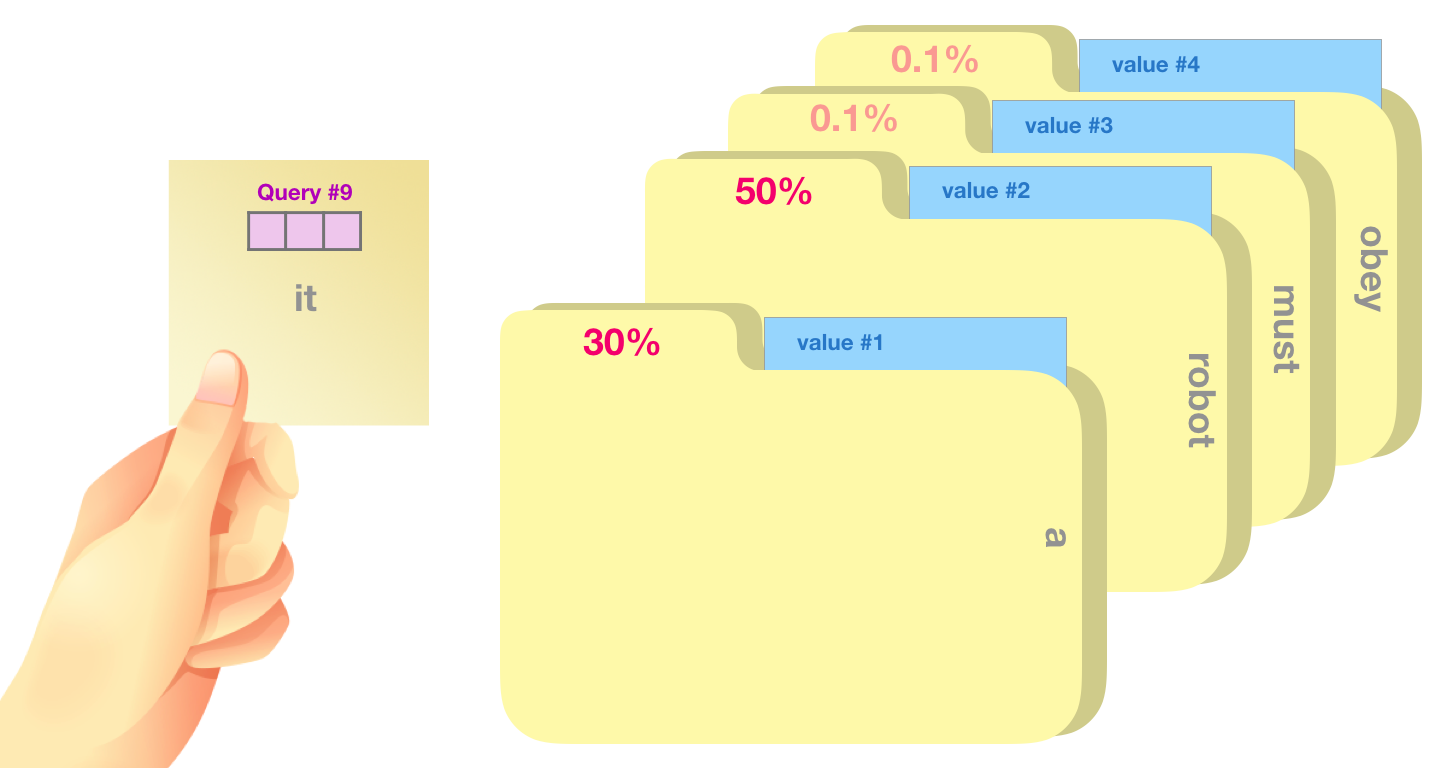
Nous multiplions chaque valeur par son score et sommons. Cela donne le résultat de notre auto-attention.
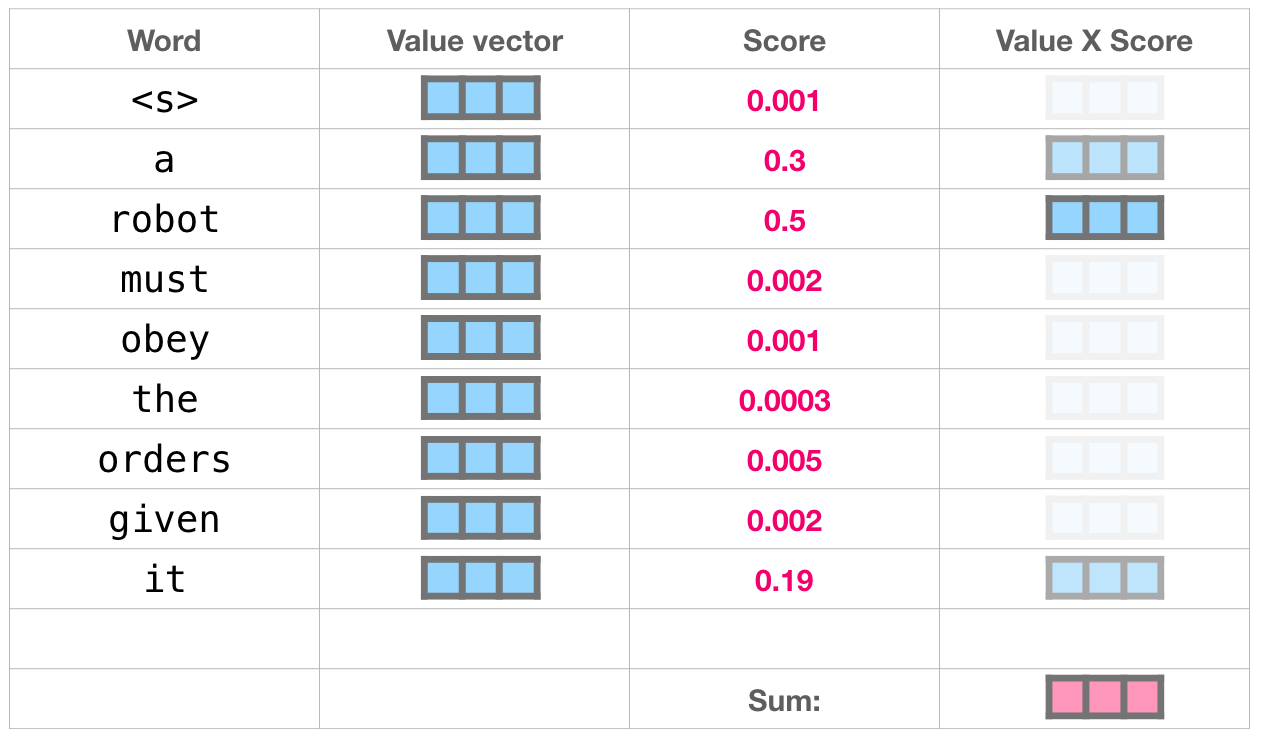
Cette opération permet d’obtenir un vecteur pondéré où on peut voir par exemple que l’attention a été a prêté à 50% sur le mot « robot », 30% au mot « a », et 19% au mot « it ».
Dans la partie 2 on s’intéressera de plus près à l’auto-attention. Mais d’abord, continuons notre cheminement vers le haut de la pile et vers la sortie du modèle.
1.5.5 Sortie du modèle
Lorsque le bloc le plus haut du modèle produit son vecteur de sortie (le résultat de sa propre auto-attention suivie de son propre réseau feed-forward), le modèle multiplie ce vecteur par la matrice d’enchâssement.
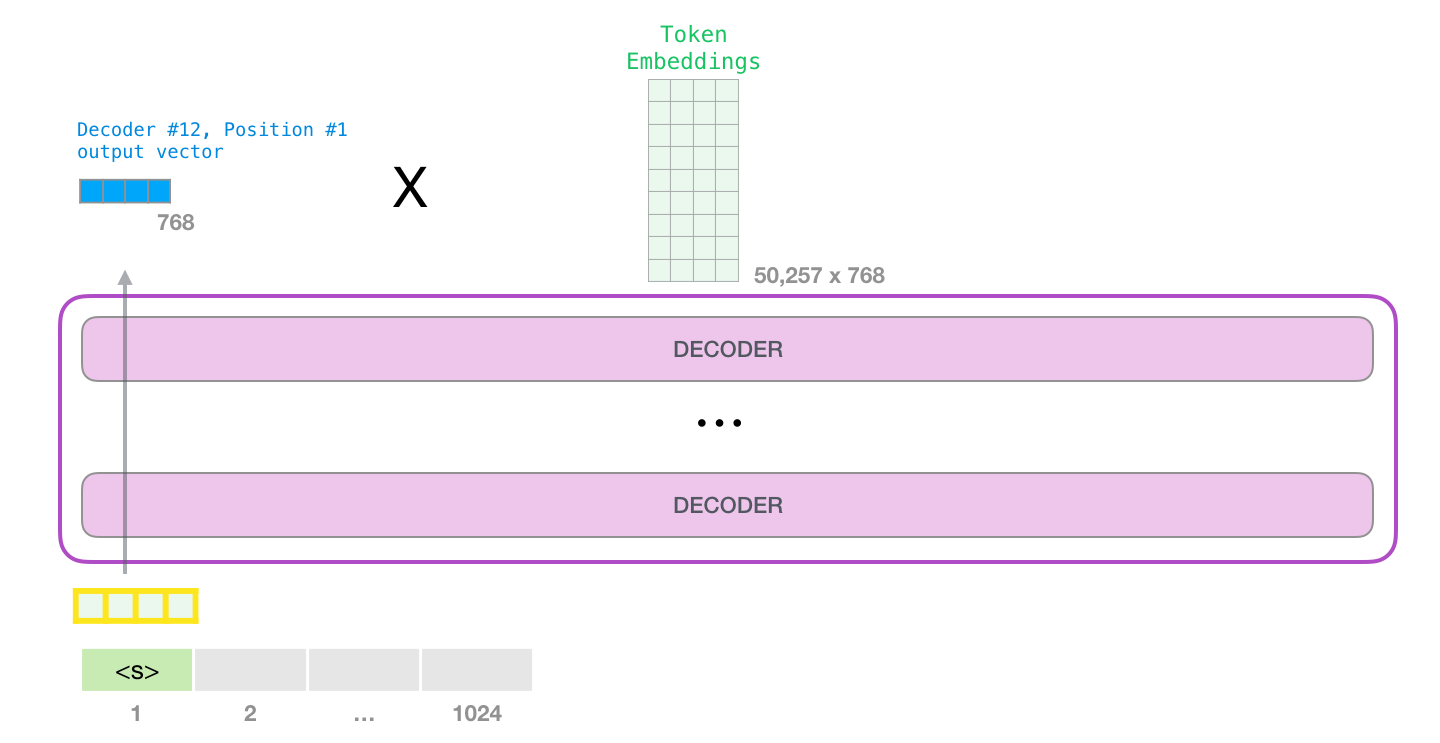
Rappelons que chaque ligne de la matrice d’enchâssement correspond à l’enchâssement d’un mot dans le vocabulaire du modèle. Le résultat de cette multiplication est interprété comme un score pour chaque mot du vocabulaire du modèle.
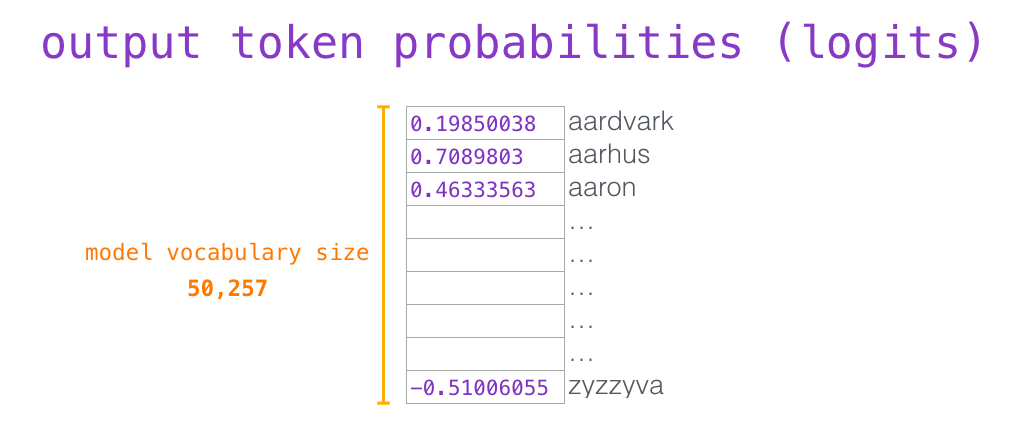
Nous pouvons simplement sélectionner le token avec le score le plus élevé (top_k = 1). Mais de meilleurs résultats sont obtenus si le modèle tient également compte d’autres termes. Ainsi, une bonne stratégie consiste à tirer au hasard un mot provenant du vocabulaire. Chaque mot ayant comme probabilité d’être sélectionner, le score qui lui a été attribué (de sorte que les mots avec un score plus élevé ont une plus grande chance d’être sélectionnés). Un terrain d’entente consiste à fixer top_k à 40 et à demander au modèle de prendre en compte les 40 mots ayant obtenu les scores les plus élevés.
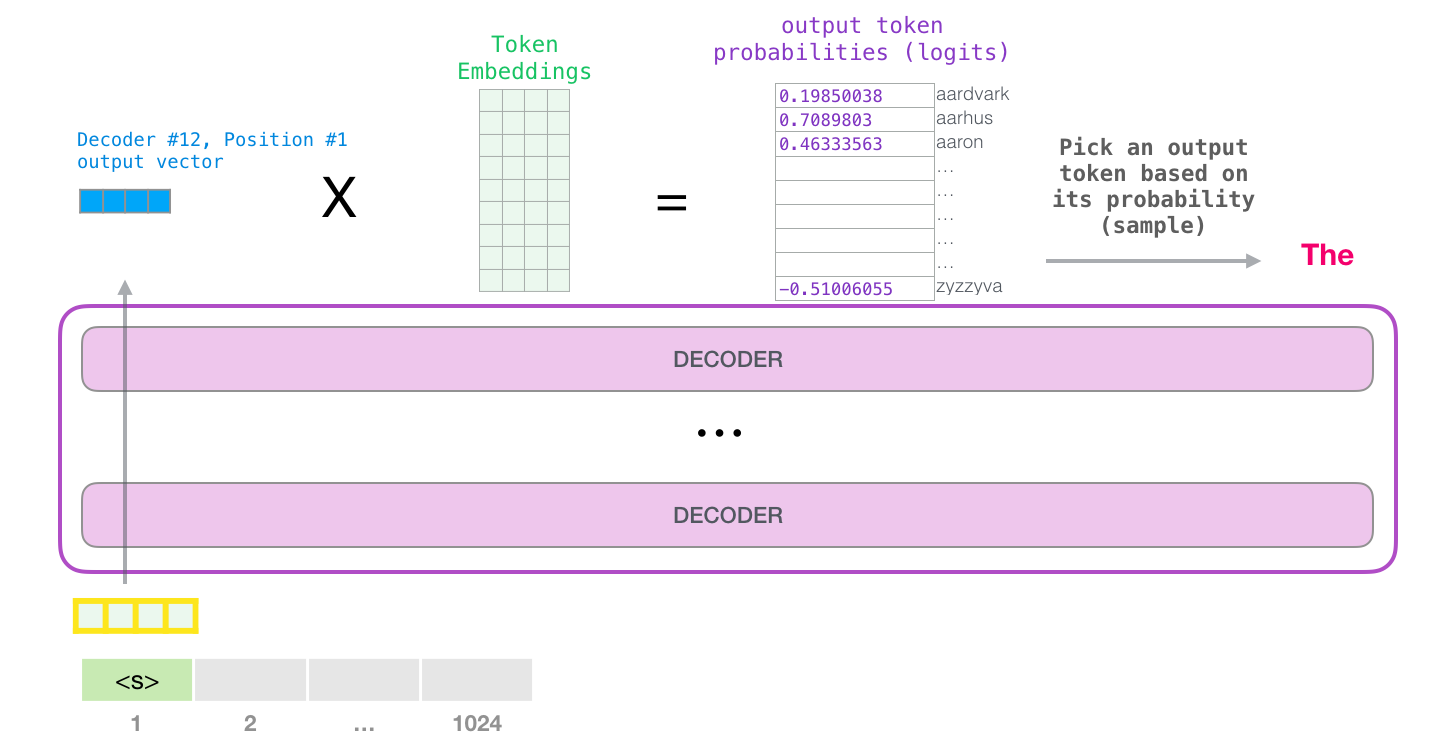
Le modèle a alors terminé une itération aboutissant à la production d’un seul mot. Le modèle recommence alors le processus jusqu’à ce que le contexte entier soit généré (1024 tokens) ou qu’un token de fin de séquence soit produit.
1.6 Fin de la partie 1
Voici donc un succinct aperçu du fonctionnement du GPT2. Le détail de ce qui se passe à l’intérieur de la couche d’auto-attention fait l’objet de la deuxième partie.
Notons que nous avons procéder dans cette première partie à quelques simplifications excessives :
- Nous employons les termes « mots » et « tokens » de façon interchangeable. Mais en réalité, le GPT2 utilise le Byte Pair Encoding pour créer les tokens dans son vocabulaire. Cela signifie que les tokens sont généralement des parties des mots. Je vous invite à voir l’article sur les tokenizers du blog pour plus de détails.
- Nous avons pris des libertés dans la rotation/transposition des vecteurs pour mieux gérer la mise en page dans les images. Au moment de l’implémentation, il faut être plus précis.
- Les transformers utilisent des couches de normalisation dans les blocs. Nous nous sommes davantage concentrés sur l’auto-attention dans cet article.
2. Illustration de l’auto-attention
Plus tôt nous avons montré l’image suivante afin d’illustrer l’auto-attention appliquée pour le mot « it »

Dans cette partie, nous examinons en détail la façon de procéder. Notre volonté est d’essayer de donner un sens à ce qui arrive à chaque mot. C’est pourquoi sur les graphiques nous utilisons de nombreux vecteurs uniques. Les implémentations réelles se font en multipliant des matrices géantes ensemble. L’objectif ici est de se concentrer sur l’intuition de ce qui se passe au niveau des mots.
2.1 Auto-attention (sans masque)
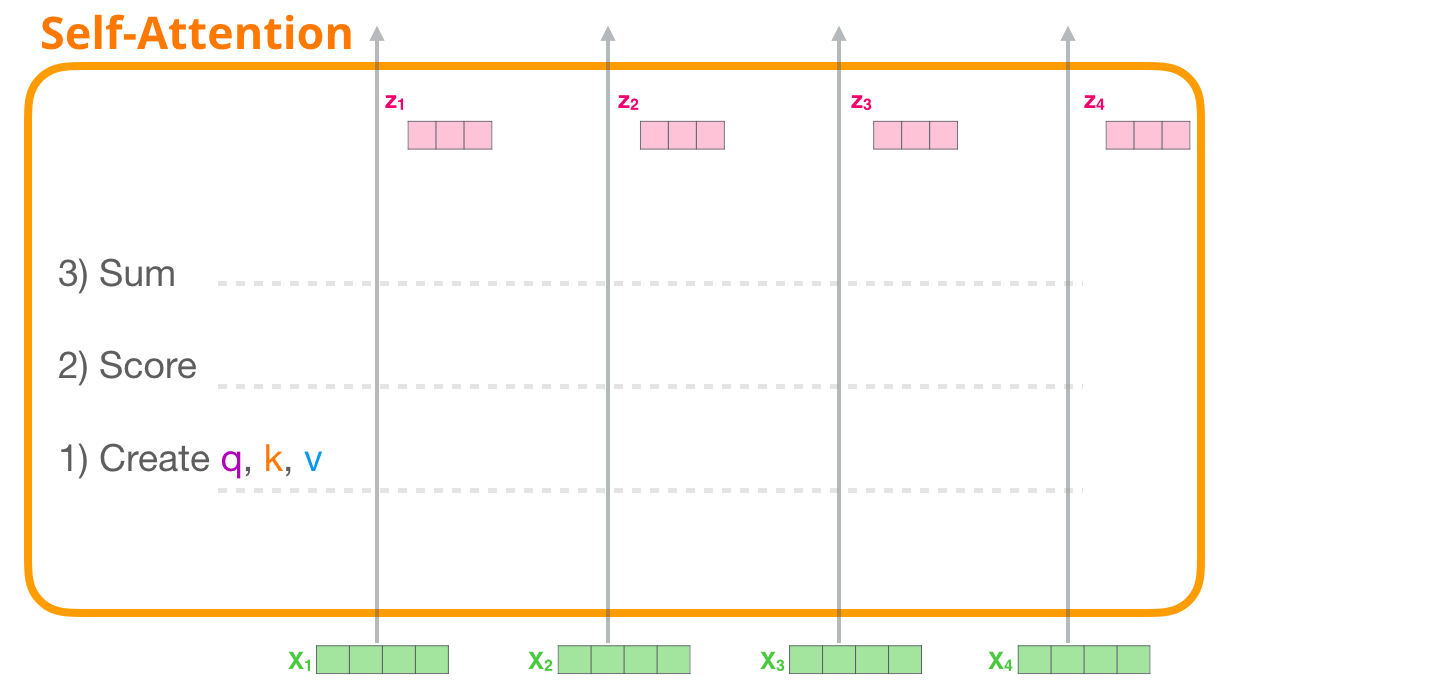
Commençons par regarder l’auto-attention « originale » telle qu’elle est calculée dans un bloc encodeur. L’auto-attention s’applique en trois étapes principales :
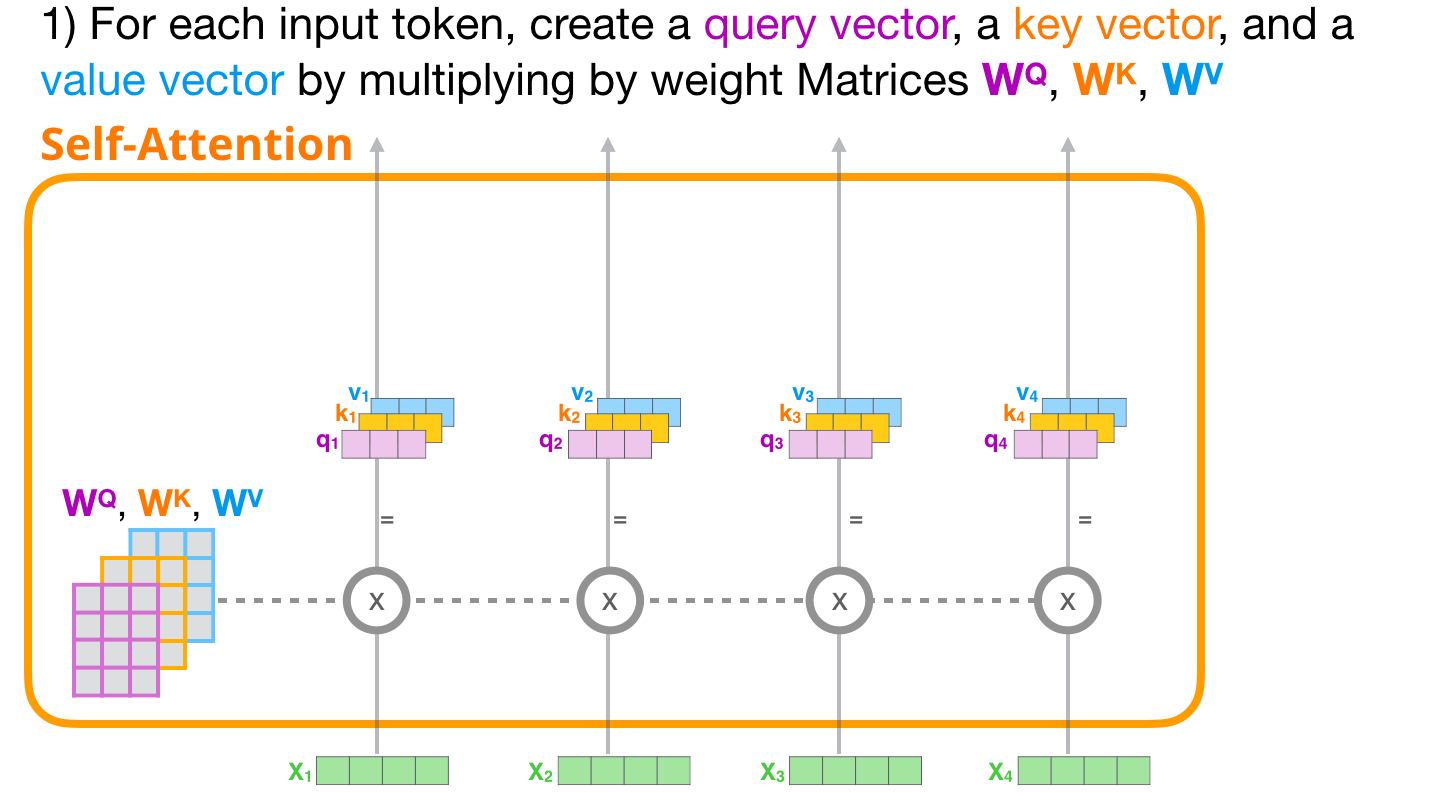
- Création des vecteurs Query, Key et Value pour chaque chemin.
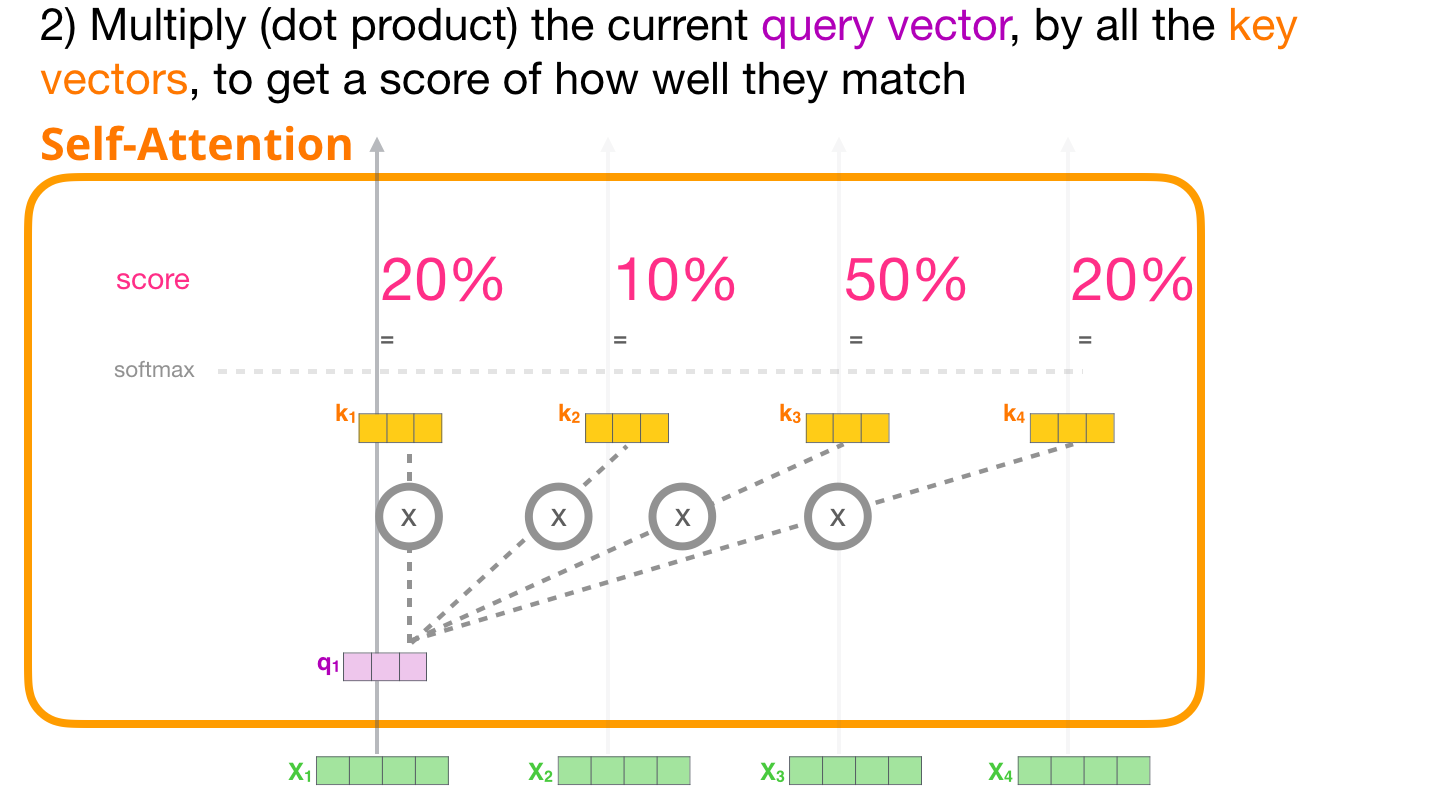
- Pour chaque token d’entrée, on utilise son vecteur de requête pour lui attribuer un score par rapport à tous les autres vecteurs clés.
- Sommation des vecteurs de valeurs après les avoir multipliés par leurs scores associés.
2.1.1 Création des vecteurs Query, Key et Value
Pour le premier token, nous prenons sa requête et la comparons à toutes les clés. Cela produit un score pour chaque clé. La première étape de l’auto-attention consiste à calculer les trois vecteurs pour chaque token (ignorons les têtes d’attention pour le moment) :
2.1.2 Score
Nous nous concentrons sur le premier token. Nous multiplions sa requête par tous les autres vecteurs clés pour obtenir un score pour chacun des quatre tokens.
2.1.3 Somme
Nous pouvons maintenant multiplier les scores par les vecteurs de valeurs. Une valeur avec un score élevé constituera une grande partie du vecteur résultant une fois que nous les aurons additionnés.
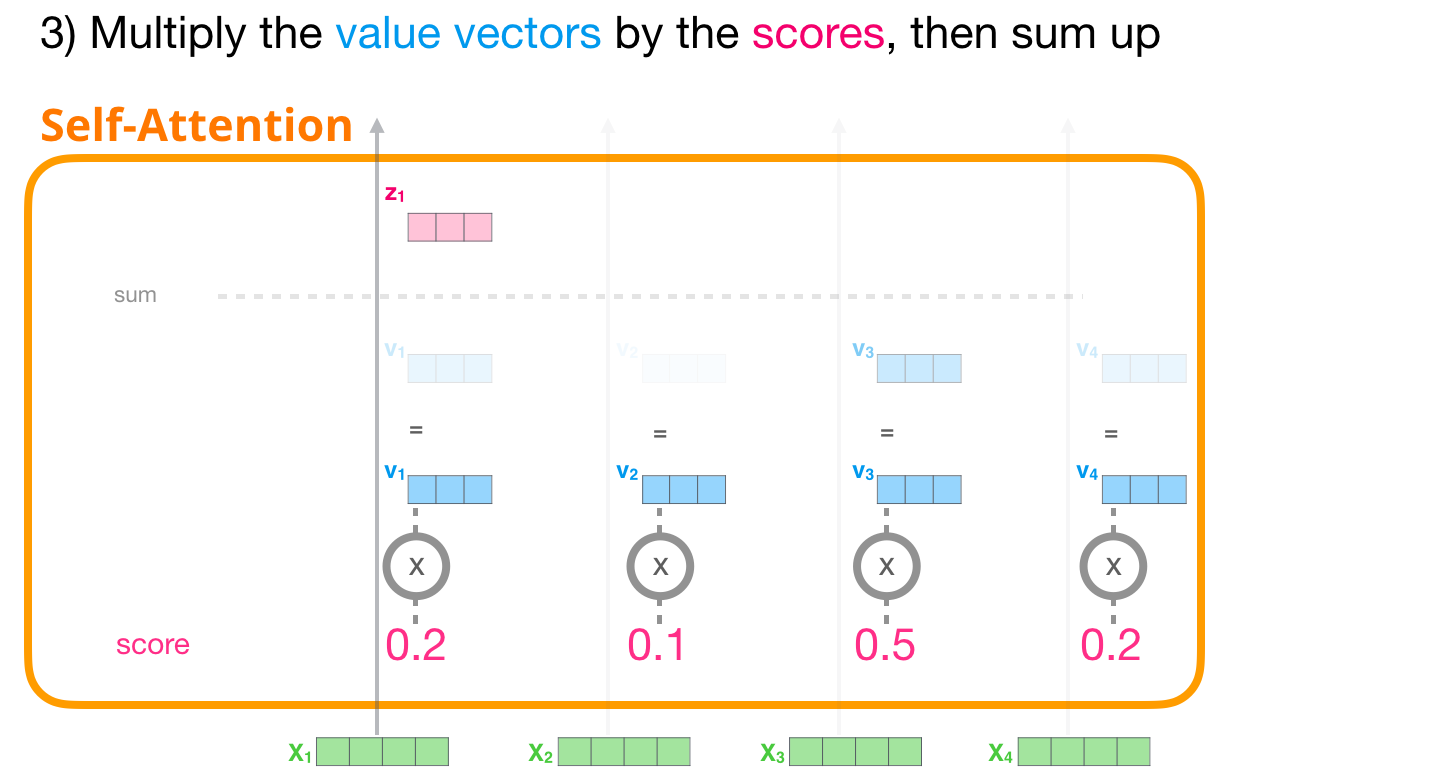
Si nous faisons la même opération pour chaque token, nous obtenons un vecteur représentant et tenant compte du contexte pour chacun d’eux. Ces vecteurs sont ensuite présentés à la sous-couche suivante du bloc (le réseau feed-forward).
Résumé :
2.2 Auto-attention (avec masque)
L’auto-attention masquée est identique à l’auto-attention, sauf à l’étape 2.
Supposons que le modèle n’a que deux tokens en entrée et que nous observons le deuxième token. Dans ce cas, les deux derniers tokens sont masqués. Le modèle attribue alors toujours aux futurs tokens un score de 0.
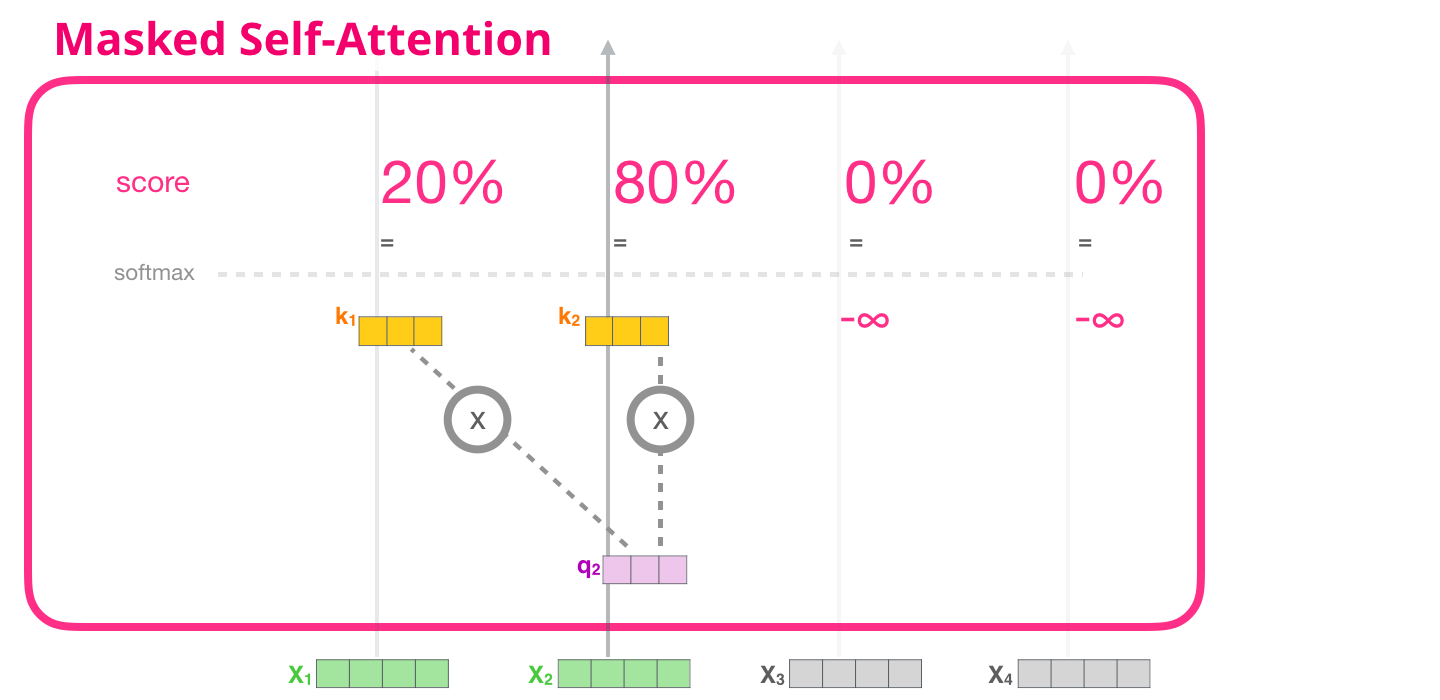
Ce « masquage » est souvent mis en œuvre sous la forme d’une matrice appelée masque d’attention.
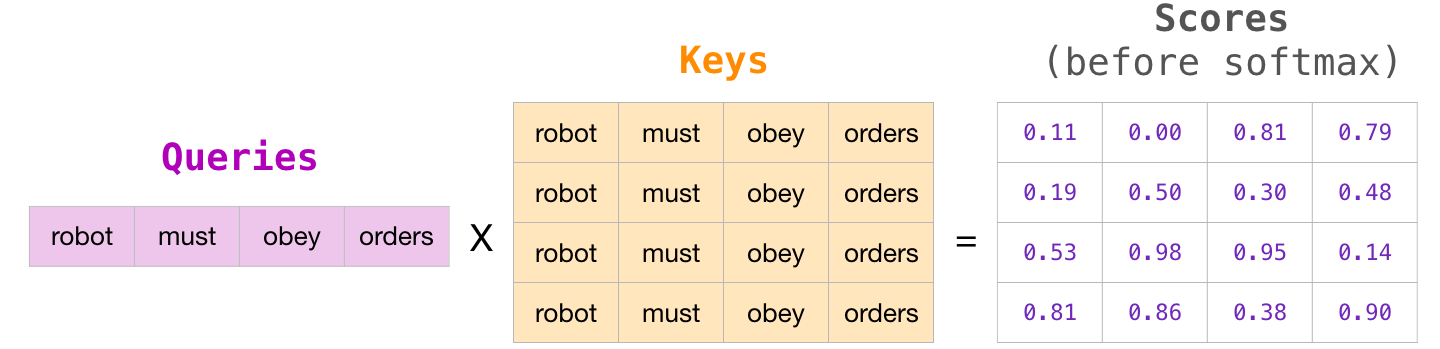
A titre d’exemple, supposons avoir une séquence de quatre mots : « robot must obey orders ».
Sous forme matricielle, nous calculons les scores en multipliant une matrice de requêtes par une matrice clés :
Après la multiplication, nous appliquons notre masque d’attention. Il règle les cellules que l’on veut masquer sur -inf ou un nombre négatif très important (par exemple -1 milliard pour le GPT2) :
Ensuite, l’application de la fonction softmax produit les scores que nous utilisons pour l’auto-attention :
La signification de ce tableau de scores est la suivante :
- Lorsque le modèle traite le premier exemple du jeu de données (ligne #1), qui ne contient qu’un seul mot (« robot »), 100% de son attention se porte sur ce mot.
- Lorsque le modèle traite le deuxième exemple du jeu de données (ligne #2), qui contient les mots (« robot must »), lorsqu’il traite le mot « must », 48% de son attention porte sur « robot » et 52% sur « must ».
- Et ainsi de suite.
2.3 L’auto-attention masquée du GPT-2
Le GPT-2 conserve les vecteurs clé et valeur des tokens qu’il a déjà traité afin de ne peut à avoir à les recalculer à chaque fois qu’un nouveau token est traité. En pratique, le processus se déroule comme suit :
2.3.1 Etape 1 : Création des vecteurs Query, Key et Value
Supposons que le modèle traite le mot « it ». Si nous parlons du bloc du bas, alors l’entrée pour ce token serait l’enchâssement de « it » + l’encodage positionnel pour la position #9 :
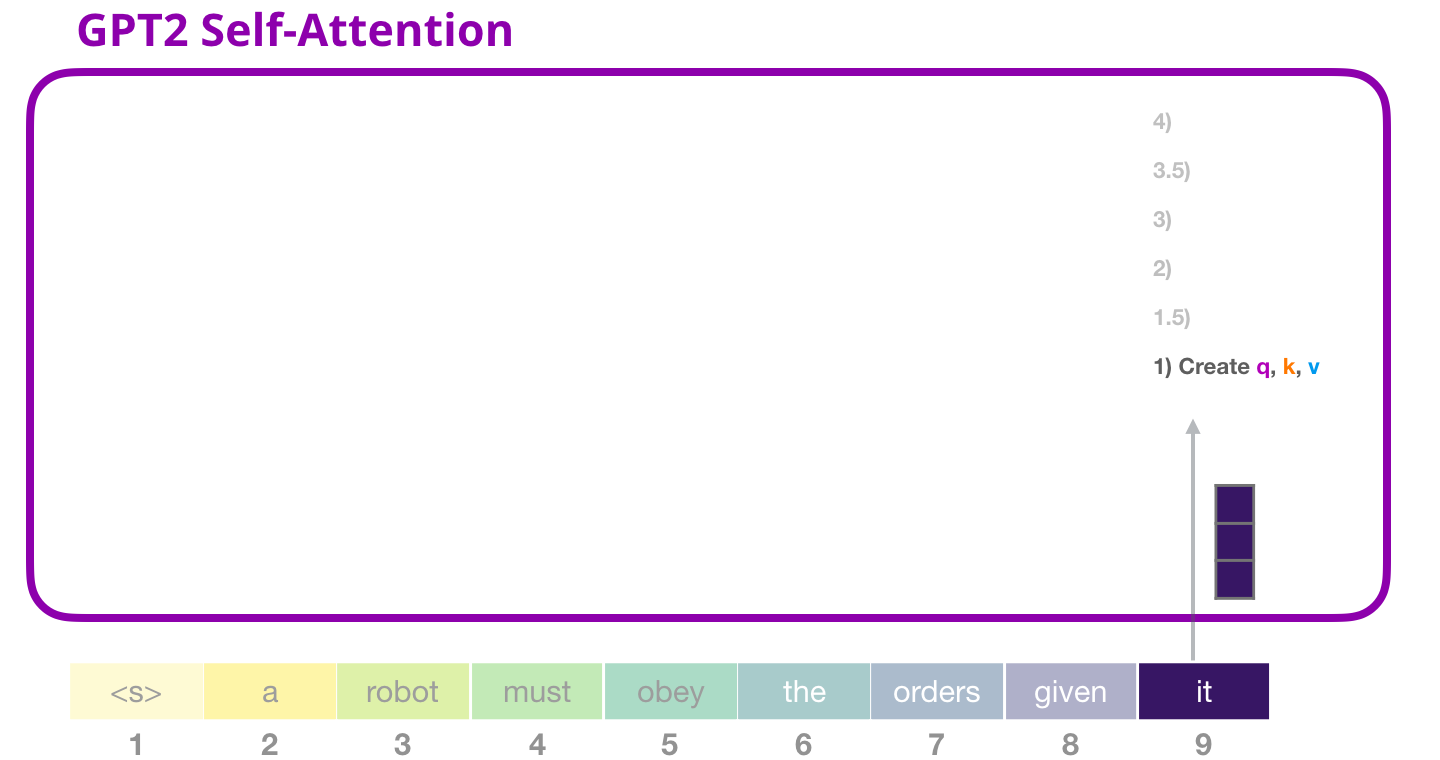
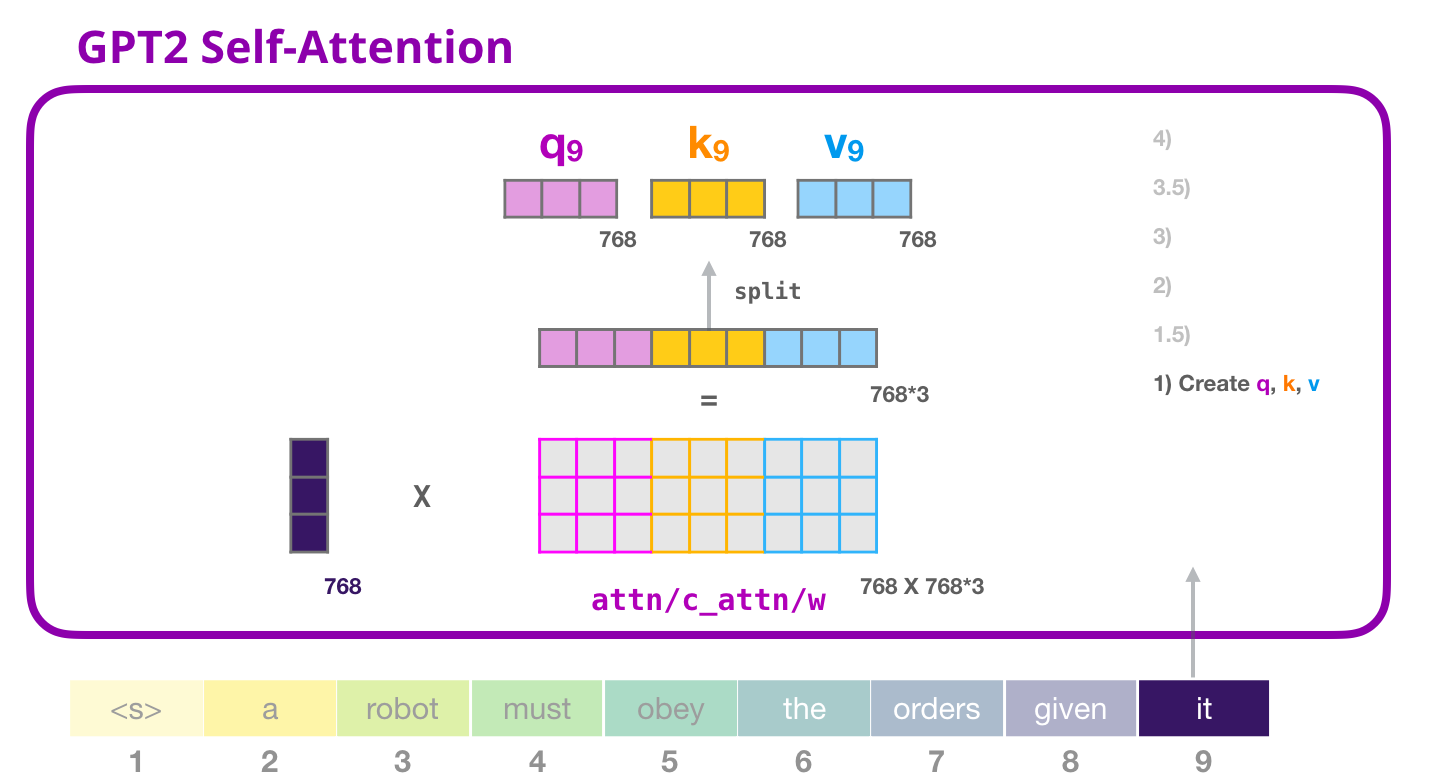
Chaque bloc a ses propres poids. Nous nous servons de la matrice de poids pour créer les vecteurs des requêtes, des clés et des valeurs. Cela consiste en pratique à une simple multiplication.
Le vecteur résultant de la multiplication est la concaténation des vecteurs recherchés pour le mot « it ».
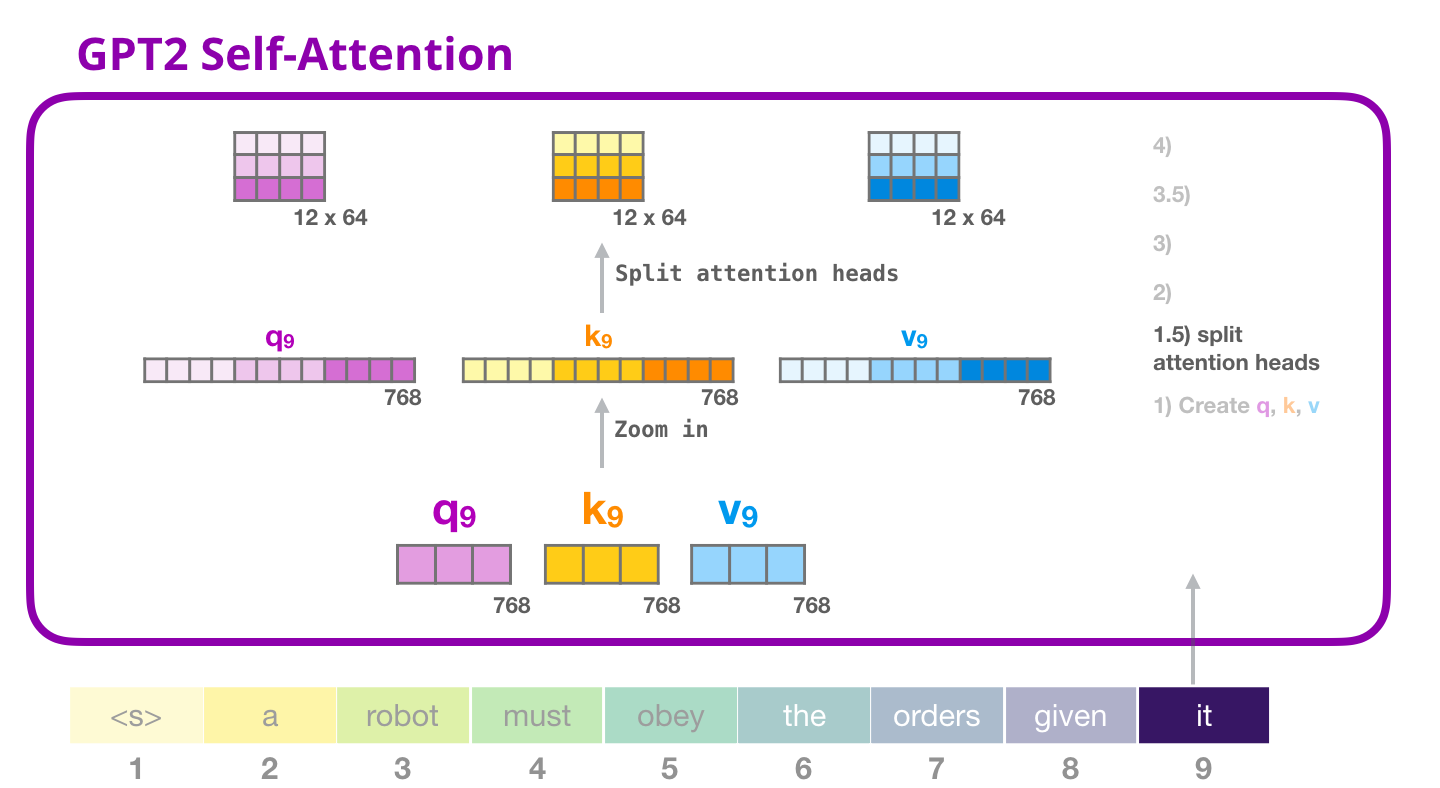
2.3.2 Etape 1.5 : Les têtes d’attention
Dans les exemples précédents, nous avons plongé directement dans l’auto-attention en ignorant la partie « multi-têtes ». Il serait utile de faire la lumière sur ce concept.
L’auto-attention est menée plusieurs fois sur différentes parties des vecteurs Q,K,V.
Séparer les têtes d’attention, c’est simplement reconstruire le vecteur long sous forme de matrice.
Le plus petit GPT2 possède 12 têtes d’attention. Il s’agit donc de la première dimension de la matrice remodelée :
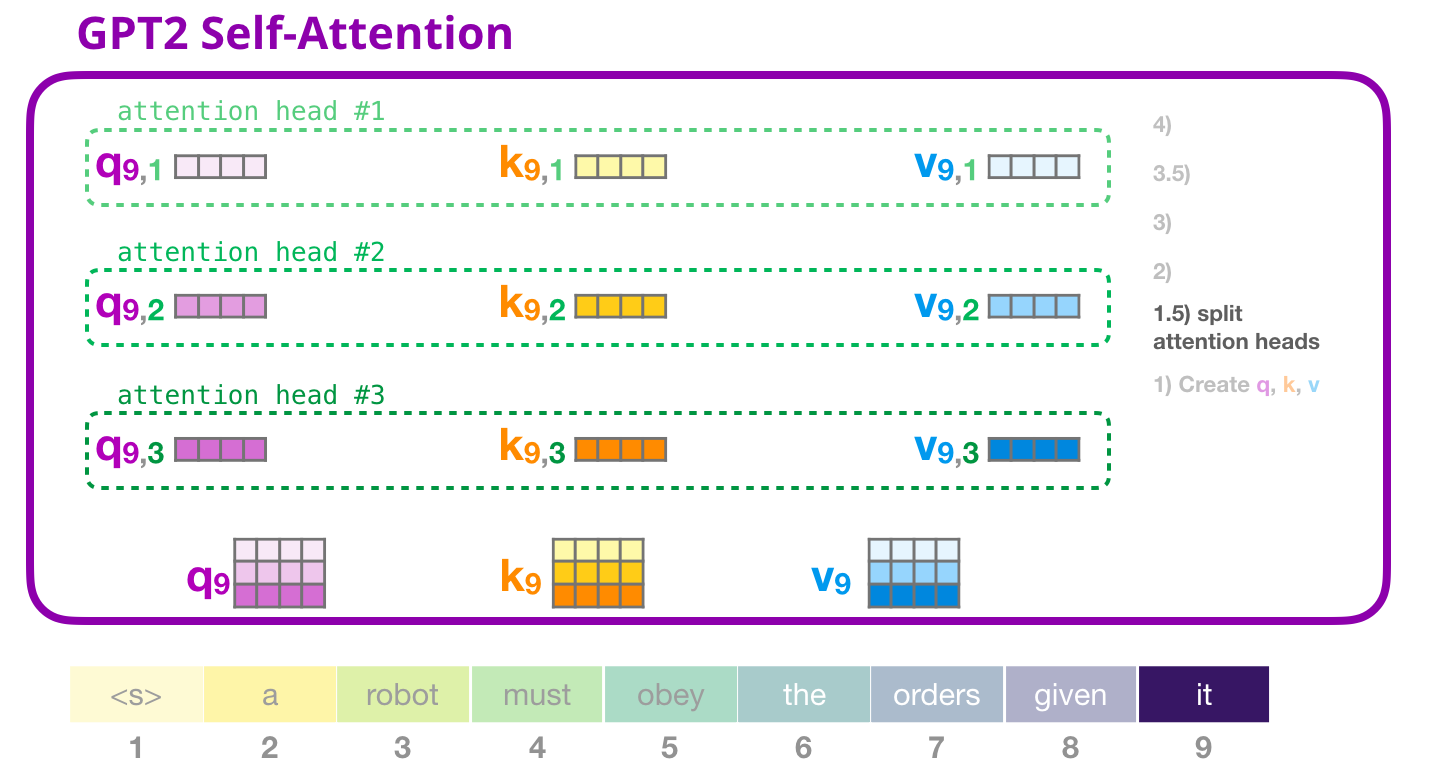
Dans les exemples précédents, nous avons examiné ce qui se passe à l’intérieur d’une tête d’attention. Voici comment on pourrait visualiser par exemple trois des douze têtes d’attention :
2.3.3 Etape 2 : Scoring
Nous pouvons maintenant procéder au scoring (en sachant que nous ne regardons qu’une seule tête d’attention et que toutes les autres mènent une opération similaire). Dans le cadre du token « it » :
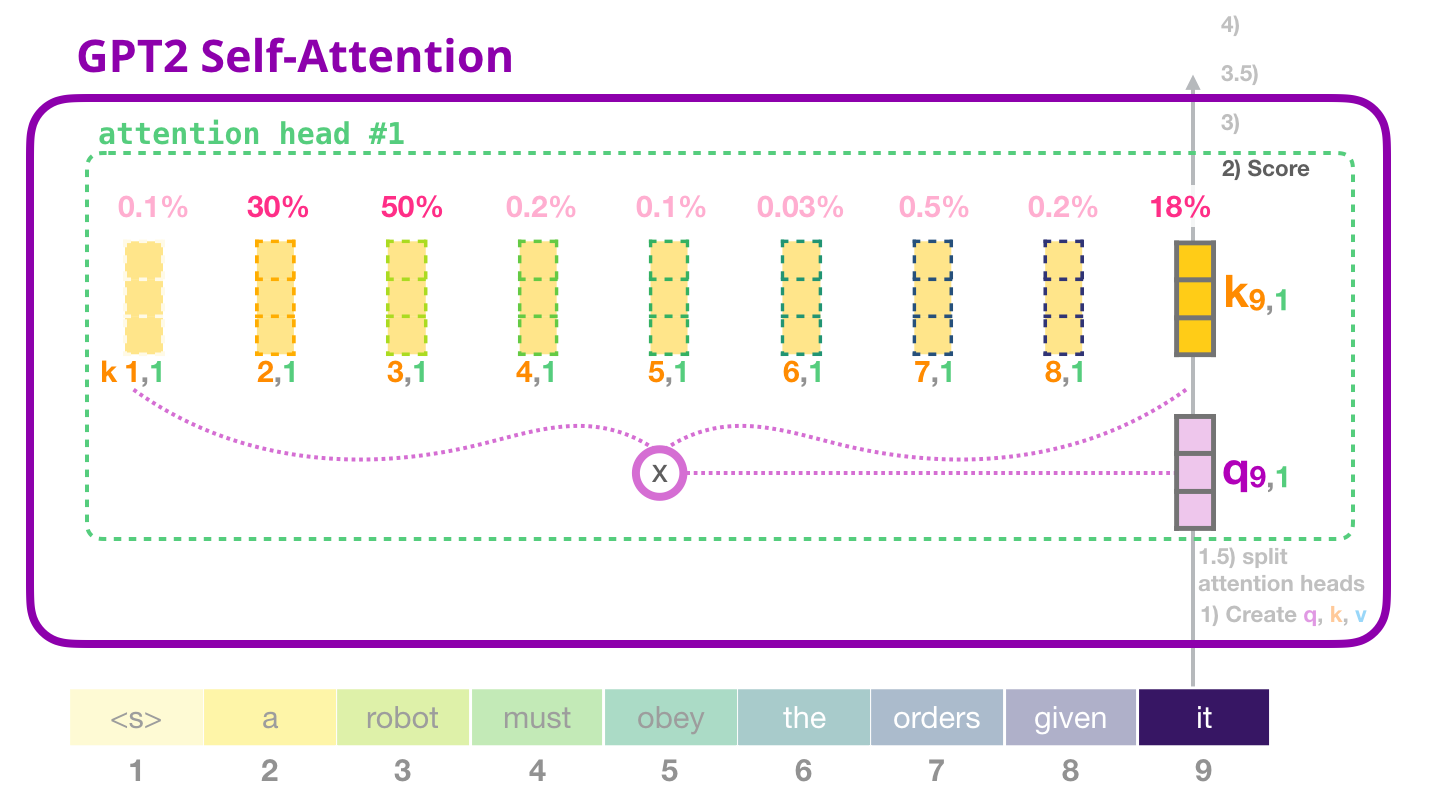
2.3.4 Etape 3 : Somme
Comme nous l’avons vu précédemment, nous multiplions maintenant chaque valeur par son score, puis nous les additionnons pour obtenir le résultat de l’attention portée à la tête d’attention n°1 :
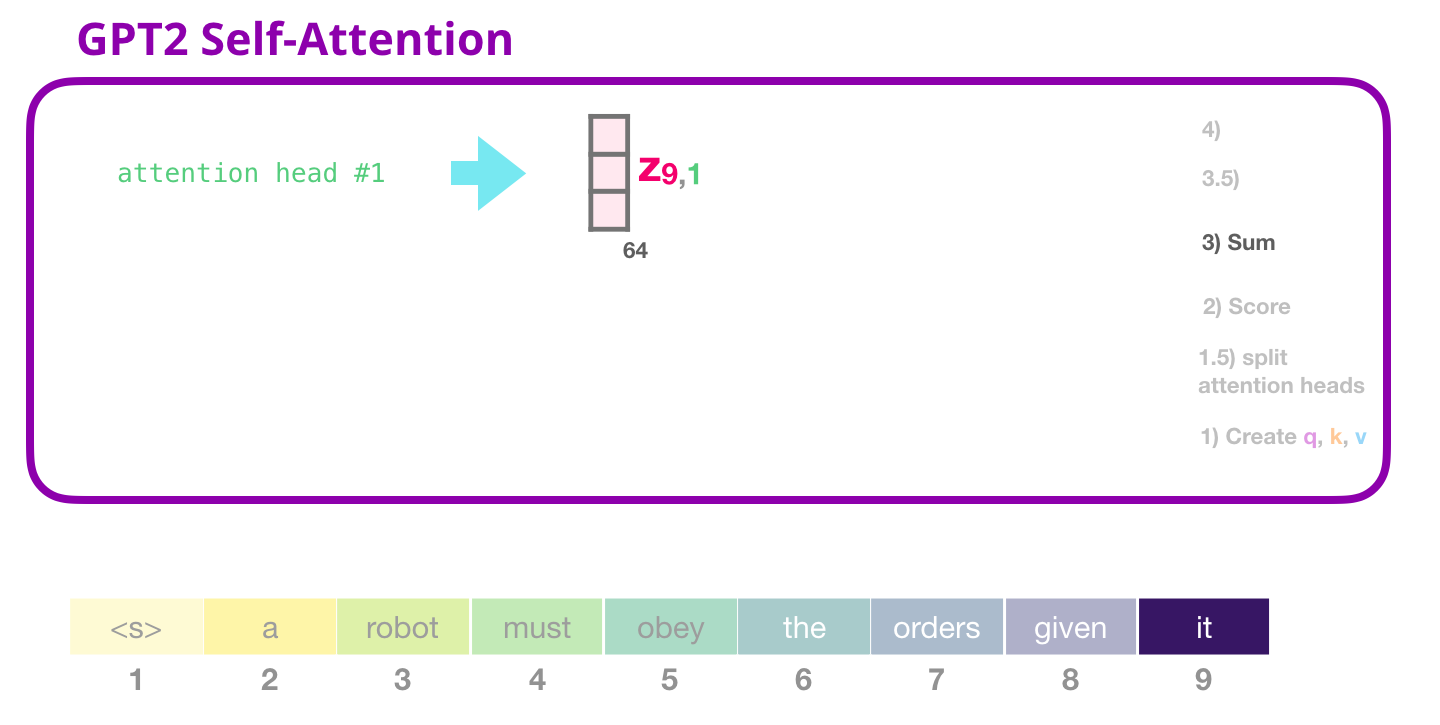
2.3.5 Etape 3.5 : Fusion des têtes d’attention
Nous concaténons les têtes d’attention.
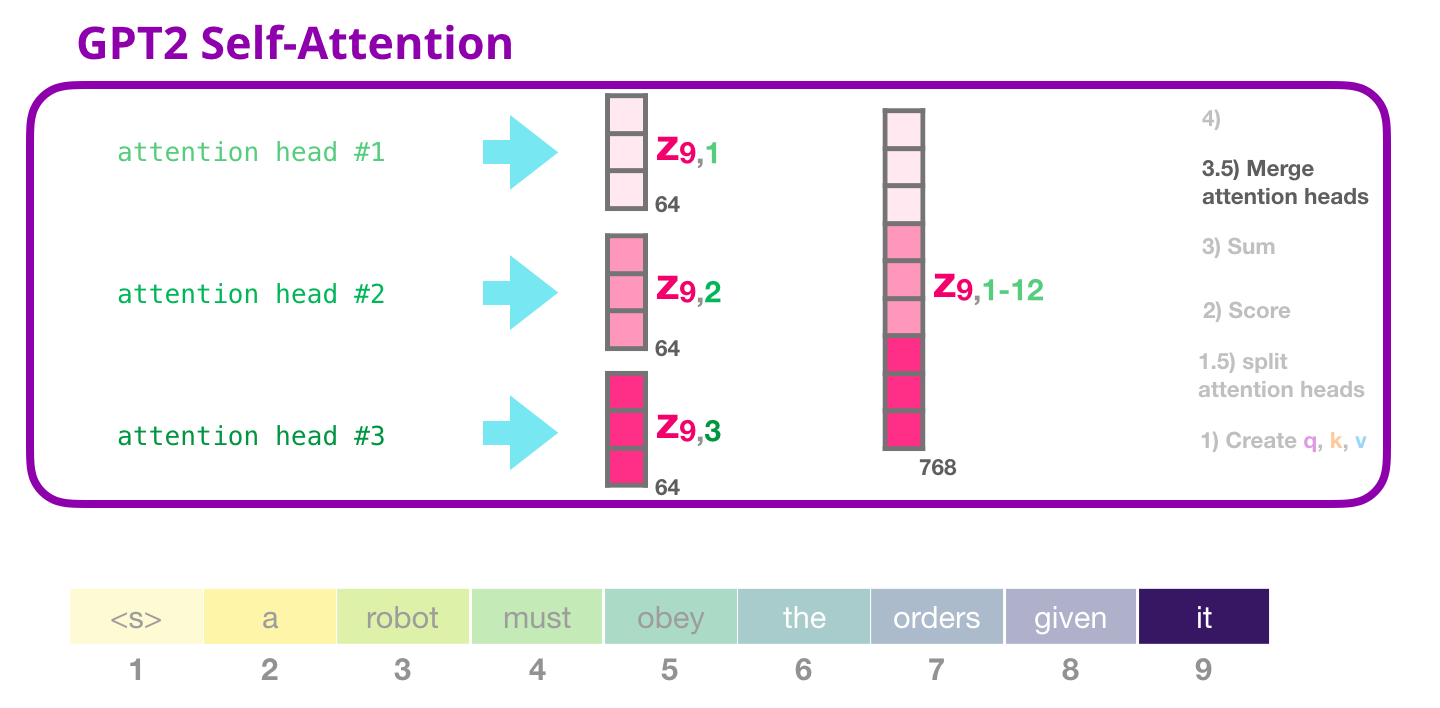
2.3.6 Etape 4 : Projection
Voici notre deuxième grande matrice de poids qui projette les résultats des têtes d’attention dans le vecteur de sortie de la sous-couche d’auto-attention :
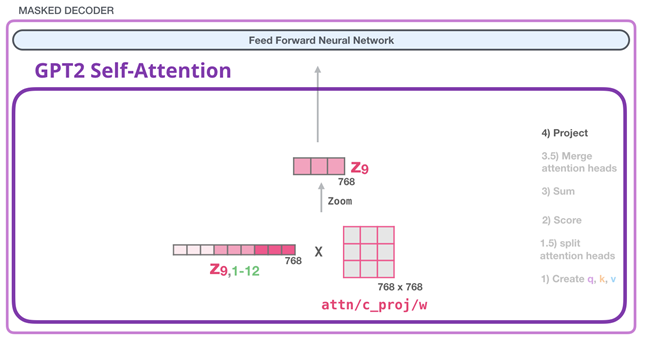
2.3.7 Etape 5 : Réseau de neurones entièrement conecté
Le réseau neuronal entièrement connecté est l’endroit où le bloc traite son token d’entrée après que l’auto-attention a inclus le contexte approprié dans sa représentation. Il est composé de deux couches.
La première couche est quatre fois plus grande que le modèle (768x4 = 3072). Pourquoi quatre fois ? Nous reprenons ici la taille utilisée dans l’article original du transformer (la dimension du modèle était 512 et la couche #1 dans ce modèle était 2048). Cela semble donner aux transformers une capacité de représentation suffisante pour faire face aux tâches qui leur ont été confiées jusqu’à présent.
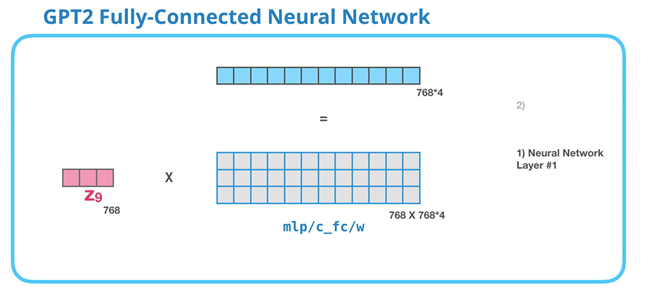
La deuxième couche projette le résultat de la première couche dans la dimension du modèle (768 pour le petit GPT2). Le résultat de cette multiplication est le résultat du bloc pour ce token.
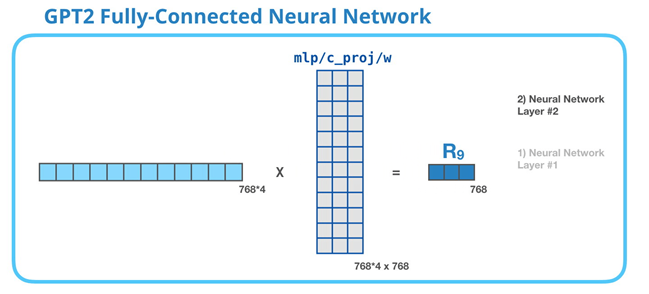
Le token « it » est à présent terminé !
2.3.8 Résumé
Pour résumer, notre vecteur d’entrée rencontre ces matrices de poids :
Chaque bloc a son propre jeu de ces poids. D’autre part, le modèle n’a qu’une seule matrice d’enchâssement et une seule matrice d’encodage positionnel :
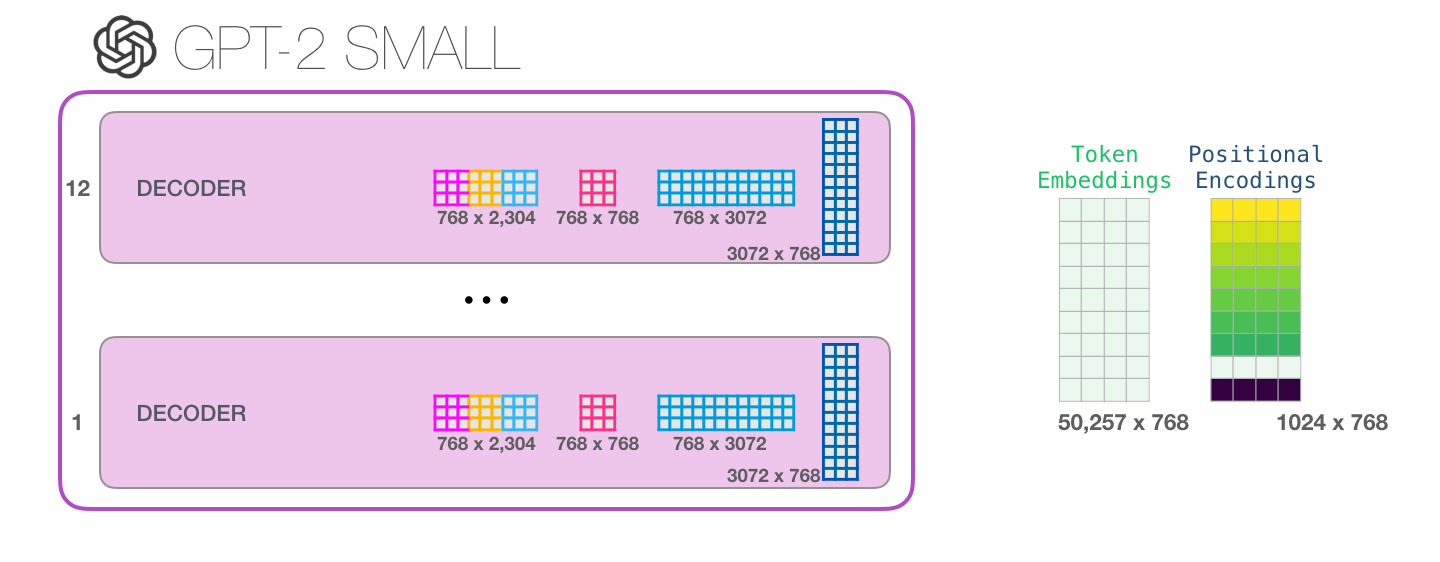
Si vous voulez calculer tous les paramètres du modèle :
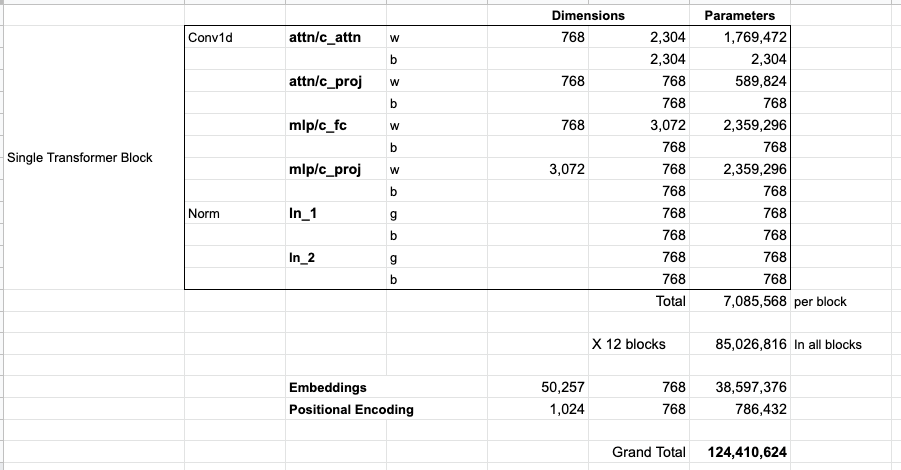
3. Autres tâches que la modélisation linguistique
Le transformer avec seulement des décodeurs a fait ses preuves dans beaucoup d’applications autre que la modélisation du langage. Terminons cet article en regardant certaines de ces applications.
3.1 La traduction automatique
Un encodeur n’est pas nécessaire pour effectuer une traduction :
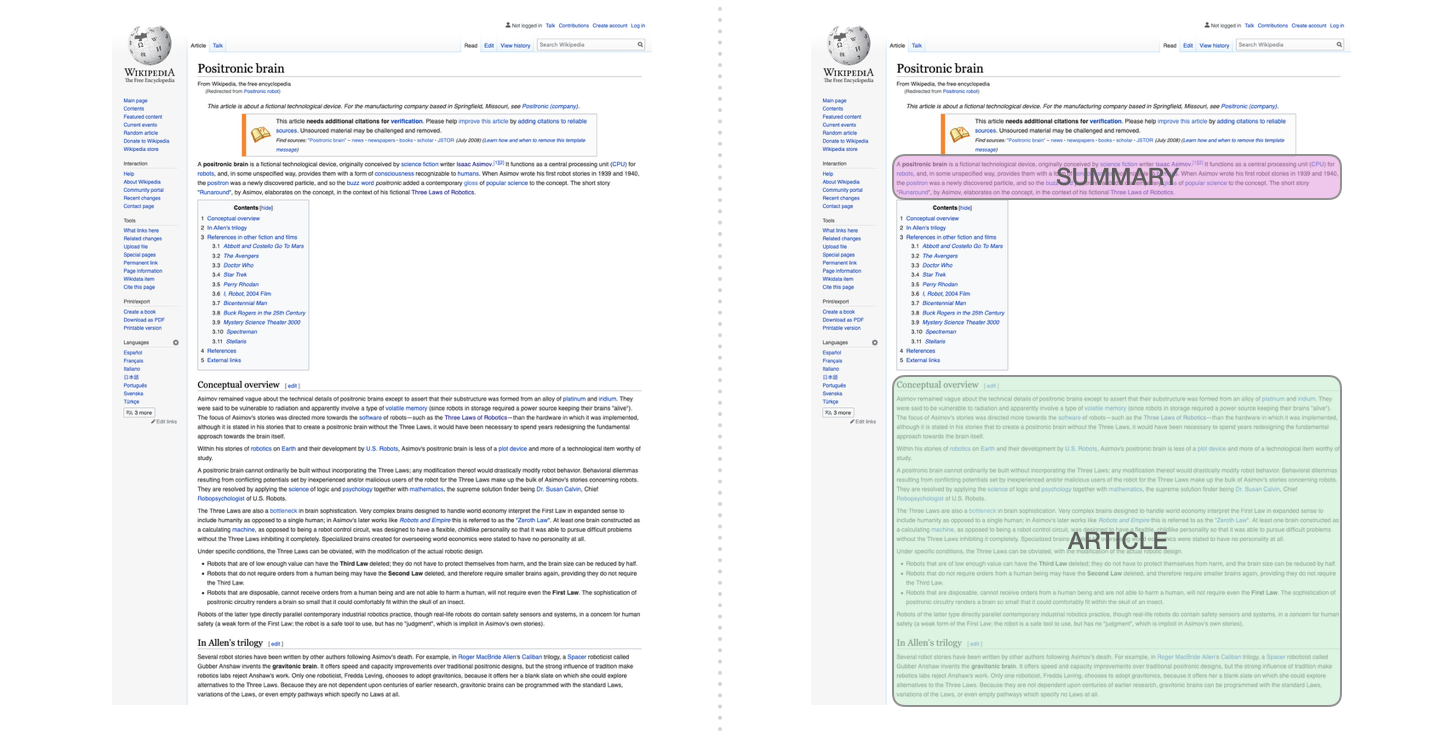
3.2 Résumé d’un texte
C’est sur cette tâche qu’a été entraîné le premier transformer basé uniquement sur la partie décodeur. A savoir lire un article de Wikipedia (sans la section d’introduction devant la table des matières) et à le résumer. Les sections d’introduction réelles des articles ont été utilisées comme label dans les données d’entraînement :
3.3 Apprentissage par transfert
Dans Sample Efficient Text Summarization Using a Single Pre-Trained Transformer, un Transformer-Décodeur est d’abord pré-entrainé à la modélisation linguistique puis finetuné pour faire le résumé. Il s’avère que cela permet d’obtenir de meilleurs résultats qu’un Transformer encodeur-décodeur pré-entrainé.
Le papier du GPT2 montre également les résultats de tache de résumé après avoir pré-entraîné le modèle à la modélisation du langage.
3.4 Génération de musique
Le Music Transformer utilise un Transformer-Décodeur pour générer de la musique avec un timing et une dynamique expressifs. La modélisation musicale est comme la modélisation du langage : il suffit de laisser le modèle apprendre la musique d’une manière auto-supervisée puis de lui faire échantillonner les sorties.
Vous pourriez être curieux de savoir comment la musique est représentée dans ce scénario. Rappelez-vous que la modélisation du langage peut se faire au moyen de représentations vectorielles de caractères, de mots ou de tokens qui font partie des mots. Avec un extrait de piano par exemple, nous devons représenter les notes mais aussi la vélocité (une mesure de la force avec laquelle la touche du piano est pressée).
Un extrait de musique n’est qu’une série de ces vecteurs d’un seul coup. L’exemple suivant illustre la séquence d’entrée :

La représentation vectorielle one-hot de cette séquence d’entrée ressemble à ceci :
Un exemple de représentation de l’auto-attention du Music Transformer :
Conclusion
J’espère que cet article vous aura permis de vous familiariser avec le GPT-2.
Voici quelques liens qui pourraient vous être utiles :
- les outils développés par Hugging Face, à savoir le générateur de textes et le chatbox,
- un tutoriel en anglais de Max Woolf pour créer un bot twitter générant du texte,
- le code du GPT2 annoté en anglais par Aman Arora,
- une présentation vidéo où j’explique comment à l’INSERM, nous utilisons le GPT2 afin d’effectuer de la classification.
Références
- The Illustrated GPT-2 (Visualizing Transformer Language Models) de Jay Alammar (2019)
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context de et al. (2019)
- XLNet: Generalized Autoregressive Pretraining for Language Understanding de Yang et al. (2019)
- Music Transformer: Generating Music with Long-Term Structure de Huang et al. (2018)
- Sample Efficient Text Summarization Using a Single Pre-Trained Transformer de Khandelwal et al. (2019)
- Generating Wikipedia by Summarizing Long Sequences de Liu et al. (2018)
- Improving Language Understandingby Generative Pre-Training de Radford et al. (2018)
- Language Models are Unsupervised Multitask Learners de Radford et al. (2019)
- Attention Is All You Need de Vaswani et al. (2017)
Citation
@inproceedings{gpt2_blog_post,
author = {Loïck BOURDOIS},
title = {Illustration du GPT2},
year = {2019},
url = {https://lbourdois.github.io/blog/nlp/GPT2/}
}