Diffusion pour l'audio
Dans ce notebook, nous allons jeter un bref coup d’œil à la génération d’audio avec des modèles de diffusion. Ce que vous allez apprendre :
- Comment l’audio est représenté dans un ordinateur
- Les méthodes de conversion entre les données audio brutes et les spectrogrammes
- Comment préparer un chargeur de données avec une fonction personnalisée pour convertir des tranches d’audio en spectrogrammes
- Finetuner un modèle de diffusion audio existant sur un genre de musique spécifique
- Télécharger votre pipeline personnalisé sur le Hub d’Hugging Face
Mise en garde : il s’agit principalement d’un objectif pédagogique - rien ne garantit que notre modèle sonnera bien 😉
Commençons !
Configuration et importations
# !pip install -q datasets diffusers torchaudio accelerate
import torch, random
import numpy as np
import torch.nn.functional as F
from tqdm.auto import tqdm
from IPython.display import Audio
from matplotlib import pyplot as plt
from diffusers import DiffusionPipeline
from torchaudio import transforms as AT
from torchvision import transforms as IT
Echantillonnage à partir d’un pipeline audio pré-entraîné
Commençons par suivre la documentation pour charger un modèle de diffusion audio préexistant :
# Chargement d'un pipeline de diffusion audio pré-entraîné
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-instrumental-hiphop-256").to(device)
Comme pour les pipelines que nous avons utilisés dans les unités précédentes, nous pouvons créer des échantillons en appelant le pipeline comme suit :
# Échantillonner à partir du pipeline et afficher les résultats
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))

Ici, l’argument rate spécifie la fréquence d’échantillonnage de l’audio ; nous y reviendrons plus tard. Vous remarquerez également que le pipeline renvoie plusieurs choses. Que se passe-t-il ici ? Examinons de plus près les deux sorties.
La première est un tableau de données, représentant l’audio généré :
# Le tableau audio :
output.audios[0].shape
(1, 130560)
La seconde ressemble à une image en niveaux de gris :
# L'image de sortie (spectrogramme)
output.images[0].size
(256, 256)
Cela nous donne un aperçu du fonctionnement de ce pipeline. L’audio n’est pas directement généré par diffusion. Au lieu de cela, le pipeline a le même type d’UNet 2D que les pipelines de génération d’images inconditionnelles que nous avons vus dans l’unité 1, qui est utilisé pour générer le spectrogramme, qui est ensuite post-traité dans l’audio final.
Le pipeline possède un composant supplémentaire qui gère ces conversions, auquel nous pouvons accéder via pipe.mel :
pipe.mel
Mel {
"_class_name": "Mel",
"_diffusers_version": "0.12.0.dev0",
"hop_length": 512,
"n_fft": 2048,
"n_iter": 32,
"sample_rate": 22050,
"top_db": 80,
"x_res": 256,
"y_res": 256
}
De l’audio à l’image et inversement
Une « forme d’onde » encode les échantillons audio bruts dans le temps. Il peut s’agir du signal électrique reçu d’un microphone, par exemple. Travailler avec cette représentation du « domaine temporel » peut s’avérer délicat, c’est pourquoi il est courant de la convertir sous une autre forme, communément appelée spectrogramme. Un spectrogramme montre l’intensité de différentes fréquences (axe y) en fonction du temps (axe x) :
# Calculer et afficher un spectrogramme pour notre échantillon audio généré en utilisant torchaudio
spec_transform = AT.Spectrogram(power=2)
spectrogram = spec_transform(torch.tensor(output.audios[0]))
print(spectrogram.min(), spectrogram.max())
log_spectrogram = spectrogram.log()
plt.imshow(log_spectrogram[0], cmap='gray');
tensor(0.) tensor(6.0842)
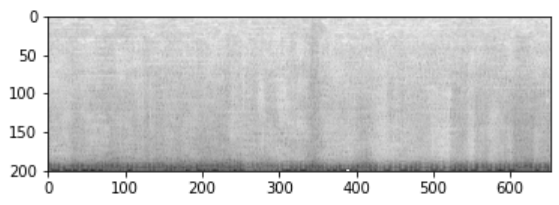
Le spectrogramme que nous venons de créer contient des valeurs comprises entre 0,0000000000001 et 1, la plupart d’entre elles étant proches de la limite inférieure de cette plage. Ce n’est pas l’idéal pour la visualisation ou la modélisation. En fait, nous avons dû prendre le logarithme de ces valeurs pour obtenir un tracé en niveaux de gris qui montre des détails. Pour cette raison, nous utilisons généralement un type spécial de spectrogramme appelé Mel spectrogramme, qui est conçu pour capturer les types d’informations qui sont importantes pour l’audition humaine en appliquant certaines transformations aux différentes composantes de fréquence du signal.
Quelques transformations audio de la documentation torchaudio
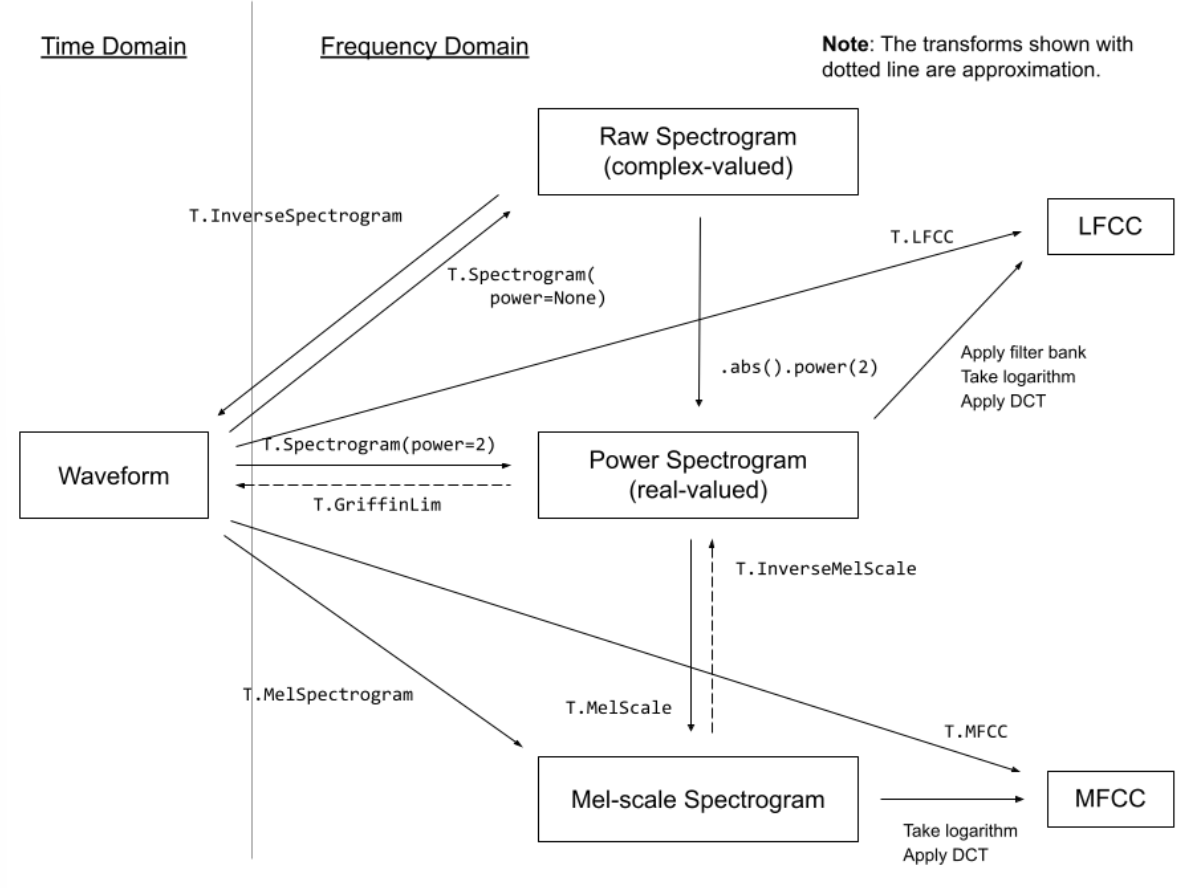
Heureusement pour nous, nous n’avons pas besoin de nous préoccuper de ces transformations, la fonctionnalité mel du pipeline s’occupe de ces détails pour nous. En l’utilisant, nous pouvons convertir une image de spectrogramme en audio comme suit :
a = pipe.mel.image_to_audio(output.images[0])
a.shape
(130560,)
Nous pouvons également convertir un tableau de données audio en images de spectrogramme en chargeant d’abord les données audio brutes, puis en appelant la fonction audio_slice_to_image(). Les clips plus longs sont automatiquement découpés en morceaux de la bonne longueur pour produire une image de spectrogramme de 256x256 :
pipe.mel.load_audio(raw_audio=a)
im = pipe.mel.audio_slice_to_image(0)
im

L’audio est représenté sous la forme d’un long tableau de nombres. Pour l’écouter nous avons besoin d’une autre information clé : la fréquence d’échantillonnage. Combien d’échantillons (valeurs individuelles) utilisons-nous pour représenter une seconde d’audio ?
Nous pouvons voir la fréquence d’échantillonnage utilisée lors de l’entraînement de ce pipeline avec :
sample_rate_pipeline = pipe.mel.get_sample_rate()
sample_rate_pipeline
22050
Si nous spécifions mal la fréquence d’échantillonnage, nous obtenons un son accéléré ou ralenti :
display(Audio(output.audios[0], rate=44100)) # Vitesse x2
Finetuning du pipeline
Maintenant que nous avons une compréhension approximative du fonctionnement du pipeline, nous allons le finetuner sur de nouvelles données audio !
Le jeu de données est une collection de clips audio de différents genres, que nous pouvons charger depuis le Hub de la manière suivante :
from datasets import load_dataset
dataset = load_dataset('lewtun/music_genres', split='train')
dataset
Dataset({
features: ['audio', 'song_id', 'genre_id', 'genre'],
num_rows: 19909
})
Vous pouvez utiliser le code ci-dessous pour voir les différents genres dans le jeu de données et combien d’échantillons sont contenus dans chacun d’eux :
for g in list(set(dataset['genre'])):
print(g, sum(x==g for x in dataset['genre']))
Pop 945
Blues 58
Punk 2582
Old-Time / Historic 408
Experimental 1800
Folk 1214
Electronic 3071
Spoken 94
Classical 495
Country 142
Instrumental 1044
Chiptune / Glitch 1181
International 814
Ambient Electronic 796
Jazz 306
Soul-RnB 94
Hip-Hop 1757
Easy Listening 13
Rock 3095
Le jeu de données contient les données audio sous forme de tableaux :
audio_array = dataset[0]['audio']['array']
sample_rate_dataset = dataset[0]['audio']['sampling_rate']
print('Audio array shape:', audio_array.shape)
print('Sample rate:', sample_rate_dataset)
display(Audio(audio_array, rate=sample_rate_dataset))
Audio array shape: (1323119,)
Sample rate: 44100
Notez que la fréquence d’échantillonnage de cet audio est plus élevée. Si nous voulons utiliser le pipeline existant, nous devrons le « rééchantillonner » pour qu’il corresponde à la fréquence d’échantillonnage. Les clips sont également plus longs que ceux pour lesquels le pipeline est configuré. Heureusement, lorsque nous chargeons l’audio à l’aide de pipe.mel, il découpe automatiquement le clip en sections plus petites :
a = dataset[0]['audio']['array'] # Obtenir le tableau audio
pipe.mel.load_audio(raw_audio=a) # Le charger avec pipe.mel
pipe.mel.audio_slice_to_image(0) # Visualiser la première "tranche" sous forme de spectrogramme

Nous devons penser à ajuster le taux d’échantillonnage, car les données de ce jeu de données comportent deux fois plus d’échantillons par seconde :
sample_rate_dataset = dataset[0]['audio']['sampling_rate']
sample_rate_dataset
44100
Ici, nous utilisons les transformations de torchaudio (importées sous le nom AT) pour effectuer le rééchantillonnage, le pipeline mel pour transformer l’audio en image et les transformations de torchvision (importées sous le nom IT) pour transformer les images en tenseurs. Nous obtenons ainsi une fonction qui transforme un clip audio en un tenseur de spectrogramme que nous pouvons utiliser pour nous entraîner :
resampler = AT.Resample(sample_rate_dataset, sample_rate_pipeline, dtype=torch.float32)
to_t = IT.ToTensor()
def to_image(audio_array):
audio_tensor = torch.tensor(audio_array).to(torch.float32)
audio_tensor = resampler(audio_tensor)
pipe.mel.load_audio(raw_audio=np.array(audio_tensor))
num_slices = pipe.mel.get_number_of_slices()
slice_idx = random.randint(0, num_slices-1) # Piocher une tranche aléatoire à chaque fois (à l'exception de la dernière tranche courte)
im = pipe.mel.audio_slice_to_image(slice_idx)
return im
Nous utiliserons notre fonction to_image() dans le cadre d’une fonction collate personnalisée pour transformer notre jeu de données en un chargeur de données utilisable pour l’entraînement. La fonction collate définit la manière de transformer un batch d’exemples du jeu de données en un batch final de données prêtes à être entraînées. Dans ce cas, nous transformons chaque échantillon audio en une image de spectrogramme et nous empilons les tenseurs résultants :
def collate_fn(examples):
# vers l'image -> vers le tenseur -> redimensionnement vers (-1, 1) -> empiler dans le batch
audio_ims = [to_t(to_image(x['audio']['array']))*2-1 for x in examples]
return torch.stack(audio_ims)
# Créer un jeu de données avec uniquement le genre de chansons 'Chiptune / Glitch'
batch_size=4 # 4 sur Colab, 12 sur A100
chosen_genre = 'Electronic' # <<< Essayer d'entraîner sur des genres différents <<<
indexes = [i for i, g in enumerate(dataset['genre']) if g == chosen_genre]
filtered_dataset = dataset.select(indexes)
dl = torch.utils.data.DataLoader(filtered_dataset.shuffle(), batch_size=batch_size, collate_fn=collate_fn, shuffle=True)
batch = next(iter(dl))
print(batch.shape)
torch.Size([4, 1, 256, 256])
NB : Vous devrez utiliser une taille de batch inférieure (par exemple 4) à moins que vous ne disposiez d’une grande quantité de vRAM GPU.
Boucle d’entraînement
Voici une boucle d’entraînement simple qui s’exécute à travers le chargeur de données pour quelques époques afin de finetuner le pipeline UNet. Vous pouvez également ignorer cette cellule et charger le pipeline avec le code de la cellule suivante.
epochs = 3
lr = 1e-4
pipe.unet.train()
pipe.scheduler.set_timesteps(1000)
optimizer = torch.optim.AdamW(pipe.unet.parameters(), lr=lr)
for epoch in range(epochs):
for step, batch in tqdm(enumerate(dl), total=len(dl)):
# Préparer les images d'entrée
clean_images = batch.to(device)
bs = clean_images.shape[0]
# Échantillonner un pas de temps aléatoire pour chaque image
timesteps = torch.randint(
0, pipe.scheduler.num_train_timesteps, (bs,), device=clean_images.device
).long()
# Ajouter du bruit aux images propres en fonction de l'ampleur du bruit à chaque étape
noise = torch.randn(clean_images.shape).to(clean_images.device)
noisy_images = pipe.scheduler.add_noise(clean_images, noise, timesteps)
# Obtenir la prédiction du modèle
noise_pred = pipe.unet(noisy_images, timesteps, return_dict=False)[0]
# Calculer la perte
loss = F.mse_loss(noise_pred, noise)
loss.backward(loss)
# Mise à jour des paramètres du modèle à l'aide de l'optimiseur
optimizer.step()
optimizer.zero_grad()
# OU : Charger la version entraînée précédemment
pipe = DiffusionPipeline.from_pretrained("johnowhitaker/Electronic_test").to(device)
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=22050))

# Créer un échantillon plus long en passant un tenseur de bruit de départ avec une forme différente
noise = torch.randn(1, 1, pipe.unet.sample_size[0],pipe.unet.sample_size[1]*4).to(device)
output = pipe(noise=noise)
display(output.images[0])
display(Audio(output.audios[0], rate=22050))

Ce ne sont pas les résultats les plus impressionnants mais c’est un début :) Essayez d’ajuster le taux d’apprentissage et le nombre d’époques, et partagez vos meilleurs résultats sur Discord pour que nous puissions nous améliorer ensemble !
Quelques éléments à prendre en compte
- Nous travaillons avec des images de spectrogrammes carrés de 256 pixels ce qui limite la taille de nos batchs. Pouvez-vous récupérer de l’audio de qualité suffisante à partir d’un spectrogramme de 128x128 ?
- Au lieu d’une augmentation aléatoire de l’image, nous choisissons à chaque fois des tranches différentes du clip audio, mais cela pourrait-il être amélioré avec différents types d’augmentation lorsque l’on s’entraîne pendant de nombreuses époques ?
- Comment pourrions-nous utiliser cette méthode pour générer des clips plus longs ? Peut-être pourriez-vous générer un clip de départ de 5 secondes, puis utiliser des idées inspirées de la complétion d’images (inpainting) pour continuer à générer des segments audio supplémentaires à partir du clip initial…
- Quel est l’équivalent d’une image à image dans ce contexte de diffusion de spectrogrammes ?
Pousser sur le Hub
Une fois que vous êtes satisfait de votre modèle, vous pouvez le sauvegarder et le transférer sur le Hub pour que d’autres personnes puissent en profiter :
from huggingface_hub import get_full_repo_name, HfApi, create_repo, ModelCard
# Choisir un nom pour le modèle
model_name = "audio-diffusion-electronic"
hub_model_id = get_full_repo_name(model_name)
# Sauvegarder le pipeline localement
pipe.save_pretrained(model_name)
# Inspecter le contenu du dossier
!ls {model_name}
mel model_index.json scheduler unet
# Créer un dépôt
create_repo(hub_model_id)
# Télécharger les fichiers
api = HfApi()
api.upload_folder(
folder_path=f"{model_name}/scheduler", path_in_repo="scheduler", repo_id=hub_model_id
)
api.upload_folder(
folder_path=f"{model_name}/mel", path_in_repo="mel", repo_id=hub_model_id
)
api.upload_folder(folder_path=f"{model_name}/unet", path_in_repo="unet", repo_id=hub_model_id)
api.upload_file(
path_or_fileobj=f"{model_name}/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id,
)
# Pousser une carte de modèle
content = f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-audio-generation
- diffusion-models-class
---
# Model Card for Unit 4 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional audio generation of music in the genre {chosen_genre}
## Usage
```python
from IPython.display import Audio
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("{hub_model_id}")
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
```python
"""
card = ModelCard(content)
card.push_to_hub(hub_model_id)
Conclusion
Ce notebook vous a donné, nous l’espérons, un petit aperçu du potentiel de la génération audio. Consultez certaines des références liées à la vue d’ensemble de cette unité pour voir des méthodes plus fantaisistes et des échantillons stupéfiants qu’elles peuvent créer !