Vue d'ensemble
Dans cette unité, nous examinerons certaines des nombreuses améliorations et extensions des modèles de diffusion apparaissant dans les recherches les plus récentes. Elle sera moins axée sur le code que les unités précédentes et est conçue pour vous donner un point de départ pour des recherches plus approfondies.
Vue d’ensemble de cette unité
Les différentes étapes à suivre pour cette unité :
- Lisez le matériel ci-dessous pour avoir une vue d’ensemble des idées clés de cette unité
- Approfondissez les sujets spécifiques grâce aux vidéos et aux ressources associées.
- Explorez les notebooks de démonstration, puis lisez la section « Et ensuite ? » pour obtenir des suggestions de projets.
Échantillonnage plus rapide par distillation
La distillation progressive est une technique permettant de prendre un modèle de diffusion existant et de l’utiliser pour entraîner une nouvelle version du modèle qui nécessite moins d’étapes pour l’inférence. Le modèle “élève” est initialisé à partir des poids du modèle “enseignant”. Pendant l’entraînement, le modèle enseignant effectue deux étapes d’échantillonnage et le modèle de étudiant tente de faire correspondre la prédiction résultante en une seule étape. Ce processus peut être répété plusieurs fois, le modèle étudiant de l’itération précédente devenant le modèle enseignant pour l’étape suivante. Le résultat est un modèle qui peut produire des échantillons décents en beaucoup moins d’étapes (généralement 4 ou 8) que le modèle enseignant d’origine. Le mécanisme de base est illustré dans ce diagramme tiré de l’article qui a introduit l’idée :
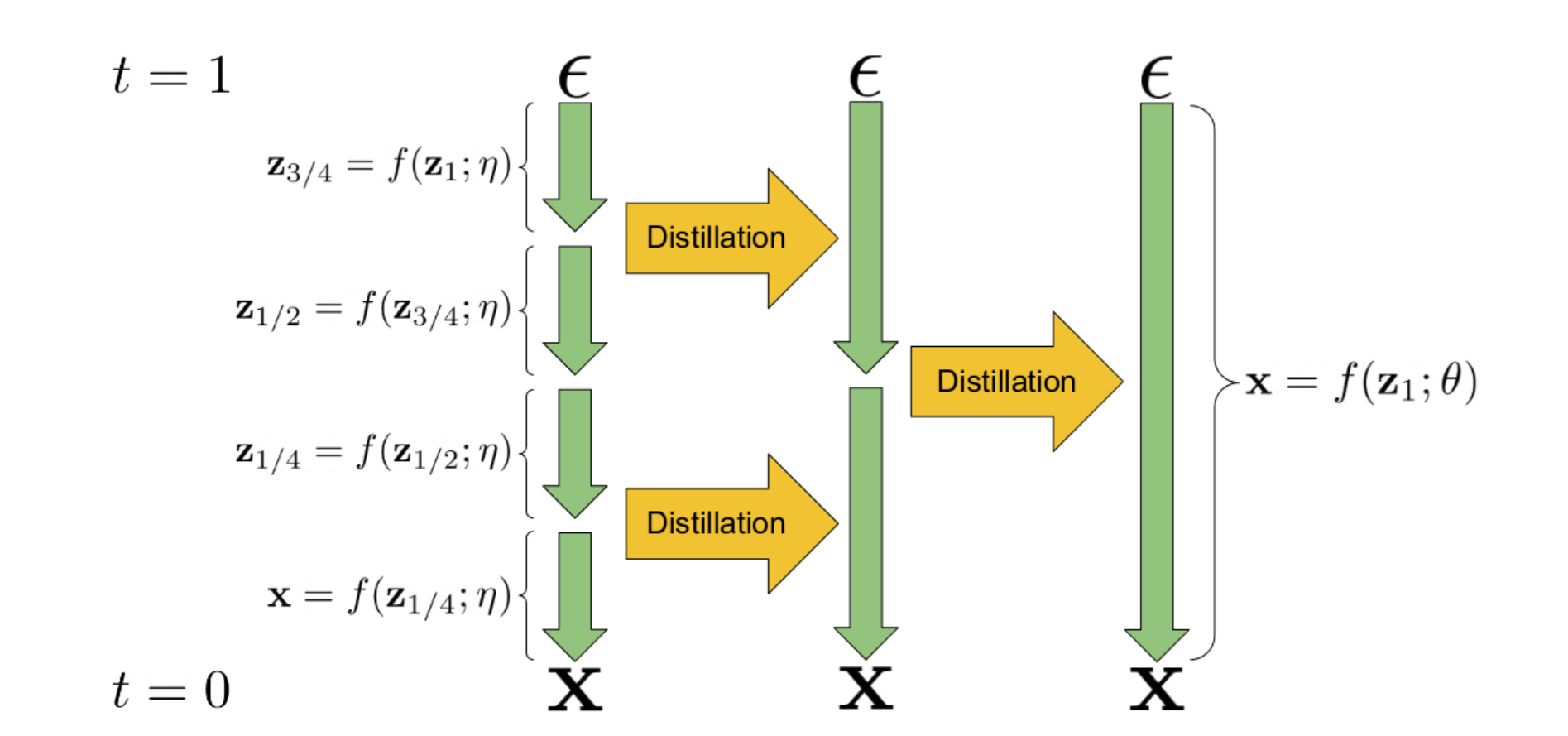
Illustration de la distillation progressive issue de ce papier
L’idée d’utiliser un modèle existant pour “enseigner” un nouveau modèle peut être étendue pour créer des modèles guidés dans lesquels la technique de guidage sans classifieur est utilisée par le modèle enseignant et le modèle étudiant doit apprendre à produire un résultat équivalent en une seule étape sur la base d’une entrée supplémentaire spécifiant l’échelle de guidage ciblée. Cela permet de réduire encore le nombre d’évaluations de modèles nécessaires pour produire des échantillons de haute qualité. Cette vidéo (en anglais) donne un aperçu de l’approche.
Références principales :
- Progressive Distillation For Fast Sampling Of Diffusion Models
- On Distillation Of Guided Diffusion Models
Amélioration de l’entraînement
Plusieurs astuces supplémentaires ont été mises au point pour améliorer l’entraînement des modèles de diffusion. Dans cette section, nous avons essayé de présenter les idées principales des articles récents. Il y a un flux constant de recherches qui sortent avec des améliorations supplémentaires, donc si vous voyez un article qui devrait être ajouté ici, veuillez nous le faire savoir !
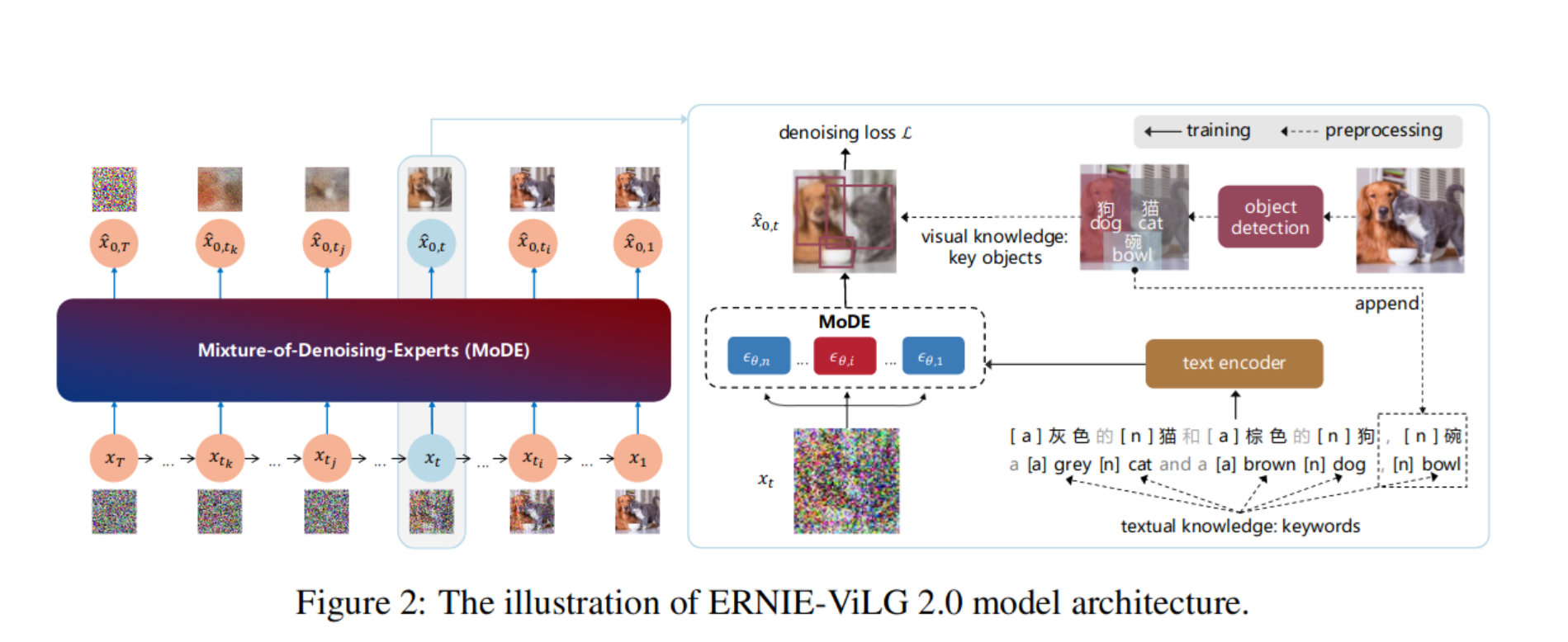
Figure 2 du papier ERNIE-ViLG 2.0
Améliorations principales de l’entraînement :
- Réglage du planificateur du bruit, de la pondération de la perte et des trajectoires d’échantillonnage pour un entraînement plus efficace. Un excellent papier explorant certains de ces choix de conception est Elucidating the Design Space of Diffusion-Based Generative Models par Karras et al.
- Entraînement sur divers rapports d’aspect, comme décrit dans cette vidéo du lancement du cours (en anglais).
- Modèles de diffusion en cascade, entraînant un modèle à basse résolution, puis un ou plusieurs modèles en super-résolution. Utilisés dans DALLE-2, Imagen et d’autres pour la génération d’images à haute résolution.
- Meilleur conditionnement, incorporation d’enchâssement textuels riches (Imagen utilise un grand modèle de langage appelé T5) ou plusieurs types de conditionnement (eDiffi).
- “Amélioration des connaissances” : incorporation de modèles de sous-titrage d’images et de détection d’objets pré-entraînés dans le processus d’entraînement afin de créer des sous-titres plus informatifs et d’obtenir de meilleures performances (ERNIE-ViLG 2.0).
- “Mélange d’experts de débruitage” (MoDE) : entraîner différentes variantes du modèle (“experts”) pour différents niveaux de bruit, comme illustré dans l’image ci-dessus tirée du papier ERNIE-ViLG 2.0.
Références principales :
- Elucidating the Design Space of Diffusion-Based Generative Models
- eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
- ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
- Imagen - Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (site démo)
Plus de contrôle pour la génération et l’édition
Outre les améliorations apportées à l’entraînement, plusieurs innovations ont été apportées à la phase d’échantillonnage et d’inférence, y compris de nombreuses approches qui peuvent ajouter de nouvelles capacités aux modèles de diffusion existants.

Échantillons générés par eDiffi
La vidéo Editing Images with Diffusion Models (en anglais) donne un aperçu des différentes méthodes utilisées pour éditer des images existantes avec des modèles de diffusion. Les techniques disponibles peuvent être divisées en quatre catégories principales :
1) Ajouter du bruit, puis débruiter avec un nouveau prompt. C’est l’idée qui sous-tend le pipeline img2img, qui a été modifié et étendu dans plusieurs articles :
- SDEdit et MagicMix s’inspirent de cette idée
- DDIM inversion utilise le modèle pour “inverser” la trajectoire d’échantillonnage plutôt que d’ajouter un bruit aléatoire, ce qui permet un meilleur contrôle
- Null-text Inversion améliore considérablement les performances de ce type d’approche en optimisant à chaque étape les enchâssements de texte inconditionnels utilisés pour le guidage sans classifieur, ce qui permet d’obtenir une édition d’images textuelles de très haute qualité. 2) Extension des idées du point (1), mais avec un masque permettant de contrôler l’endroit où l’effet est appliqué
- Blended Diffusion introduit l’idée de base
- Cette démo utilise un modèle de segmentation existant (CLIPSeg) pour créer le masque sur la base d’une description textuelle
- DiffEdit est un excellent papier montrant comment le modèle de diffusion lui-même peut être utilisé pour générer un masque approprié pour l’édition de l’image en fonction du texte
- SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model finetune un modèle de diffusion pour une peinture guidée par un masque 3) Contrôle de l’attention croisée : utilisation du mécanisme d’attention croisée dans les modèles de diffusion pour contrôler l’emplacement spatial des modifications afin d’exercer un contrôle plus fin
- Prompt-to-Prompt Image Editing with Cross Attention Control est l’article clé qui a introduit cette idée, et la technique a depuis été appliquée à Stable Diffusion
- TCette idée est également utilisée pour ‘paint-with-words’ (eDiffi, voir ci-dessus) 4) Finetuner (surapprendre) sur une seule image, puis générer avec le modèle finetuné. Les articles suivants ont tous deux publié des variantes de cette idée à peu près au même moment :
- Imagic: Text-Based Real Image Editing with Diffusion Models
- UniTune: Text-Driven Image Editing by Fine Tuning an Image Generation Model on a Single Image
Le papier InstructPix2Pix : Learning to Follow Image Editing Instructions est remarquable en ce sens qu’il utilise certaines des techniques d’édition d’images décrites ci-dessus pour construire un jeu de données synthétique de paires d’images accompagnées d’instructions d’édition d’images (générées avec GPT3.5) afin d’entraîner un nouveau modèle capable d’éditer des images sur la base d’instructions en langage naturel.
Video

Images fixes d’exemples de vidéos générées avec Imagen Video
Une vidéo peut être représentée comme une séquence d’images, et les idées fondamentales des modèles de diffusion peuvent être appliquées à ces séquences. Les travaux récents se sont concentrés sur la recherche d’architectures appropriées (telles que les « 3D UNets » qui opèrent sur des séquences entières) et sur l’utilisation efficace des données vidéo. Étant donné que les vidéos à haute fréquence d’images comportent beaucoup plus de données que les images fixes, les approches actuelles tendent à générer d’abord des vidéos à faible résolution et à faible fréquence d’images, puis à appliquer la super-résolution spatiale et temporelle pour produire les sorties vidéo finales de haute qualité.
Références principales :
Audio
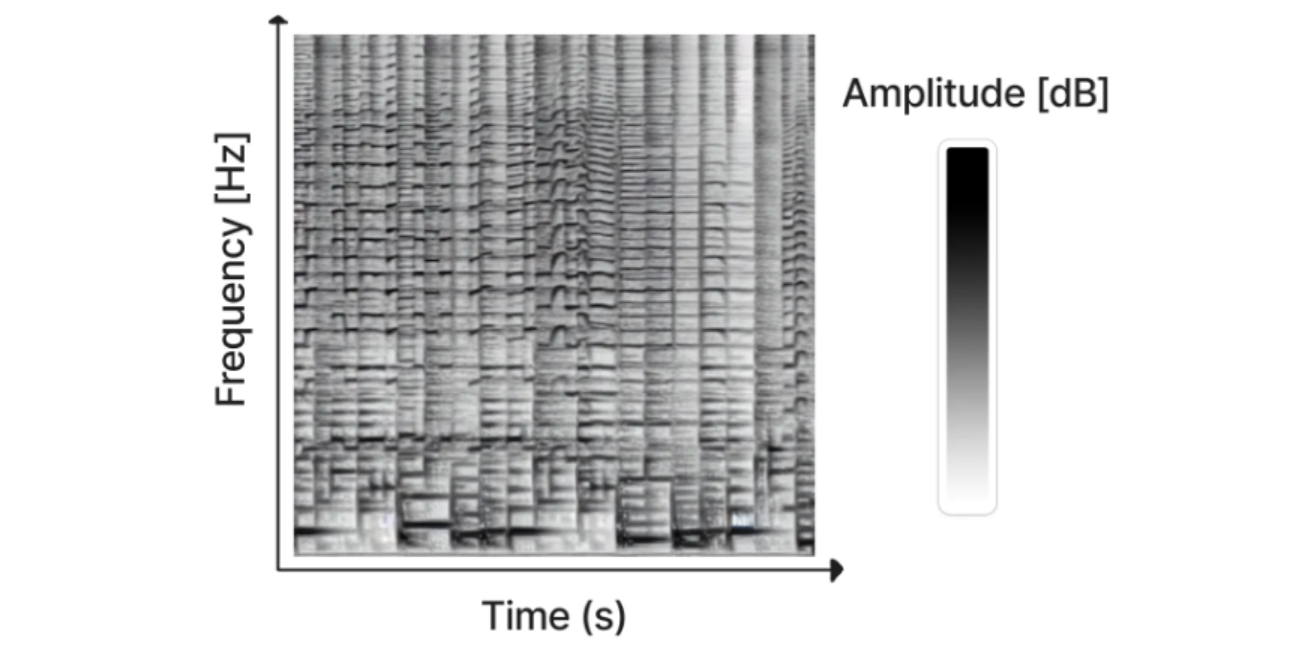
Un spectrogramme généré avec Riffusion
Bien que des travaux aient été réalisés pour générer du son directement à l’aide de modèles de diffusion (par exemple DiffWave), l’approche la plus fructueuse jusqu’à présent a consisté à convertir le signal audio en ce que l’on appelle un spectrogramme, qui “encode” effectivement le son sous la forme d’une “image” en 2D qui peut ensuite être utilisée pour entraîner les modèles de diffusion que nous avons l’habitude d’utiliser pour la génération d’images. Les spectrogrammes ainsi générés peuvent ensuite être convertis en données audio à l’aide des méthodes existantes. Cette approche est à l’origine de Riffusion, qui a récemment été publié et a permis de finetuner Stable Diffusion pour générer des spectrogrammes conditionnés par le texte. Essayez-le ici.
Le domaine de la génération d’audio évolue très rapidement. Au cours de la semaine dernière (à l’heure où nous écrivons ces lignes), au moins cinq nouvelles avancées ont été annoncées, qui sont marquées d’une étoile dans la liste ci-dessous :
Références principales :
- DiffWave: A Versatile Diffusion Model for Audio Synthesis
- Riffusion (et son code)
- ⭐ MusicLM de Google génère un son cohérent à partir d’un texte et peut être conditionné avec des mélodies fredonnées ou sifflées.
- ⭐ RAVE2, une nouvelle version d’un auto-encodeur variationnel qui sera utile pour la diffusion latente dans les tâches audio. Il est utilisé dans le modèle AudioLDM.
- ⭐ Noise2Music, un modèle de diffusion entraîné à produire des clips audio de 30 secondes en haute qualité sur la base de descriptions textuelles.
- ⭐ Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models, un modèle de diffusion entraîné à générer divers sons à partir d’un texte.
- ⭐ Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
Nouvelles architectures et approches : vers un « raffinement itératif »

Figure 1 du papier Cold Diffusion
Nous dépassons peu à peu la définition étroite initiale des modèles de « diffusion » pour nous orienter vers une classe plus générale de modèles qui effectuent un raffinement itératif, où une certaine forme de corruption (comme l’ajout d’un bruit gaussien dans le processus de diffusion vers l’avant) est progressivement inversée pour générer des échantillons. L’article « Cold Diffusion » a démontré que de nombreux autres types de corruption peuvent être « défaits » de manière itérative pour générer des images (exemples ci-dessus), et des approches récentes basées sur des transfomers ont démontré l’efficacité du remplacement ou du masquage de token en tant que stratégie de bruitage.
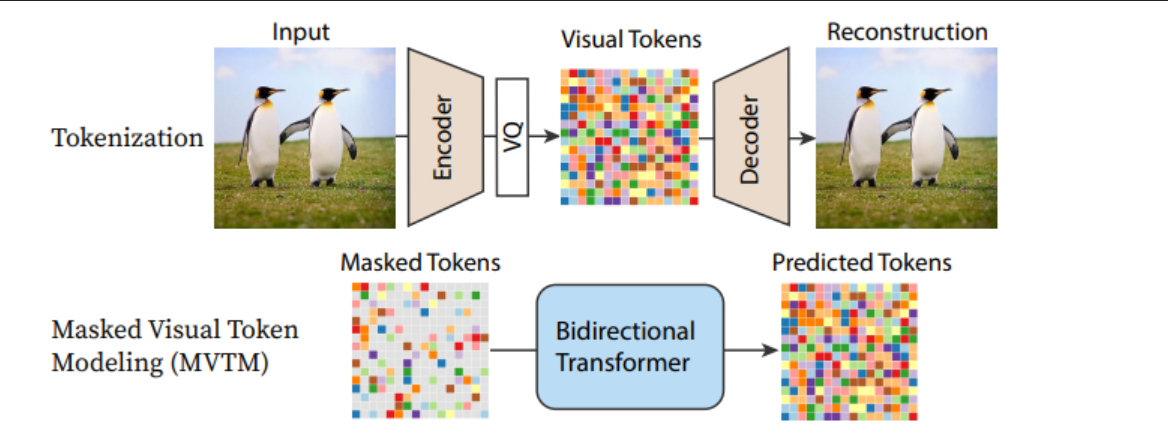
Pipeline de MaskGIT
L’architecture UNet au cœur de nombreux modèles de diffusion actuels est également remplacée par d’autres solutions, notamment diverses architectures basées sur des transformers. Dans Scalable Diffusion Models with Transformers (DiT), un transformer est utilisé à la place du UNet pour une approche de modèle de diffusion assez standard, avec d’excellents résultats. Recurrent Interface Networks applique une nouvelle architecture basée sur un transformer et une stratégie d’entraînement à la recherche d’une efficacité accrue. MaskGIT et MUSE utilisent des transformers pour travailler avec des représentations d’images par tokens, bien que le modèle Paella démontre qu’un UNet peut également être appliqué avec succès à ces régimes basés sur des tokens.
Avec chaque nouveau papier, des approches plus efficaces sont développées, et il faudra peut-être attendre un certain temps avant de voir à quoi ressemblent les performances maximales pour ce type de tâches d’affinage itératif. Il reste encore beaucoup de choses à explorer !
Références principales :
- Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise
- Scalable Diffusion Models with Transformers (DiT)
- MaskGIT: Masked Generative Image Transformer
- Muse: Text-To-Image Generation via Masked Generative Transformers
- Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces (Paella)
- Recurrent Interface Networks : une nouvelle architecture prometteuse qui permet de générer des images à haute résolution sans recourir à la diffusion latente ou à la super-résolution. Voir également simple diffusion : End-to-end diffusion for high-resolution images qui souligne l’importance du planificateur du bruit pour l’entraînement à des résolutions plus élevées.
Notebooks
| Chapitre | Colab | Kaggle | Gradient | Studio Lab |
|---|---|---|---|---|
| Débruitage inverse des modèles de diffusion implicites |  |
 |
||
| Diffusion pour l’audio | |
|
Nous avons abordé un grand nombre d’idées différentes dans cette unité, dont beaucoup mériteraient de faire l’objet de leçons plus détaillées à l’avenir. Pour l’instant, vous pouvez aborder deux de ces nombreux sujets via les notebook que nous avons préparés.
- Le débruitage inverse des modèles de diffusion implicites montre comment une technique appelée inversion peut être utilisée pour éditer des images à l’aide de modèles de diffusion existants.
- Diffusion pour l’audio introduit l’idée de spectrogrammes et montre un exemple minimal de finetuning d’un modèle de diffusion pour l’audio sur un genre de musique spécifique.
Et ensuite ?
Il s’agit de la dernière unité de ce cours actuellement, ce qui signifie que la suite ne dépend que de vous ! N’oubliez pas que vous pouvez toujours poser des questions et discuter de vos projets sur le Discord d’Hugging Face. Nous avons hâte de voir ce que vous allez créer 🤗