Sprint ControlNet en JAX/Diffusers
Bienvenue au sprint communautaire en JAX/Diffusers ! L’objectif de ce sprint est de travailler sur des modèles de diffusion amusants et créatifs en utilisant JAX et Diffusers.
Lors de cet événement, nous créerons diverses applications avec des modèles de diffusion en JAX/Flax et Diffusers en utilisant des heures TPU gratuites généreusement fournies par Google Cloud.
Ce document présente toutes les informations importantes pour faire une soumission au sprint.
Organisation
Les participants peuvent proposer des idées pour un projet intéressant impliquant des modèles de diffusion. Des équipes de 3 à 5 personnes seront ensuite formées autour des projets les plus prometteurs et les plus intéressants. Assurez-vous de lire la section Communication pour savoir comment proposer des projets, commenter les idées de projet des autres participants et créer une équipe.
Pour aider chaque équipe à mener à bien son projet, nous organiserons des conférences données par des scientifiques et des ingénieurs de Google, de Hugging Face et de la communauté open source. Les conférences auront lieu le 17 avril. Assurez-vous d’assister aux conférences pour tirer le meilleur parti de votre participation ! Consultez la section Conférences pour avoir une vue d’ensemble des conférences, y compris l’orateur et l’heure de la conférence.
Chaque équipe bénéficiera ensuite d’un accès gratuit à une VM TPU v4-8 du 14 avril au 1er mai. De plus, nous fournirons un exemple d’entraînement en JAX/Flax et Diffusers pour entraîner un ControlNet afin de lancer votre projet. Nous fournirons également des exemples sur la façon de préparer les jeux de données. Pendant le sprint, nous nous assurerons de répondre à toutes les questions que vous pourriez avoir sur JAX/Flax et Diffusers et nous aiderons chaque équipe autant que possible !
Nous ne distribuerons pas de TPU pour les équipes composées d’un seul membre. Nous vous encourageons donc à rejoindre une équipe ou à trouver des coéquipiers pour votre idée.
À la fin du sprint, chaque soumission sera évaluée par un jury et les trois meilleures démonstrations recevront un prix. Consultez la section Comment soumettre une démo pour plus d’informations et de suggestions sur la manière de soumettre votre projet.
Note : Même si nous fournissons un exemple pour entraîner ControlNet, les participants peuvent proposer des idées qui n’impliquent pas du tout un ControlNet du moment qu’elles sont centrées sur les modèles de diffusion.
Dates importantes
- 29/03 : Annonce officielle de la semaine de la communauté.
- 31/03 : Commencez à former des groupes dans le canal #jax-diffusers-ideas sur Discord.
- 10/04 : Collecte des données.
- 13/04 & 14/04 & 17/04 : Conférences de lancement sur YouTube.
- 14/04 à 17/04 : Début de l’accès aux TPU.
- 01/05 : Fermeture de l’accès aux TPU.
- 08/05 : Annonce des 10 meilleurs projets et des prix.
Note : Nous accepterons les candidatures tout au long du sprint.
Communication
Toutes les communications importantes auront lieu sur notre serveur Discord. Rejoignez le serveur en utilisant ce lien. Après avoir rejoint le serveur, prenez le rôle Diffusers dans le canal #role-assignment et dirigez-vous vers le canal #jax-diffusers-ideas pour partager votre idée sous la forme d’un message de forum. Pour vous inscrire, remplissez le formulaire d’inscription et nous vous donnerons accès à deux canaux Discord supplémentaires pour les discussions et le support technique, ainsi qu’un accès aux TPU.
Les annonces importantes de l’équipe Hugging Face, Flax/JAX et Google Cloud seront publiées sur le serveur.
Le serveur Discord sera le lieu central où les participants pourront publier leurs résultats, partager leurs expériences d’apprentissage, poser des questions et obtenir une assistance technique pour les divers obstacles qu’ils rencontrent.
Pour les problèmes liés à Flax/JAX, Diffusers, Datasets ou pour des questions spécifiques à votre projet, nous interagirons à travers les dépôts publics et les forums :
- Flax : Issues, Questions
- JAX : Issues, Questions
- 🤗 Diffusers : Issues, Questions
- 🤗 Dataset s: Issues, Questions
- Questions spécifiques aux projets : Elles peuvent être posées sur le canal #jax-diffusers-ideas sur Discord.
- Questions relatives au TPU : Canal
#jax-diffusers-tpu-supportsur Discord. - Discussion générale :
#jax-diffusers-sprint channelsur Discord. Vous aurez accès aux canaux#jax-diffusers-tpu-supportet#jax-diffusers-sprintune fois que vous aurez été accepté pour participer au sprint.
Lorsque vous demandez de l’aide, nous vous encourageons à poster le lien vers le forum sur le serveur Discord, plutôt que de poster directement des issues ou des questions. De cette façon, nous nous assurons que tout le monde peut bénéficier de vos questions, même après la fin du sprint.
Note :
Après le 10 avril, si vous vous êtes inscrit sur le formulaire Google, mais que vous n’êtes pas dans le canal Discord, veuillez laisser un message sur l’annonce officielle du forum et envoyer un ping à@mervenoyan,@sayakpaul, et@patrickvonplaten. Il se peut que nous prenions un jour pour traiter ces demandes.
Conférences
Nous avons invité d’éminents chercheurs et ingénieurs de Google, Hugging Face, et de la communauté open-source qui travaillent dans le domaine de l’IA générative. Nous mettrons à jour cette section avec des liens vers les conférences, alors gardez un œil ici ou sur Discord dans le canal diffusion models core-announcements et programmez vos rappels !
13 avril 2023
| Intervenant | Sujet | Horaire | Video |
|---|---|---|---|
| Emiel Hoogeboom, Google Brain | Pixel-Space Diffusion models for High Resolution Images | 4.00pm-4.40pm CEST / 7.00am-7.40am PST |  |
| Apolinário Passos, Hugging Face | Introduction to Diffusers library | 4.40pm-5.20pm CEST / 7.40am-08.20am PST | |
| Ting Chen, Google Brain | Diffusion++: discrete data and high-dimensional generation | 5.45pm-6.25pm CEST / 08.45am-09.25am PST | |
14 avril 2023
| Intervenant | Sujet | Horaire | Video |
|---|---|---|---|
| Tim Salimans, Google Brain | Efficient image and video generation with distilled diffusion models | 4.00pm-4.40pm CEST / 7.00am-7.40am PST | |
| Suraj Patil, Hugging Face | Masked Generative Models: MaskGIT/Muse | 4.40pm-5.20pm CEST / 7.40am-08.20am PST | |
| Sabrina Mielke, John Hopkins University | From stateful code to purified JAX: how to build your neural net framework | 5.20pm-6.00pm CEST / 08.20am-09.00am PST | |
17 avril 2023
| Intervenant | Sujet | Horaire | Video |
|---|---|---|---|
| Andreas Steiner, Google Brain | JAX & ControlNet | 4.00pm-4.40pm CEST / 7.00am-7.40am PST | |
| Boris Dayma, craiyon | DALL-E Mini | 4.40pm-5.20pm CEST / 7.40am-08.20am PST | |
| Margaret Mitchell, Hugging Face | Ethics of Text-to-Image | 5.20pm-6.00pm CEST / 08.20am-09.00am PST | |
Données et prétraitement
Dans cette section, nous verrons comment construire votre propre jeu de données pour entraîner ControlNet.
Préparer un grand jeu de données local
Monter un disque
Si vous avez besoin d’espace supplémentaire, vous pouvez suivre ce guide pour créer un disque persistant, l’attacher à votre VM TPU et créer un répertoire pour monter le disque. Vous pouvez ensuite utiliser ce répertoire pour stocker votre jeu de données.
Par ailleurs, la VM TPU attribuée à votre équipe dispose d’un disque de stockage persistant de 3 To. Pour apprendre à l’utiliser, consultez ce guide.
Prétraitement des données
Nous montrons ici comment préparer un grand jeu de données pour entraîner un modèle ControlNet avec filtre de Canny. Plus précisément, nous fournissons un exemple de script qui :
- Sélectionne 1 million de paires image-texte à partir d’un jeu de données existant COYO-700M.
- Télécharge chaque image et utilise le filtre de Canny pour générer l’image de conditionnement.
- Crée un métafichier qui relie toutes les images et les images traitées à leurs légendes.
Utilisez la commande suivante pour exécuter le script de prétraitement des données de l’exemple. Si vous avez monté un disque sur votre TPU, vous devez placer vos fichiers train_data_dir et cache_dir sur le disque monté.
python3 coyo_1m_dataset_preprocess.py \
--train_data_dir="/mnt/disks/persist/data" \
--cache_dir="/mnt/disks/persist" \
--max_train_samples=1000000 \
--num_proc=16
Une fois le script exécuté, vous trouverez un dossier de données dans le répertoire train_data_dir spécifié avec la structure de dossier ci-dessous :
data
├── images
│ ├── image_1.png
│ ├── .......
│ └── image_1000000.jpeg
├── processed_images
│ ├── image_1.png
│ ├── .......
│ └── image_1000000.jpeg
└── meta.jsonl
Charger un jeu de données
Pour charger un jeu de données à partir du dossier de données que vous venez de créer, vous devez ajouter un script de chargement de jeu de données à votre dossier de données. Le script de chargement de données doit porter le même nom que le dossier. Par exemple, si votre dossier de données est data, vous devez ajouter un script de chargement de données nommé data.py. Nous fournissons un exemple de script de chargement de données que vous pouvez utiliser. Tout ce que vous avez à faire est de mettre à jour le DATA_DIR avec le chemin correct de votre dossier de données. Pour plus de détails sur l’écriture d’un script de chargement de données, reportez-vous à la documentation.
Une fois que le script de chargement de données est ajouté à votre dossier de données, vous pouvez le charger avec :
dataset = load_dataset("/mnt/disks/persist/data", cache_dir="/mnt/disks/persist" )
Notez que vous pouvez utiliser --train_data_dir pour passer le répertoire de votre dossier de données au script d’entraînement et générer votre jeu de données automatiquement pendant l’entraînement.
Pour les grands jeux de données, nous recommandons de générer le jeu de données une seule fois et de le sauvegarder sur le disque à l’aide de la commande
dataset.save_to_disk("/mnt/disks/persist/dataset")
Vous pouvez ensuite réutiliser le jeu de données sauvegardé pour votre entraînement en passant --load_from_disk.
Voici un exemple d’exécution d’un script d’entraînement qui chargera le jeu de données depuis le disque.
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/mnt/disks/persist/canny_model"
export DATASET_DIR="/mnt/disks/persist/dataset"
export DISK_DIR="/mnt/disks/persist"
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--train_data_dir=$DATASET_DIR \
--load_from_disk \
--cache_dir=$DISK_DIR \
--resolution=512 \
--learning_rate=1e-5 \
--train_batch_size=2 \
--revision="non-ema" \
--from_pt \
--max_train_steps=500000 \
--checkpointing_steps=10000 \
--dataloader_num_workers=16
Préparer un jeu de données avec MediaPipe et Hugging Face
Nous fournissons un notebook qui vous montre comment préparer un jeu de données pour entraîner ControlNet en utilisant MediaPipe et Hugging Face. Plus précisément, dans le notebook, nous montrons :
- Comment tirer parti des solutions MediaPipe pour extraire les articulations du corps de la pose à partir des images d’entrée.
- Prédire les légendes en utilisant BLIP-2 à partir des images d’entrée en utilisant 🤗 Transformers.
- Construire et pousser le jeu de données final vers le Hugging Face Hub en utilisant 🤗 Datasets.
Vous pouvez vous référer au notebook pour créer vos propres jeux de données en utilisant d’autres solutions MediaPipe. Ci-dessous, nous listons toutes les solutions pertinentes :
Entraîner ControlNet
C’est peut-être la partie la plus amusante et la plus intéressante de ce document, car nous vous montrons ici comment entraîner un modèle ControlNet personnalisé.
Note :
Pour ce sprint, vous n’êtes PAS limité à entraîner des ControlNets. Nous fournissons ce script d’entraînement comme référence pour vous permettre de démarrer.
Pour un entraînement plus rapide sur les TPU et les GPU, vous pouvez tirer parti de l’exemple d’entraînement Flax. Suivez les instructions ci-dessus pour obtenir le modèle et le jeu de données avant d’exécuter le script.
Mise en place de la VM TPU
Avant de continuer avec le reste de cette section, vous devez vous assurer que l’adresse email que vous utilisez a été ajoutée au projet hf-flax sur Google Cloud Platform. Si ce n’est pas le cas, merci de nous le faire savoir sur le serveur Discord (vous pouvez taguer @sayakpaul, @merve, et @patrickvonplaten).
Dans ce qui suit, nous allons décrire comment le faire en utilisant une console standard, mais vous devriez également être en mesure de vous connecter à la VM TPU via des IDE, comme Visual Studio Code, etc.
-
Vous devez installer le Google Cloud SDK. Veuillez suivre les instructions sur https://cloud.google.com/sdk.
-
Une fois le Google Cloud SDK installé, vous devez configurer votre compte en exécutant la commande suivante. Assurez-vous que
correspond à l'adresse gmail que vous avez utilisée pour vous inscrire à cet événement. gcloud config set account <your-email-adress> -
Assurons-nous également que le bon projet est défini au cas où votre email serait utilisé pour plusieurs projets gcloud :
gcloud config set project hf-flax -
Ensuite, vous devez vous authentifier. Vous pouvez le faire en exécutant la commande
gcloud auth loginVous devriez obtenir un lien vers un site web où vous pouvez authentifier votre compte gmail.
-
Enfin, vous pouvez établir un tunnel SSH dans la VM TPU ! Veuillez exécuter la commande suivante en réglant la “–zone” sur
us-central2-bet sur le nom de la TPU qui vous a été envoyé par email par l’équipe de Hugging Face.gcloud alpha compute tpus tpu-vm ssh <tpu-name> --zone <zone> --project hf-flax
Cela devrait établir un tunnel SSH dans la VM TPU !
Note :
Vous n’êtes PAS supposé avoir accès à la console Google Cloud. Aussi, il se peut que vous ne receviez pas de lien d’invitation pour rejoindre le projethf-flax. Mais vous devriez tout de même pouvoir accéder à la VM TPU en suivant les étapes ci-dessus .
Note :
Les VM TPU sont déjà attachées à des disques de stockage persistants (de 3 TB). Cela sera utile au cas où votre équipe souhaiterait entraîner localement un jeu de données volumineux. Le nom du disque de stockage devrait également figurer dans l’e-mail que vous avez reçu. Suivez cette section pour plus de détails.
Installation de JAX
Commençons par créer un environnement virtuel Python :
python3 -m venv <your-venv-name>
Nous pouvons activer l’environnement en lançant :
source ~/<your-venv-name>/bin/activate
Installez ensuite Diffusers et les dépendances d’entraînement de la bibliothèque :
pip install git+https://github.com/huggingface/diffusers.git
Ensuite, clonez ce dépôt et installez JAX, Flax et les autres dépendances :
git clone https://github.com/huggingface/community-events
cd community-events/jax-controlnet-sprint/training_scripts
pip install -U -r requirements_flax.txt
Pour vérifier que JAX a été correctement installé, vous pouvez exécuter la commande suivante :
import jax
jax.device_count()
Cela devrait afficher le nombre de cœurs de la TPU, qui devrait être de 4 sur une VM TPUv4-8. Si Python n’est pas capable de détecter le périphérique TPU, veuillez consulter la section des erreurs possibles plus bas pour des solutions.
Si vous souhaitez utiliser le logging Weights and Biases, vous devez également installer wandb maintenant :
pip install wandb
Note :
Weights & Biases est gratuit pour les étudiants, les éducateurs et les chercheurs universitaires. Tous les participants à notre événement sont qualifiés pour obtenir un compte d’équipe académique Weights & Biases. Pour créer votre équipe, vous pouvez visiter le site https://wandb.ai/create-team et choisir le type d’équipe “Academic”. Pour plus d’informations sur la création et la gestion d’une équipe Weights & Biases, vous pouvez consulter le site https://docs.wandb.ai/guides/app/features/teams.
Exécution du script d’entraînement
Maintenant, téléchargeons deux images de conditionnement que nous utiliserons pour lancer la validation pendant l’entraînement afin de suivre nos progrès
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
Nous vous encourageons à stocker ou à partager votre modèle avec la communauté. Pour utiliser le Hub, veuillez vous connecter à votre compte Hugging Face, ou (en créer un si vous n’en avez pas déjà un) :
huggingface-cli login
Assurez-vous que les variables d’environnement MODEL_DIR, OUTPUT_DIR et HUB_MODEL_ID sont définies. Les variables OUTPUT_DIR et HUB_MODEL_ID spécifient où sauvegarder le modèle sur le Hub :
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="runs/fill-circle-{timestamp}"
export HUB_MODEL_ID="controlnet-fill-circle"
Et enfin, démarrez l’entraînement (assurez-vous d’être dans le répertoire jax-controlnet-sprint/training_scripts) !
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=1000 \
--train_batch_size=2 \
--revision="non-ema" \
--from_pt \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID \
--num_train_epochs=11 \
--push_to_hub \
--hub_model_id=$HUB_MODEL_ID
Notez que l’argument --from_pt convertira votre point de contrôle pytorch en flax. Cependant, il ne fonctionnera qu’avec les points de contrôle au format diffusers. Si votre MODEL_DIR ne contient pas de points de contrôle au format diffusers, vous ne pouvez pas utiliser l’argument --from_pt. Vous pouvez convertir vos points de contrôle ckpt ou safetensors au format diffusers en utilisant ce script.
Puisque nous avons passé l’argument --push_to_hub, il va automatiquement créer un repo de modèle sous votre compte Hugging Face basé sur $HUB_MODEL_ID. À la fin de l’entraînement, le point de contrôle final sera automatiquement stocké sur le Hub. Vous pouvez trouver un exemple de modèle ici.
Notre script d’entraînement fournit également un support limité pour le streaming de grands jeux de données à partir du Hub. Afin d’activer le streaming, il faut également définir --max_train_samples. Voici un exemple de commande (tiré de cet article de blog) :
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="runs/uncanny-faces-{timestamp}"
export HUB_MODEL_ID="controlnet-uncanny-faces"
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--streaming \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--max_train_samples 100000 \
--learning_rate=1e-5 \
--train_batch_size=1 \
--revision="flax" \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID
Notez cependant que les performances des TPUs peuvent être limitées car le streaming avec datasets n’est pas optimisé pour les images. Pour assurer un débit maximal, nous vous encourageons à explorer les options suivantes :
Lorsque vous travaillez avec un jeu de données plus important, vous pouvez avoir besoin d’exécuter le processus d’entraînement pendant une longue période et il est utile d’enregistrer des points de contrôle réguliers au cours du processus. Vous pouvez utiliser l’argument suivant pour activer les points de contrôle intermédiaires :
--checkpointing_steps=500
Cela permet d’enregistrer le modèle entraîné dans des sous-dossiers du dossier output_dir. Le nom des sous-dossiers correspond au nombre d’étapes effectuées jusqu’à présent ; par exemple : un point de contrôle sauvegardé après 500 étapes d’entraînement serait sauvegardé dans un sous-dossier nommé 500
Vous pouvez alors commencer votre entraînement à partir de ce point de contrôle sauvegardé avec
--controlnet_model_name_or_path="./control_out/500"
Nous soutenons l’entraînement avec la stratégie de pondération Min-SNR proposée dans Efficient Diffusion Training via Min-SNR Weighting Strategy qui permet d’obtenir une convergence plus rapide en rééquilibrant la perte. Pour l’utiliser, il faut définir l’argument --snr_gamma. La valeur recommandée est 5.0.
Nous supportons également l’accumulation de gradient, technique qui vous permet d’utiliser une taille de batch plus grande que celle que votre machine serait normalement capable de mettre en mémoire. Vous pouvez utiliser l’argument gradient_accumulation_steps pour définir les étapes d’accumulation du gradient. L’auteur de ControlNet recommande d’utiliser l’accumulation de gradient pour obtenir une meilleure convergence. Pour en savoir plus voir ici.
Vous pouvez profiler votre code avec :
--profile_steps==5
Reportez-vous à la documentation JAX sur le profilage. Pour inspecter la trace de profil, vous devez installer et démarrer Tensorboard avec le plugin de profil :
pip install tensorflow tensorboard-plugin-profile
tensorboard --logdir runs/fill-circle-100steps-20230411_165612/
Le profil peut alors être inspecté à l’adresse http://localhost:6006/#profile.
Parfois vous obtiendrez des conflits de version (messages d’erreur comme Duplicate plugins for name projector), ce qui signifie que vous devez désinstaller et réinstaller toutes les versions de Tensorflow/Tensorboard (par exemple avec pip uninstall tensorflow tf-nightly tensorboard tb-nightly tensorboard-plugin-profile && pip install tf-nightly tbp-nightly tensorboard-plugin-profile).
Notez que la fonctionnalité de débogage du plugin Tensorboard profile est toujours en cours de développement. Toutes les vues ne sont pas entièrement fonctionnelles, et par exemple le trace_viewer coupe les événements après 1M (ce qui peut résulter en la perte de toutes vos traces de périphériques si par exemple vous profilez l’étape de compilation par accident).
Dépannage de votre VM TPU
TRES IMPORTANT : Un seul processus peut accéder aux cœurs de la TPU à la fois. Cela signifie que si plusieurs membres de l’équipe essaient de se connecter aux cœurs de la TPU, vous obtiendrez des erreurs telles que :
libtpu.so already in used by another process. Not attempting to load libtpu.so in this process.
Nous recommandons à chaque membre de l’équipe de créer son propre environnement virtuel, mais une seule personne devrait exécuter les processus d’entraînement lourds. De plus, veuillez vous relayer lors de l’installation de la TPUv4-8 afin que tout le monde puisse vérifier que JAX est correctement installé.
Si les membres de votre équipe n’utilisent pas actuellement la TPU mais que vous obtenez toujours ce message d’erreur. Vous devez tuer le processus qui utilise la TPU avec :
kill -9 PID
vous devrez remplacer le terme « PID » par le PID du processus qui utilise TPU. Dans la plupart des cas, cette information est incluse dans le message d’erreur. Par exemple, si vous obtenez
The TPU is already in use by a process with pid 1378725. Not attempting to load libtpu.so in this process.
vous pouvez faire
kill -9 1378725
Vous pouvez également utiliser la commande suivante pour trouver les processus utilisant chacune des puces TPU (par exemple, /dev/accel0 est l’une des puces TPU)
sudo lsof -w /dev/accel0
Pour tuer tous les processus à l’aide de /dev/accel0, il faut
sudo lsof -t /dev/accel0 | xargs kill -9
Si Python n’est pas capable de détecter votre périphérique TPU (i.e. quand vous faites jax.device_count() et qu’il sort 0), cela peut être dû au fait que vous n’avez pas les droits d’accès aux logs tpu, ou que vous avez un fichier tpu lock qui traîne. Exécutez les commandes suivantes pour résoudre le problème
sudo rm -f /tmp/libtpu_lockfile
sudo chmod o+w /tmp/tpu_logs/
Comment faire une soumission
Pour faire une soumission complète, vous devez avoir les éléments suivants sur le Hub d’Hugging Face :
- Un dépôt de modèle avec les poids du modèle et la carte du modèle,
- (Facultatif) Un dépôt de jeu de données avec une carte de jeu de données,
- Un Space qui permet aux autres d’interagir avec votre modèle.
Pousser les poids du modèle et la carte du modèle vers le Hub
Si vous utilisez le script d’entraînement (train_controlnet_flax.py) fourni dans ce répertoire
L’activation de l’argument push_to_hub dans les arguments d’entraînement va :
- Créer un dépôt de modèles localement et à distance sur le Hub,
- Créer une carte de modèle et l’écrire dans le dépôt de modèles local,
- Sauvegarder votre modèle dans le référentiel de modèles local,
- Pousser le dépôt local vers le Hub.
Votre carte de modèle générée automatiquement ressemblera à ceci :
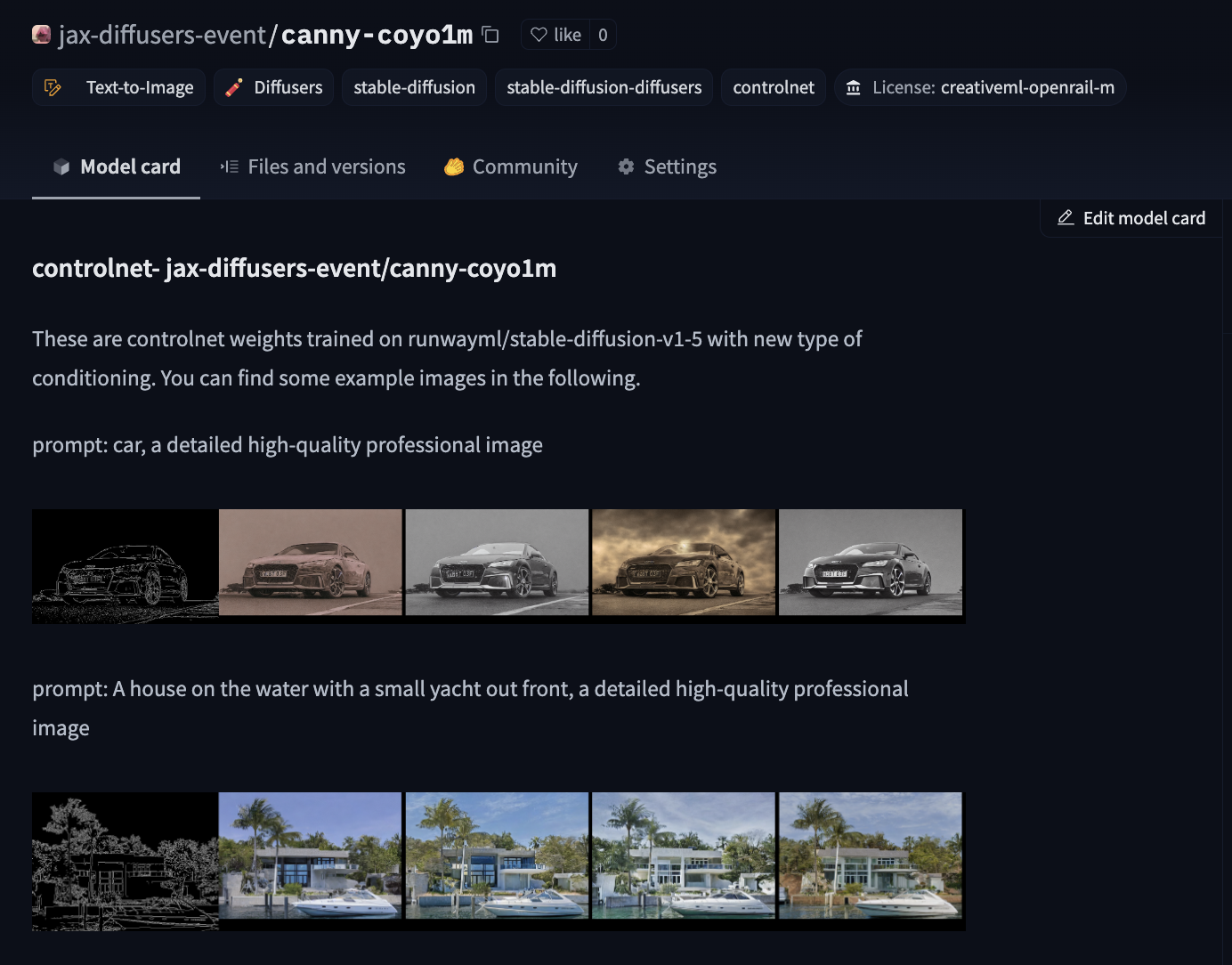
Vous pouvez modifier la carte de modèle pour qu’elle soit plus informative. Les cartes de modèle qui sont plus informatives que les autres auront plus de poids lors de l’évaluation.
Si vous avez entraîné un modèle personnalisé et que vous n’avez pas utilisé le script
Vous devez vous authentifier avec huggingface-cli login comme indiqué ci-dessus. Si vous utilisez une des classes de modèles disponibles dans diffusers, sauvegardez votre modèle avec la méthode save_pretrained de votre modèle.
model.save_pretrained("path_to_your_model_repository")
Après avoir sauvegardé votre modèle dans un dossier, vous pouvez simplement utiliser le script ci-dessous pour pousser votre modèle vers le Hub :
from huggingface_hub import create_repo, upload_folder
create_repo("username/my-awesome-model")
upload_folder(
folder_path="path_to_your_model_repository",
repo_id="username/my-awesome-model"
)
Ceci poussera votre modèle vers Hub. Après avoir poussé cela, vous devez créer la carte de modèle vous-même. Vous pouvez utiliser l’interface graphique pour l’éditer.
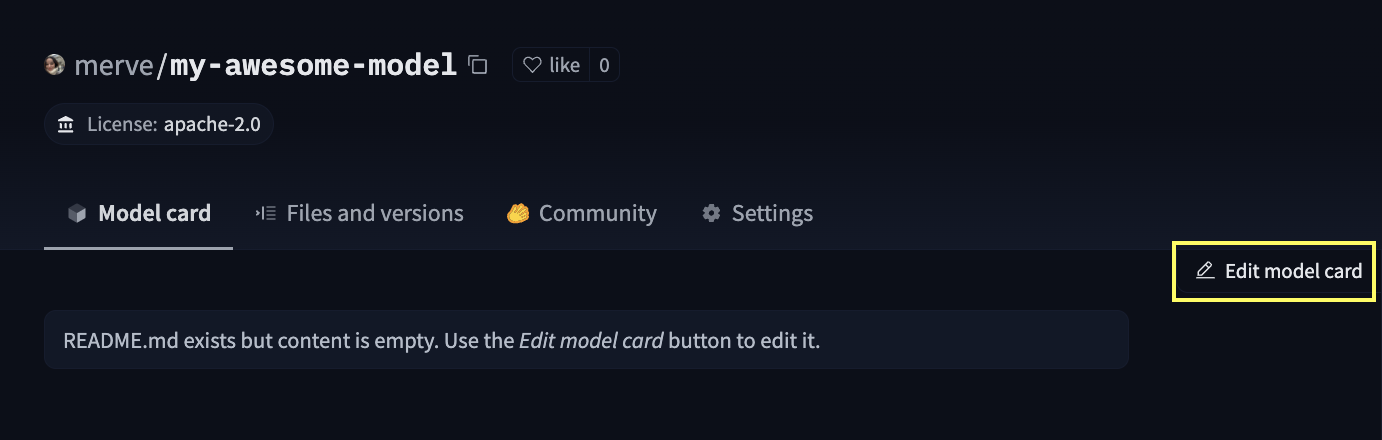
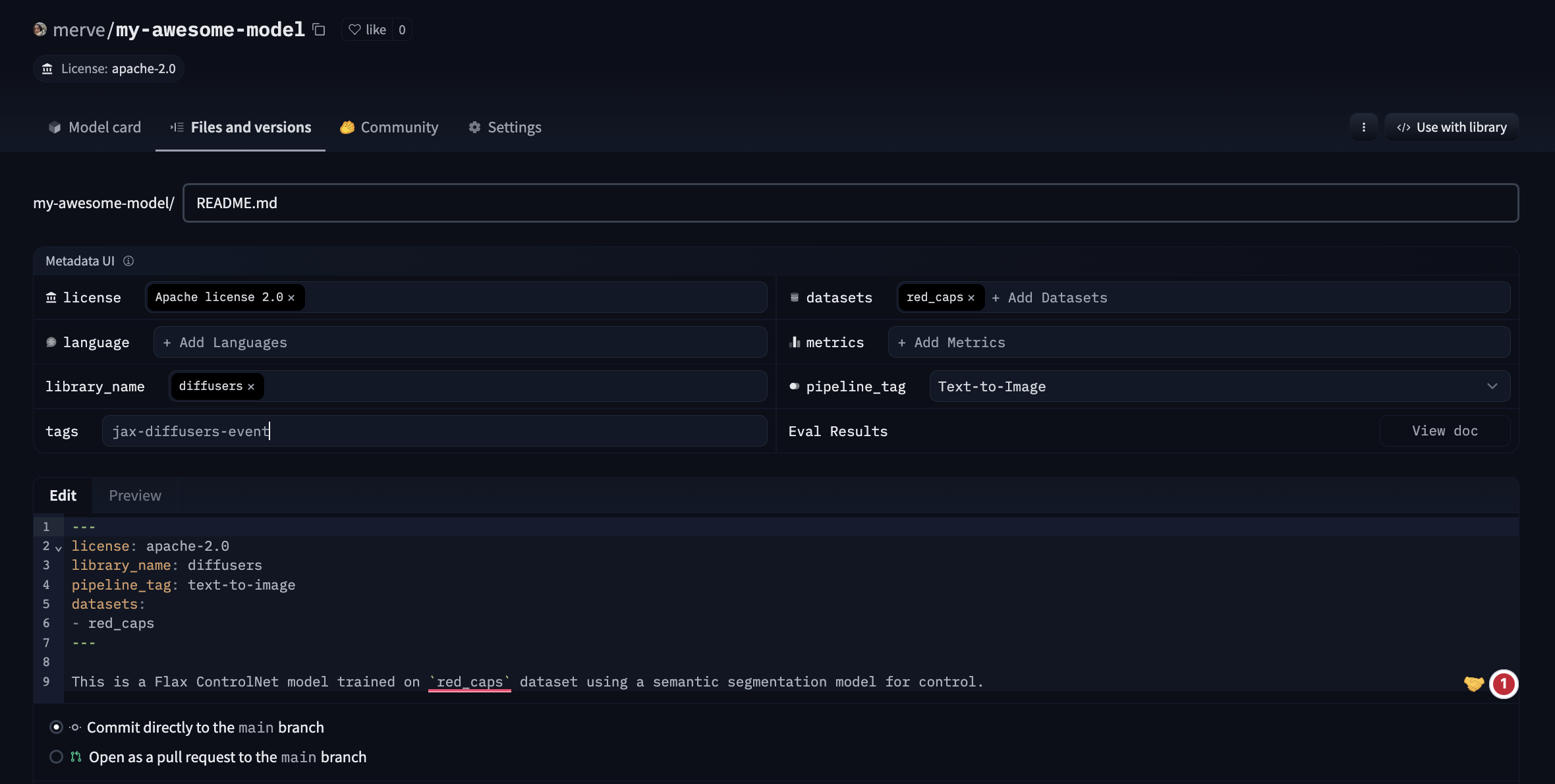
Chaque carte de modèle se compose de deux sections, les métadonnées et le texte libre. Vous pouvez éditer les métadonnées à partir des sections dans l’interface graphique. Si vous avez sauvegardé votre modèle en utilisant save_pretrained, vous n’avez pas besoin de fournir pipeline_tag et library_name. Sinon, fournissez pipeline_tag, library_name et le jeu de données s’il existe sur Hugging Face Hub. En plus de cela, vous devez ajouter jax-diffusers-event à la section tags.
---
license: apache-2.0
library_name: diffusers
tags:
- jax-diffusers-event
datasets:
- red_caps
pipeline_tag: text-to-image
---
Créer notre Space
Rédiger notre application
Nous utiliserons Gradio pour créer nos applications. Gradio possède deux API principales : Interface et Blocks. Interface est une API de haut niveau qui vous permet de créer une interface avec quelques lignes de code, et Blocks est une API de plus bas niveau qui vous donne plus de flexibilité sur les interfaces que vous pouvez construire. Le code doit être inclus dans un fichier appelé app.py.
Essayons de créer une application ControlNet comme exemple. L’API Interface fonctionne simplement comme suit :
import gradio as gr
# La fonction d'inférence prend en compte le prompt, le prompt négatif et l'image
def infer(prompt, negative_prompt, image):
# implémentez votre fonction d'inférence ici
return output_image
# vous devez passer les entrées et les sorties en fonction de la fonction d'inférence
gr.Interface(fn = infer, inputs = ["text", "text", "image"], outputs = "image").launch()
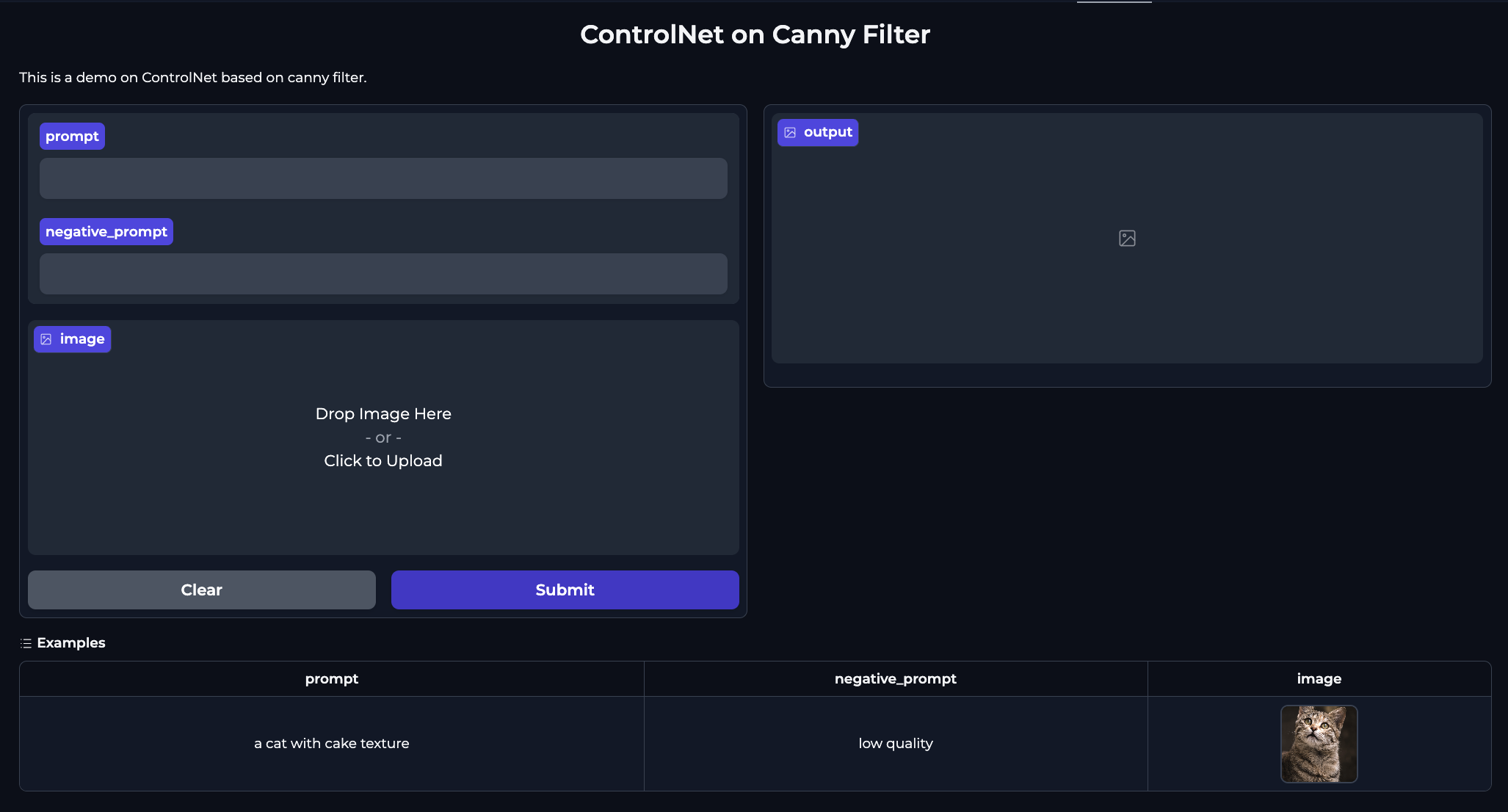
Vous pouvez personnaliser votre interface en passant title, description et examples à la fonction Interface.
title = "ControlNet on Canny Filter"
description = "This is a demo on ControlNet based on canny filter."
# vous devez passer vos exemples en fonction de vos entrées
# chaque liste intérieure est un exemple, chaque élément de la liste correspondant à un composant des `inputs`.
examples = [["a cat with cake texture", "low quality", "cat_image.png"]]
gr.Interface(fn = infer, inputs = ["text", "text", "image"], outputs = "image",
title = title, description = description, examples = examples, theme='gradio/soft').launch()
Votre interface ressemblera à ceci :
Avec les blocs, vous pouvez ajouter des marques, des onglets, des composants sous les colonnes et les lignes, etc. Supposons que nous ayons deux ControlNets et que nous voulions les inclure dans un Space. Nous les placerons sous différents onglets dans une démo comme ci-dessous :
import gradio as gr
def infer_segmentation(prompt, negative_prompt, image):
# votre fonction d'inférence pour le contrôle de la segmentation
return im
def infer_canny(prompt, negative_prompt, image):
# votre fonction d'inférence pour un contrôle efficace
return im
with gr.Blocks(theme='gradio/soft') as demo:
gr.Markdown("## Stable Diffusion with Different Controls")
gr.Markdown("In this app, you can find different ControlNets with different filters. ")
with gr.Tab("ControlNet on Canny Filter "):
prompt_input_canny = gr.Textbox(label="Prompt")
negative_prompt_canny = gr.Textbox(label="Negative Prompt")
canny_input = gr.Image(label="Input Image")
canny_output = gr.Image(label="Output Image")
submit_btn = gr.Button(value = "Submit")
canny_inputs = [prompt_input_canny, negative_prompt_canny, canny_input]
submit_btn.click(fn=infer_canny, inputs=canny_inputs, outputs=[canny_output])
with gr.Tab("ControlNet with Semantic Segmentation"):
prompt_input_seg = gr.Textbox(label="Prompt")
negative_prompt_seg = gr.Textbox(label="Negative Prompt")
seg_input = gr.Image(label="Image")
seg_output = gr.Image(label="Output Image")
submit_btn = gr.Button(value = "Submit")
seg_inputs = [prompt_input_seg, negative_prompt_seg, seg_input]
submit_btn.click(fn=infer_segmentation, inputs=seg_inputs, outputs=[seg_output])
demo.launch()
La démo ci-dessus ressemblera à ce qui suit :
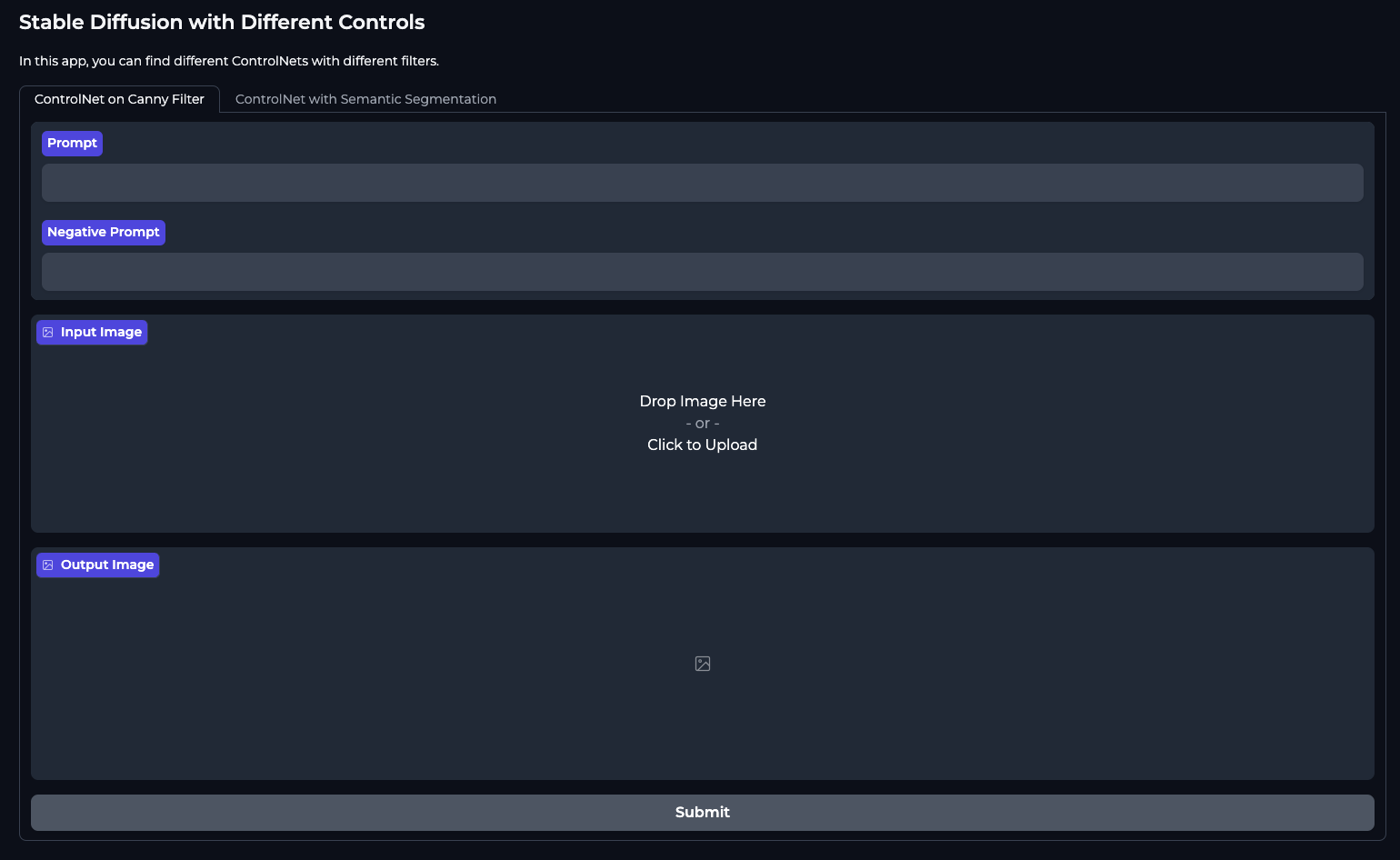
Créer notre Space
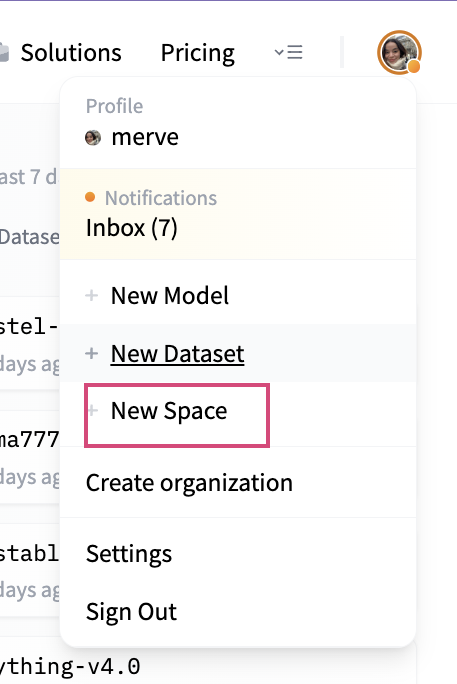
Une fois notre application écrite, nous pouvons créer un espace Hugging Face pour héberger notre application. Vous pouvez aller sur huggingface.co, cliquer sur votre profil en haut à droite et sélectionner “New Space”.
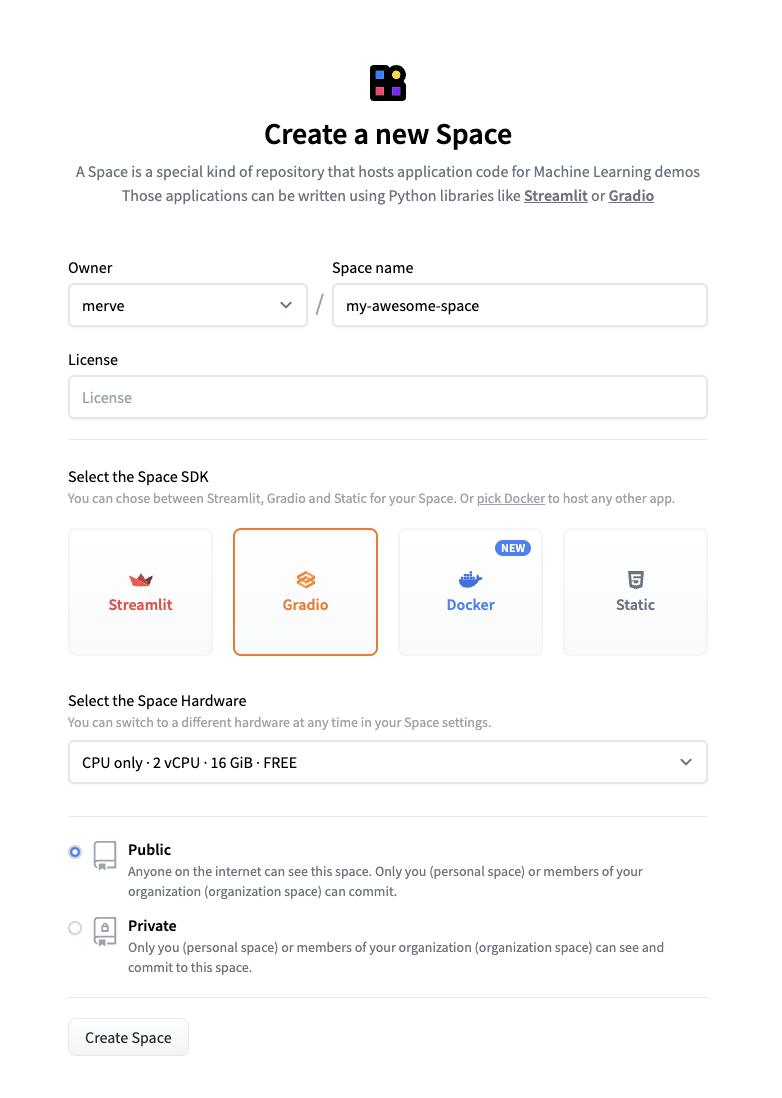
Nous pouvons nommer notre Space, choisir une licence et sélectionner « Gradio » comme Space SDK.
Après avoir créé le Space, vous pouvez soit utiliser les instructions ci-dessous pour cloner le dépôt localement, ajouter vos fichiers et pousser, soit utiliser l’interface graphique pour créer les fichiers et écrire le code dans le navigateur.
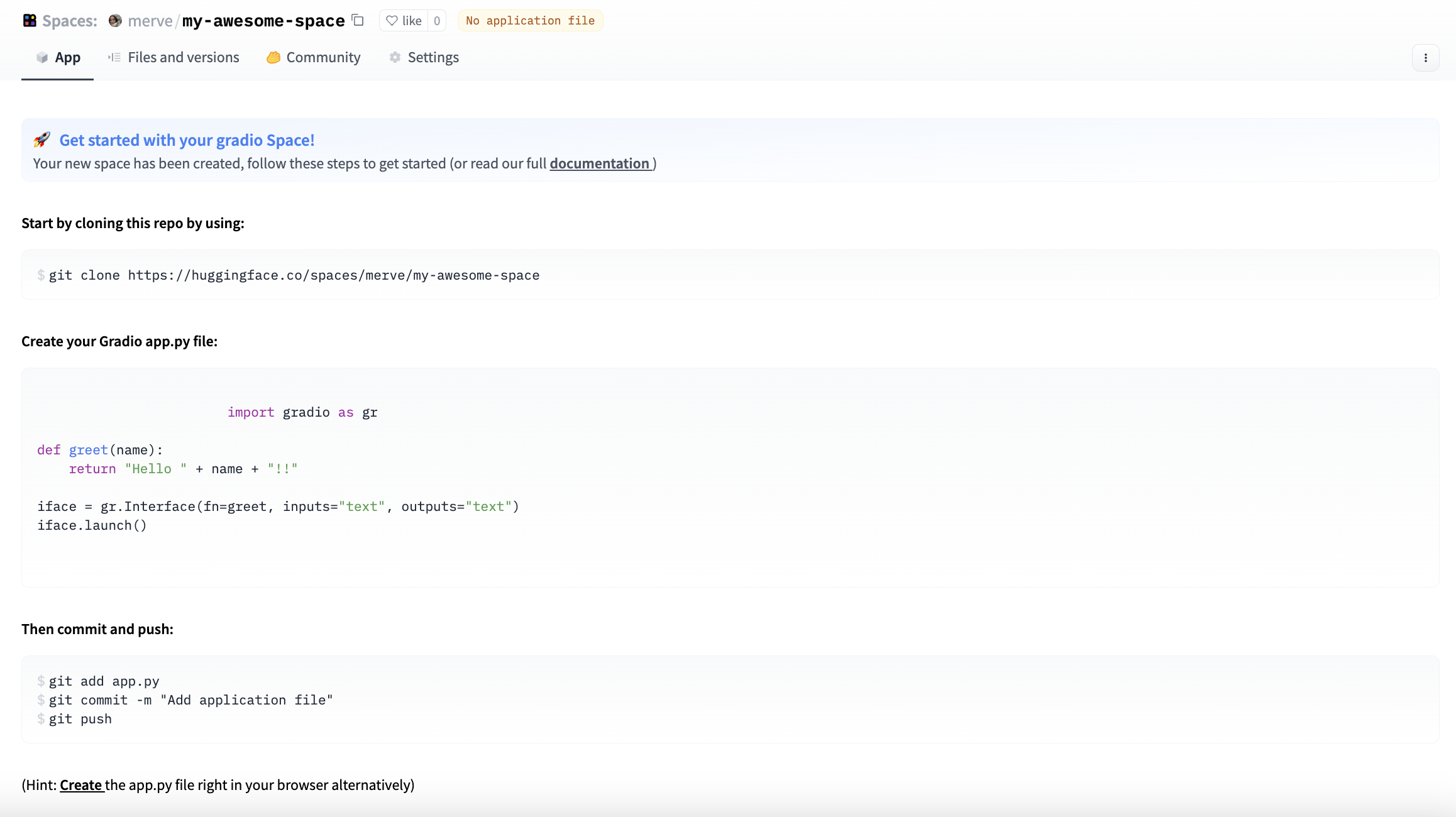
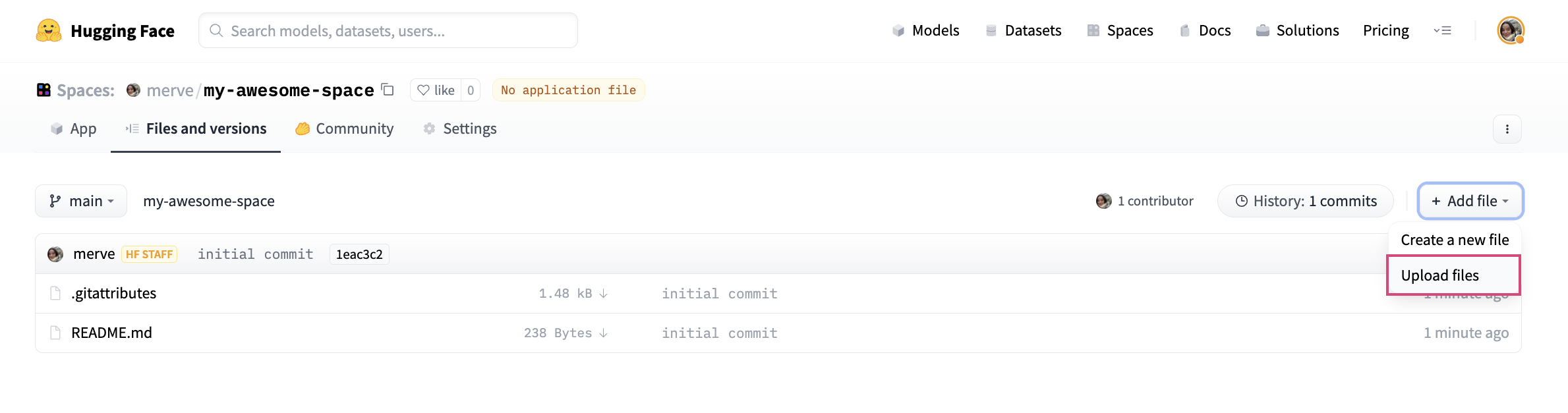
Pour télécharger votre fichier de candidature, cliquez sur « Add File » et faites glisser votre fichier.
Enfin, nous devons créer un fichier appelé requirements.txt et ajouter les conditions requises pour notre projet. Assurez-vous d’installer les versions de jax, diffusers et autres dépendances comme ci-dessous.
-f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
jax[cuda11_cudnn805]
jaxlib
git+https://github.com/huggingface/diffusers@main
opencv-python
transformers
flax
Nous vous accorderons une dotation GPU afin que votre application puisse fonctionner sur GPU.
Nous avons un classement hébergé ici et nous distribuerons des prix à partir de ce classement. Pour que votre Space apparaisse sur le leaderboard, éditez simplement README.md de votre Space pour avoir le tag jax-diffusers-event sous les tags comme ci-dessous :
---
title: Canny Coyo1m
emoji: 💜
...py
tags:
- jax-diffusers-event
---
Prix
Pour ce sprint, nous aurons de nombreux prix. Nous choisirons les dix premiers projets de ce classement, vous devez donc tagger votre Space pour le classement afin que votre soumission soit complète, comme indiqué dans la section ci-dessus. Les projets sont classés en fonction du nombre de j’aimes, nous augmenterons donc partagerons vos Spaces pour en augmenter la visibilité pour que les gens puissent voter en laissant un j’aime sur votre Space. Nous sélectionnerons les dix premiers projets du classement et le jury votera pour déterminer les trois premières places. Ces projets seront mis en valeur par Google et Hugging Face. Les interfaces élaborées ainsi que les projets dont les bases de code et les modèles sont en libre accès augmenteront probablement les chances de gagner des prix.
Les prix sont les suivants et sont remis à chaque membre de l’équipe :
Première place : Un bon d’achat de 150 $ à dépenser sur le Hugging Face Store, un abonnement d’un an à Hugging Face Hub PRO, le livre Natural Language Processing with Transformers.
Deuxième place : Un bon d’achat de 125$ à dépenser sur le Hugging Face Store, un abonnement d’un an à Hugging Face Hub PRO.
Troisième place : Un bon d’achat de 100 $ à dépenser sur le Hugging Face Store, un abonnement d’un an à Hugging Face Hub PRO.
Les dix premiers projets du classement (indépendamment de la décision du jury) gagneront un kit de merch exclusivement conçu pour ce sprint par Hugging Face, ainsi qu’un kit de merch séparé JAX de Google.
Jury
Le jury de ce sprint était composé des personnes suivantes :
- Robin Rombach, Stability AI
- Huiwen Chang, Google Research
- Jun-Yan Zhu, Carnegie Mellon University
- Merve Noyan, Hugging Face
FAQ
Dans cette section, nous rassemblons les réponses aux questions fréquemment posées sur notre canal discord.
Comment utiliser VSCode avec TPU VM ?
Vous pouvez suivre ce guide général sur la façon d’utiliser VSCode remote pour se connecter à Google Cloud VMs. Une fois que c’est configuré, vous pouvez développer sur la VM TPU en utilisant VSCode.
Pour obtenir votre IP externe, utilisez cette commande :
gcloud compute tpus tpu-vm describe <node_name> --zone=<zone>
Elle devrait être listée sous ‘accessConfig’ -> ‘externalIp’
Comment tester votre code localement ?
Puisque les membres de l’équipe partagent la VM TPU, il peut être pratique d’écrire et de tester votre code localement sur une unité centrale pendant que vos coéquipiers exécutent le processus d’entraînement sur la VM. Pour effectuer des tests locaux, il est important de mettre le drapeau xla_force_host_platform_device_count à 4. Pour en savoir plus, consultez la documentation.
Gagnants du sprint
Les 10 meilleurs projets (basés sur le nombre de likes sur leurs démos) sont disponibles sur ce classement. Nous avons soumis ce classement à notre jury pour qu’il juge les 10 meilleurs projets sur la base de plusieurs facteurs tels que les points de contrôle du modèle, les jeux de données et les bases de code open-source, l’exhaustivité du modèle et des cartes de jeux de données, etc. En conséquence, les trois projets suivants sont sortis vainqueurs :