Finetuning et guidage
Dans ce notebook, nous allons couvrir deux approches principales pour adapter les modèles de diffusion existants :
- Avec le finetuning, nous réentraînerons les modèles existants sur de nouvelles données afin de modifier le type de résultats qu’ils produisent.
- Avec le guidage, nous prenons un modèle existant et dirigeons le processus de génération au moment de l’inférence pour un contrôle supplémentaire.
Ce que vous apprendrez :
A la fin de ce notebook, vous saurez comment :
- Créer une boucle d’échantillonnage et générer des échantillons plus rapidement à l’aide d’un nouveau planificateur
- Finetuner un modèle de diffusion existant sur de nouvelles données, y compris :
- Utiliser l’accumulation du gradient pour contourner certains des problèmes liés aux petits batchs.
- Enregistrer les échantillons dans Weights and Biases pendant l’entraînement pour suivre la progression (via le script d’exemple joint).
- Sauvegarder le pipeline résultant et le télécharger sur le Hub
- Guider le processus d’échantillonnage avec des fonctions de perte supplémentaires pour ajouter un contrôle sur les modèles existants, y compris :
- Explorer différentes approches de guidage avec une simple perte basée sur la couleur
- Utiliser CLIP pour guider la génération à l’aide d’un prompt de texte
- Partager une boucle d’échantillonnage personnalisée en utilisant Gradio et 🤗 Spaces.
Configuration et importations
Pour enregistrer vos modèles finetunés sur le Hub d’Hugging Face, vous devrez vous connecter avec un token qui a un accès en écriture. Le code ci-dessous vous invite à le faire et vous renvoie à la page des tokens de votre compte. Vous aurez également besoin d’un compte Weights and Biases si vous souhaitez utiliser le script d’entraînement pour enregistrer des échantillons au fur et à mesure que le modèle s’entraîne. Là encore, le code devrait vous inviter à vous connecter là où c’est nécessaire.
A part cela, la seule chose à faire est d’installer quelques dépendances, d’importer tout ce dont nous aurons besoin et de spécifier l’appareil que nous utiliserons :
!pip install -qq diffusers datasets accelerate wandb open-clip-torch
# Code pour se connecter au Hub d'Hugging Face, nécessaire pour partager les modèles
# Assurez-vous d'utiliser un *token* avec un accès WRITE (écriture)
from huggingface_hub import notebook_login
notebook_login()
Token is valid.
Your token has been saved in your configured git credential helpers (store).
Your token has been saved to /root/.huggingface/token
Login successful
import numpy as np
import torch
import torch.nn.functional as F
import torchvision
from datasets import load_dataset
from diffusers import DDIMScheduler, DDPMPipeline
from matplotlib import pyplot as plt
from PIL import Image
from torchvision import transforms
from tqdm.auto import tqdm
device = (
"mps"
if torch.backends.mps.is_available()
else "cuda"
if torch.cuda.is_available()
else "cpu"
)
Chargement d’un pipeline pré-entraîné
Pour commencer ce notebook, chargeons un pipeline existant et voyons ce que nous pouvons en faire :
image_pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
image_pipe.to(device);
La génération d’images est aussi simple que l’exécution de la méthode __call__ du pipeline en l’appelant comme une fonction :
images = image_pipe().images
images[0]

Sympathique, mais LENT ! Avant d’aborder les sujets principaux du jour, jetons un coup d’œil à la boucle d’échantillonnage proprement dite et voyons comment nous pouvons utiliser un échantillonneur plus sophistiqué pour l’accélérer.
Échantillonnage plus rapide avec DDIM
À chaque étape, le modèle est nourri d’une entrée bruyante et il lui est demandé de prédire le bruit (et donc une estimation de ce à quoi l’image entièrement débruitée pourrait ressembler). Au départ, ces prédictions ne sont pas très bonnes, c’est pourquoi nous décomposons le processus en plusieurs étapes. Cependant, l’utilisation de plus de 1000 étapes s’est avérée inutile, et une multitude de recherches récentes ont exploré la manière d’obtenir de bons échantillons avec le moins d’étapes possible.
Dans la bibliothèque 🤗 Diffusers, ces méthodes d’échantillonnage sont gérées par un planificateur, qui doit effectuer chaque mise à jour via la fonction step(). Pour générer une image, on commence par un bruit aléatoire $x$. Ensuite, pour chaque pas de temps dans le planificateur de bruit, nous introduisons l’entrée bruitée $x$ dans le modèle et transmettons la prédiction résultante à la fonction step(). Celle-ci renvoie une sortie avec un attribut prev_sample. “previous” parce que nous revenons en arrière dans le temps, d’un niveau de bruit élevé à un niveau de bruit faible (à l’inverse du processus de diffusion vers l’avant).
Voyons cela en action ! Tout d’abord, nous chargeons un planificateur, ici un DDIMScheduler basé sur le papier Denoising Diffusion Implicit Models qui peut donner des échantillons décents en beaucoup moins d’étapes que l’implémentation originale du DDPM :
# Créer un nouveau planificateur et définir le nombre d'étapes d'inférence
scheduler = DDIMScheduler.from_pretrained("google/ddpm-celebahq-256")
scheduler.set_timesteps(num_inference_steps=40)
Vous pouvez constater que ce modèle effectue 40 étapes au total, chaque saut équivalant à 25 étapes du programme original de 1000 étapes :
scheduler.timesteps
tensor([975, 950, 925, 900, 875, 850, 825, 800, 775, 750, 725, 700, 675, 650,
625, 600, 575, 550, 525, 500, 475, 450, 425, 400, 375, 350, 325, 300,
275, 250, 225, 200, 175, 150, 125, 100, 75, 50, 25, 0])
Créons 4 images aléatoires et exécutons la boucle d’échantillonnage, en visualisant à la fois le $x$ actuel et la version débruitée prédite au fur et à mesure de l’avancement du processus :
# Le point de départ aléatoire
x = torch.randn(4, 3, 256, 256).to(device) # Batch de 4 images à 3 canaux de 256 x 256 px
# Boucle sur les pas de temps d'échantillonnage
for i, t in tqdm(enumerate(scheduler.timesteps)):
# Préparer l'entrée du modèle
model_input = scheduler.scale_model_input(x, t)
# Obtenir la prédiction
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
# Calculer la forme que devrait prendre l'échantillon mis à jour à l'aide du planificateur
scheduler_output = scheduler.step(noise_pred, t, x)
# Mise à jour de x
x = scheduler_output.prev_sample
# Occasionnellement, afficher à la fois x et les images débruitées prédites
if i % 10 == 0 or i == len(scheduler.timesteps) - 1:
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
grid = torchvision.utils.make_grid(x, nrow=4).permute(1, 2, 0)
axs[0].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)
axs[0].set_title(f"Current x (step {i})")
pred_x0 = (
scheduler_output.pred_original_sample
) # Non disponible pour tous les planificateurs
grid = torchvision.utils.make_grid(pred_x0, nrow=4).permute(1, 2, 0)
axs[1].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)
axs[1].set_title(f"Predicted denoised images (step {i})")
plt.show()

Comme vous pouvez le voir, les prédictions initiales ne sont pas très bonnes, mais au fur et à mesure que le processus se poursuit, les résultats prédits deviennent de plus en plus précis. Si vous êtes curieux de savoir ce qui se passe à l’intérieur de la fonction step(), inspectez le code (bien commenté) avec :
# ??scheduler.step
Vous pouvez également insérer ce nouveau planificateur à la place du planificateur original fourni avec le pipeline, et échantillonner de la manière suivante :
image_pipe.scheduler = scheduler
images = image_pipe(num_inference_steps=40).images
images[0]

Très bien, nous pouvons maintenant obtenir des échantillons dans un délai raisonnable ! Cela devrait accélérer les choses au fur et à mesure que nous avançons dans le reste de ce notebook :)
Finetuning
Et maintenant, le plus amusant ! Étant donné ce pipeline pré-entraîné, comment pouvons-nous réentraîner le modèle pour générer des images sur la base de nouvelles données d’entraînement ?
Il s’avère que cela est presque identique à entraîner un modèle à partir de zéro (comme nous l’avons vu dans l’unité 1), sauf que nous commençons avec le modèle existant. Voyons cela en action et abordons quelques considérations supplémentaires au fur et à mesure.
Tout d’abord, le jeu de données : vous pouvez essayer ce jeu de données de visages vintage ou ces visages animés pour quelque chose de plus proche des données d’entraînement originales de ce modèle de visages. Mais pour le plaisir, utilisons plutôt le même petit jeu de données de papillons que nous avons utilisé pour nous entraîner à partir de zéro dans l’unité 1. Exécutez le code ci-dessous pour télécharger le jeu de données papillons et créer un chargeur de données à partir duquel nous pouvons échantillonner un batch d’images :
# Pas sur Colab ? Les commentaires avec #@ permettent de modifier l'interface utilisateur comme les titres ou les entrées
# mais peuvent être ignorés si vous travaillez sur une plateforme différente.
dataset_name = "huggan/smithsonian_butterflies_subset" # @param
dataset = load_dataset(dataset_name, split="train")
image_size = 256 # @param
batch_size = 4 # @param
preprocess = transforms.Compose(
[
transforms.Resize((image_size, image_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"images": images}
dataset.set_transform(transform)
train_dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=True
)
print("Previewing batch:")
batch = next(iter(train_dataloader))
grid = torchvision.utils.make_grid(batch["images"], nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5);

Considération 1 : notre taille de batch ici (4) est assez petite, puisque nous entraînons sur une grande taille d’image (256 pixels) en utilisant un modèle assez grand et que nous manquerons de RAM du GPU si nous augmentons trop la taille du batch. Vous pouvez réduire la taille de l’image pour accélérer les choses et permettre des batchs plus importants, mais ces modèles ont été conçus et entraînés à l’origine pour une génération de 256 pixels.
Passons maintenant à la boucle d’entraînement. Nous allons mettre à jour les poids du modèle pré-entraîné en fixant la cible d’optimisation à image_pipe.unet.parameters(). Le reste est presque identique à l’exemple de boucle d’entraînement de l’unité 1. Cela prend environ 10 minutes à exécuter sur Colab, c’est donc le bon moment pour prendre un café ou un thé pendant que vous attendez :
num_epochs = 2 # @param
lr = 1e-5 # 2param
grad_accumulation_steps = 2 # @param
optimizer = torch.optim.AdamW(image_pipe.unet.parameters(), lr=lr)
losses = []
for epoch in range(num_epochs):
for step, batch in tqdm(enumerate(train_dataloader), total=len(train_dataloader)):
clean_images = batch["images"].to(device)
# bruit à ajouter aux images
noise = torch.randn(clean_images.shape).to(clean_images.device)
bs = clean_images.shape[0]
# un pas de temps aléatoire pour chaque image
timesteps = torch.randint(
0,
image_pipe.scheduler.num_train_timesteps,
(bs,),
device=clean_images.device,
).long()
# Ajouter du bruit aux images propres en fonction de la magnitude du bruit à chaque pas de temps
# (il s'agit du processus de diffusion vers l'avant)
noisy_images = image_pipe.scheduler.add_noise(clean_images, noise, timesteps)
# Obtenir la prédiction du modèle pour le bruit
noise_pred = image_pipe.unet(noisy_images, timesteps, return_dict=False)[0]
# Comparez la prédiction avec le bruit réel :
loss = F.mse_loss(
noise_pred, noise
) # NB : essayer de prédire le bruit (eps) pas (noisy_ims-clean_ims) ou juste (clean_ims)
# Stocker pour un plot ultérieur
losses.append(loss.item())
# Mettre à jour les paramètres du modèle avec l'optimiseur sur la base de cette perte
loss.backward(loss)
# Accumulation des gradients
if (step + 1) % grad_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
print(
f"Epoch {epoch} average loss: {sum(losses[-len(train_dataloader):])/len(train_dataloader)}"
)
# Tracer la courbe de perte :
plt.plot(losses)
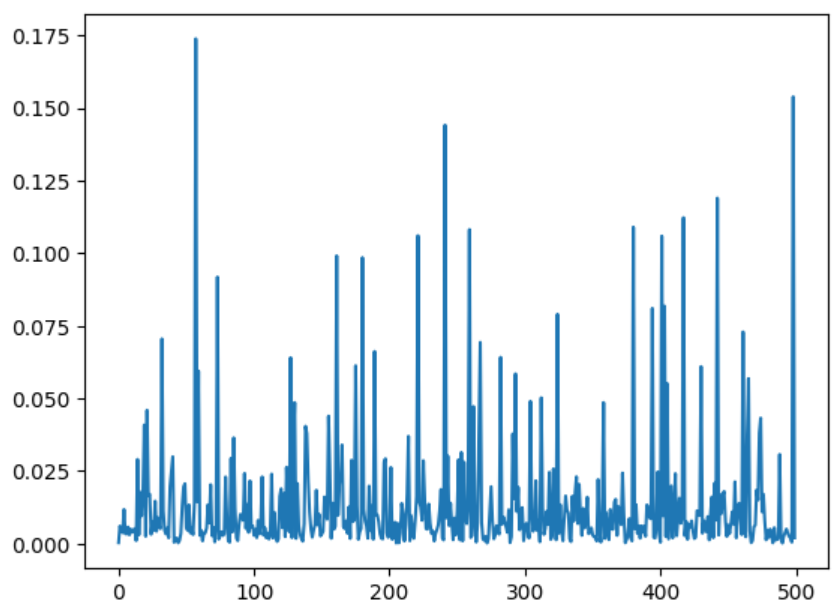
Considération 2 : notre signal de perte est extrêmement bruyant, puisque nous ne travaillons qu’avec quatre exemples à des niveaux de bruit aléatoires pour chaque étape. Ce n’est pas idéal pour l’entraînement. Une solution consiste à utiliser un taux d’apprentissage extrêmement faible pour limiter la taille de la mise à jour à chaque étape. Ce serait encore mieux si nous pouvions trouver un moyen d’obtenir les mêmes avantages qu’en utilisant une taille de batch plus importante sans que les besoins en mémoire ne montent en flèche…
Entrez dans l’accumulation des gradients. Si nous appelons loss.backward() plusieurs fois avant d’exécuter optimizer.step() et optimizer.zero_grad(), PyTorch accumule (somme) les gradients, fusionnant effectivement le signal de plusieurs batchs pour donner une seule (meilleure) estimation qui est ensuite utilisée pour mettre à jour les paramètres. Il en résulte moins de mises à jour totales, tout comme nous le verrions si nous utilisions une taille de batch plus importante. C’est quelque chose que de nombreux frameworks gèrent pour vous (par exemple, 🤗 Accelerate rend cela facile), mais il est agréable de le voir mis en œuvre à partir de zéro car il s’agit d’une technique utile pour traiter l’entraînement sous les contraintes de mémoire du GPU ! Comme vous pouvez le voir dans le code ci-dessus (après le commentaire # Gradient accumulation), il n’y a pas vraiment besoin de beaucoup de code.
✏️ À votre tour !
Voyez si vous pouvez ajouter l’accumulation des gradients à la boucle d’entraînement de l’unité 1. Comment se comporte-t-elle ? Réfléchissez à la manière dont vous pourriez ajuster le taux d’apprentissage en fonction du nombre d’étapes d’accumulation des gradients ; devrait-il rester identique à auparavant ?
Considération 3 : Cela prend encore beaucoup de temps, et afficher une mise à jour d’une ligne à chaque époque n’est pas suffisant pour nous donner une bonne idée de ce qui se passe. Nous devrions probablement :
- Générer quelques échantillons de temps en temps pour examiner visuellement la performance qualitativement au fur et à mesure que le modèle s’entraîne.
- Enregistrer des éléments tels que la perte et les générations d’échantillons pendant l’entraînement, peut-être en utilisant quelque chose comme Weights and Biases ou Tensorboard.
Nous avons créé un script rapide (finetune_model.py) qui reprend le code d’entraînement ci-dessus et y ajoute une fonctionnalité minimale de logging. Vous pouvez voir les logs d’un entraînement ci-dessous :
%wandb johnowhitaker/dm_finetune/2upaa341 # Vous aurez besoin d'un compte W&B pour que cela fonctionne - sautez si vous ne voulez pas vous connecter.
Il est amusant de voir comment les échantillons générés changent au fur et à mesure que l’entraînement progresse. Même si la perte ne semble pas s’améliorer beaucoup, on peut voir une progression du domaine original (images de chambres à coucher) vers les nouvelles données d’entraînement (wikiart). A la fin de ce notebook se trouve un code commenté pour finetuné un modèle en utilisant ce script comme alternative à l’exécution de la cellule ci-dessus.
✏️ À votre tour !
Voyez si vous pouvez modifier l’exemple officiel de script d’entraînement que nous avons vu dans l’unité 1 pour commencer avec un modèle pré-entraîné plutôt que d’entraîner à partir de zéro. Comparez-le au script minimal dont le lien figure ci-dessus ; quelles sont les fonctionnalités supplémentaires qui manquent au script minimal ?
En générant quelques images avec ce modèle, nous pouvons voir que ces visages ont déjà l’air très étranges !
x = torch.randn(8, 3, 256, 256).to(device) # Batch de 8
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5);

Considération 4 : Le finetuning peut être tout à fait imprévisible ! Si nous entraînions plus longtemps, nous pourrions voir des papillons parfaits. Mais les étapes intermédiaires peuvent être extrêmement intéressantes en elles-mêmes, surtout si vos intérêts sont plutôt artistiques ! Entraînez sur des périodes très courtes ou très longues et faites varier le taux d’apprentissage pour voir comment cela affecte les types de résultats produits par le modèle final.
Code pour finetuner un modèle en utilisant le script d’exemple minimal que nous avons utilisé sur le modèle de démonstration WikiArt
Si vous souhaitez entraîner un modèle similaire à celui que nous avons créé sur WikiArt, vous pouvez décommenter et exécuter les cellules ci-dessous. Comme cela prend un certain temps et peut épuiser la mémoire de votre GPU, nous vous conseillons de le faire après avoir parcouru le reste de ce notebook.
## Pour télécharger le script de finetuning :
# !wget https://github.com/huggingface/diffusion-models-class/raw/main/unit2/finetune_model.py
## Pour exécuter le script, entraînant le modèle de visage sur des visages vintage
## (l'idéal est d'exécuter ce script dans un terminal) :
# !python finetune_model.py --image_size 128 --batch_size 8 --num_epochs 16\
# --grad_accumulation_steps 2 --start_model "google/ddpm-celebahq-256"\
# --dataset_name "Norod78/Vintage-Faces-FFHQAligned" --wandb_project 'dm-finetune'\
# --log_samples_every 100 --save_model_every 1000 --model_save_name 'vintageface'
Sauvegarde et chargement des pipelines finetunés
Maintenant que nous avons finetuné le UNet dans notre modèle de diffusion, sauvegardons-le dans un dossier local en exécutant :
image_pipe.save_pretrained("my-finetuned-model")
Comme nous l’avons vu dans l’unité 1, cela permet de sauvegarder la configuration, le modèle et le planificateur :
!ls {"my-finetuned-model"}
Ensuite, vous pouvez suivre les mêmes étapes que celles décrites dans le notebook d’introduction à 🤗 Diffusers de l’unité 1 pour pousser le modèle vers le Hub en vue d’une utilisation ultérieure :
# Code pour télécharger un pipeline sauvegardé localement vers le Hub
from huggingface_hub import HfApi, ModelCard, create_repo, get_full_repo_name
# Mise en place du repo et téléchargement des fichiers
model_name = "ddpm-celebahq-finetuned-butterflies-2epochs" # @param Le nom que vous souhaitez lui donner sur le Hub
local_folder_name = "my-finetuned-model" # @param Créé par le script ou par vous via image_pipe.save_pretrained('save_name')
description = "Describe your model here" # @param
hub_model_id = get_full_repo_name(model_name)
create_repo(hub_model_id)
api = HfApi()
api.upload_folder(
folder_path=f"{local_folder_name}/scheduler", path_in_repo="", repo_id=hub_model_id
)
api.upload_folder(
folder_path=f"{local_folder_name}/unet", path_in_repo="", repo_id=hub_model_id
)
api.upload_file(
path_or_fileobj=f"{local_folder_name}/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id,
)
# Ajouter une carte modèle (facultatif mais sympa !)
content = f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Example Fine-Tuned Model for Unit 2 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
{description}
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('{hub_model_id}')
image = pipeline().images[0]
image
```python
"""
card = ModelCard(content)
card.push_to_hub(hub_model_id)
'https://huggingface.co/lewtun/ddpm-celebahq-finetuned-butterflies-2epochs/blob/main/README.md'
Félicitations, vous avez maintenant finetuné votre premier modèle de diffusion !
Pour le reste de ce notebook, nous utiliserons un modèle que nous avons finetuné à partir d’un modèle entraîné sur LSUN bedrooms environ une fois sur le WikiArt dataset. Si vous préférez, vous pouvez sauter cette cellule et utiliser le pipeline faces/butterflies que nous avons finetuné dans la section précédente ou en charger un depuis le Hub à la place :
# Chargement du pipeline pré-entraîné
pipeline_name = "johnowhitaker/sd-class-wikiart-from-bedrooms"
image_pipe = DDPMPipeline.from_pretrained(pipeline_name).to(device)
# Échantillon d'images avec un planificateur DDIM sur 40 étapes
scheduler = DDIMScheduler.from_pretrained(pipeline_name)
scheduler.set_timesteps(num_inference_steps=40)
# Point de départ aléatoire (batch de 8 images)
x = torch.randn(8, 3, 256, 256).to(device)
# Boucle d'échantillonnage minimale
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = scheduler.step(noise_pred, t, x).prev_sample
# Voir les résultats
grid = torchvision.utils.make_grid(x, nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5);

Considération 5 : Il est souvent difficile de savoir si le finetuné fonctionne bien, et ce que l’on entend par “bonnes performances” peut varier selon le cas d’utilisation. Par exemple, si vous finetuné un modèle conditionné par du texte comme Stable Diffusion sur un petit jeu de données, vous voudrez probablement qu’il conserve la plus grande partie de son apprentissage original afin de pouvoir comprendre des prompts arbitraires non couverts par votre nouveau jeu de données, tout en s’adaptant pour mieux correspondre au style de vos nouvelles données d’entraînement. Cela pourrait signifier l’utilisation d’un faible taux d’apprentissage avec quelque chose comme la moyenne exponentielle du modèle, comme démontré dans cet excellent article de blog sur la création d’une version Pokemon de Stable Diffusion. Dans une autre situation, vous pouvez vouloir ré-entraîner complètement un modèle sur de nouvelles données (comme notre exemple chambre → wikiart), auquel cas un taux d’apprentissage plus élevé et un entraînement plus poussé s’avèrent judicieux. Même si le graphique de la perte ne montre pas beaucoup d’amélioration, les échantillons s’éloignent clairement des données d’origine et s’orientent vers des résultats plus “artistiques”, bien qu’ils restent pour la plupart incohérents.
Ce qui nous amène à la section suivante, où nous examinons comment nous pourrions ajouter des conseils supplémentaires à un tel modèle pour mieux contrôler les résultats.
Guidage
Que faire si l’on souhaite exercer un certain contrôle sur les échantillons générés ? Par exemple, supposons que nous voulions biaiser les images générées pour qu’elles soient d’une couleur spécifique. Comment procéder ? C’est là qu’intervient le guidage, une technique qui permet d’ajouter un contrôle supplémentaire au processus d’échantillonnage.
La première étape consiste à créer notre fonction de conditionnement : une mesure (perte) que nous souhaitons minimiser. En voici une pour l’exemple de la couleur, qui compare les pixels d’une image à une couleur cible (par défaut, une sorte de sarcelle claire) et renvoie l’erreur moyenne :
def color_loss(images, target_color=(0.1, 0.9, 0.5)):
"""Étant donné une couleur cible (R, G, B), retourner une perte correspondant à la distance moyenne entre
les pixels de l'image et cette couleur. Par défaut, il s'agit d'une couleur sarcelle claire : (0.1, 0.9, 0.5)"""
target = (
torch.tensor(target_color).to(images.device) * 2 - 1
) # Map target color to (-1, 1)
target = target[
None, :, None, None
] # Obtenir la forme nécessaire pour fonctionner avec les images (b, c, h, w)
error = torch.abs(
images - target
).mean() # Différence absolue moyenne entre les pixels de l'image et la couleur cible
return error
Ensuite, nous allons créer une version modifiée de la boucle d’échantillonnage où, à chaque étape, nous ferons ce qui suit :
- Créer une nouvelle version de
xavecrequires_grad = True - Calculer la version débruitée (
x0) - Introduire la version prédite
x0dans notre fonction de perte - Trouver le gradient de cette fonction de perte par rapport à
x - Utiliser ce gradient de conditionnement pour modifier
xavant d’utiliser le planificateur, en espérant pousser x dans une direction qui conduira à une perte plus faible selon notre fonction d’orientation.
Il existe deux variantes que vous pouvez explorer. Dans la première, nous fixons requires_grad sur x après avoir obtenu notre prédiction de bruit du UNet, ce qui est plus efficace en termes de mémoire (puisque nous n’avons pas à retracer les gradients à travers le modèle de diffusion), mais donne un gradient moins précis. Dans le second cas, nous définissons d’abord requires_grad sur x, puis nous le faisons passer par l’unet et nous calculons le x0 prédit.
# Variante 1 : méthode rapide
# L'échelle de guidance détermine l'intensité de l'effet
guidance_loss_scale = 40 # Envisagez de modifier cette valeur à 5, ou à 100
x = torch.randn(8, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
# Préparer l'entrée du modèle
model_input = scheduler.scale_model_input(x, t)
# Prédire le bruit résiduel
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
# Fixer x.requires_grad à True
x = x.detach().requires_grad_()
# Obtenir la valeur prédite x0
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# Calculer la perte
loss = color_loss(x0) * guidance_loss_scale
if i % 10 == 0:
print(i, "loss:", loss.item())
# Obtenir le gradient
cond_grad = -torch.autograd.grad(loss, x)[0]
# Modifier x en fonction de ce gradient
x = x.detach() + cond_grad
# Le planificateur
x = scheduler.step(noise_pred, t, x).prev_sample
# Voir le résultat
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))
0 loss: 27.279136657714844
10 loss: 11.286816596984863
20 loss: 10.683112144470215
30 loss: 10.942476272583008

Cette deuxième option nécessite presque le double de RAM GPU pour fonctionner, même si nous ne générons qu’un batch de quatre images au lieu de huit. Voyez si vous pouvez repérer la différence et réfléchissez à la raison pour laquelle cette méthode est plus « précise » :
# Variante 2 : définir x.requires_grad avant de calculer les prédictions du modèle
guidance_loss_scale = 40
x = torch.randn(4, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
# Définir requires_grad avant la passe avant du modèle
x = x.detach().requires_grad_()
model_input = scheduler.scale_model_input(x, t)
# prédire (avec grad cette fois)
noise_pred = image_pipe.unet(model_input, t)["sample"]
# Obtenir la valeur prédite x0 :
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# Calculer la perte
loss = color_loss(x0) * guidance_loss_scale
if i % 10 == 0:
print(i, "loss:", loss.item())
# Obtenir le gradient
cond_grad = -torch.autograd.grad(loss, x)[0]
# Modifier x en fonction de ce gradient
x = x.detach() + cond_grad
# Le planificateur
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))
0 loss: 30.750328063964844
10 loss: 18.550724029541016
20 loss: 17.515094757080078
30 loss: 17.55681037902832

Dans la seconde variante, les besoins en mémoire sont plus importants et l’effet est moins prononcé, de sorte que vous pouvez penser qu’elle est inférieure. Cependant, les résultats sont sans doute plus proches des types d’images sur lesquels le modèle a été entraîné, et vous pouvez toujours augmenter l’échelle de guidage pour obtenir un effet plus important. L’approche que vous utiliserez dépendra en fin de compte de ce qui fonctionne le mieux sur le plan expérimental.
✏️ À votre tour !
Choisissez votre couleur préférée et recherchez ses valeurs dans l’espace RGB. Modifiez la lignecolor_loss()dans la cellule ci-dessus pour recevoir ces nouvelles valeurs RGB et examinez les résultats ; correspondent-ils à ce que vous attendez ?
Guidage avec CLIP
Guider vers une couleur nous donne un peu de contrôle, mais que se passerait-il si nous pouvions simplement taper un texte décrivant ce que nous voulons ?
CLIP est un modèle créé par OpenAI qui nous permet de comparer des images à des légendes textuelles. C’est extrêmement puissant, car cela nous permet de quantifier à quel point une image correspond à un prompt. Et comme le processus est différentiable, nous pouvons l’utiliser comme fonction de perte pour guider notre modèle de diffusion !
Nous n’entrerons pas dans les détails ici. L’approche de base est la suivante :
- Enchâsser le prompt pour obtenir un enchâssement CLIP à 512 dimensions
- Pour chaque étape du processus du modèle de diffusion :
- Créer plusieurs variantes de l’image débruitée prédite (le fait d’avoir plusieurs variantes permet d’obtenir un signal de perte plus propre).
- Pour chacune d’entre elles, enchâsser l’image avec CLIP et comparez cet enchâssement avec celui du prompt (à l’aide d’une mesure appelée « distance du grand cercle »).
- Calculer le gradient de cette perte par rapport à l’image bruyante actuelle x et utiliser ce gradient pour modifier x avant de le mettre à jour avec le planificateur.
Pour une explication plus approfondie de CLIP, consultez cette leçon sur le sujet ou ce rapport sur le projet OpenCLIP que nous utilisons pour charger le modèle CLIP. Exécutez la cellule suivante pour charger un modèle CLIP :
import open_clip
clip_model, _, preprocess = open_clip.create_model_and_transforms(
"ViT-B-32", pretrained="openai"
)
clip_model.to(device)
# Transformations pour redimensionner et augmenter une image + normalisation pour correspondre aux données entraînées par CLIP
tfms = torchvision.transforms.Compose(
[
torchvision.transforms.RandomResizedCrop(224), # CROP aléatoire à chaque fois
torchvision.transforms.RandomAffine(
5
), # Une augmentation aléatoire possible : biaiser l'image
torchvision.transforms.RandomHorizontalFlip(), # Vous pouvez ajouter des augmentations supplémentaires si vous le souhaitez
torchvision.transforms.Normalize(
mean=(0.48145466, 0.4578275, 0.40821073),
std=(0.26862954, 0.26130258, 0.27577711),
),
]
)
# Et définir une fonction de perte qui prend une image, l'enchâsse et la compare avec les caractéristiques textuelles du prompt
def clip_loss(image, text_features):
image_features = clip_model.encode_image(
tfms(image)
) # Note : applique les transformations ci-dessus
input_normed = torch.nn.functional.normalize(image_features.unsqueeze(1), dim=2)
embed_normed = torch.nn.functional.normalize(text_features.unsqueeze(0), dim=2)
dists = (
input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2)
) # Distance du grand cercle
return dists.mean()
Une fois la fonction de perte définie, notre boucle d’échantillonnage guidé ressemble aux exemples précédents, en remplaçant color_loss() par notre nouvelle fonction de perte basée sur CLIP :
prompt = "Red Rose (still life), red flower painting" # @param
# Explorer en changeant ça
guidance_scale = 8 # @param
n_cuts = 4 # @param
# Plus d'étapes -> plus de temps pour que le guidage ait un effet
scheduler.set_timesteps(50)
# Nous enchâssons un prompt avec CLIP comme cible
text = open_clip.tokenize([prompt]).to(device)
with torch.no_grad(), torch.cuda.amp.autocast():
text_features = clip_model.encode_text(text)
x = torch.randn(4, 3, 256, 256).to(
device
) # L'utilisation de la RAM est élevée, vous ne voulez peut-être qu'une seule image à la fois.
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
# prédire le bruit résiduel
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
cond_grad = 0
for cut in range(n_cuts):
# nécessite un grad sur x
x = x.detach().requires_grad_()
# Obtenir le x0 prédit
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# Calculer la perte
loss = clip_loss(x0, text_features) * guidance_scale
# Obtenir le gradient (échelle par n_cuts puisque nous voulons la moyenne)
cond_grad -= torch.autograd.grad(loss, x)[0] / n_cuts
if i % 25 == 0:
print("Step:", i, ", Guidance loss:", loss.item())
# Modifier x en fonction de ce gradient
alpha_bar = scheduler.alphas_cumprod[i]
x = (
x.detach() + cond_grad * alpha_bar.sqrt()
) # Note the additional scaling factor here!
# Le planificateur
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x.detach(), nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))
Step: 0 , Guidance loss: 7.437869548797607
Step: 25 , Guidance loss: 7.174620628356934

Cela ressemble un peu à des roses ! Ce n’est pas parfait, mais si vous jouez avec les paramètres, vous pouvez obtenir des images agréables.
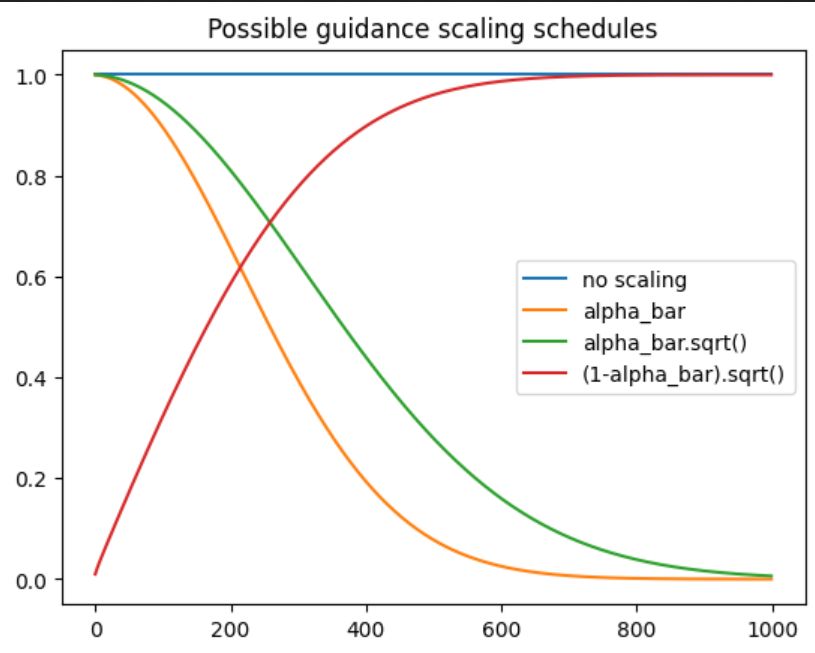
Si vous examinez le code ci-dessus, vous verrez que nous mettons à l’échelle le gradient de conditionnement par un facteur de alpha_bar.sqrt(). Il existe des théories sur la “bonne” manière d’échelonner ces gradients, mais en pratique, vous pouvez expérimenter. Pour certains types de guidage, vous voudrez peut-être que la plupart des effets soient concentrés dans les premières étapes, pour d’autres (par exemple, une perte de style axée sur les textures), vous préférerez peut-être qu’ils n’interviennent que vers la fin du processus de génération. Quelques programmes possibles sont présentés ci-dessous :
plt.plot([1 for a in scheduler.alphas_cumprod], label="no scaling")
plt.plot([a for a in scheduler.alphas_cumprod], label="alpha_bar")
plt.plot([a.sqrt() for a in scheduler.alphas_cumprod], label="alpha_bar.sqrt()")
plt.plot(
[(1 - a).sqrt() for a in scheduler.alphas_cumprod], label="(1-alpha_bar).sqrt()"
)
plt.legend()
plt.title("Possible guidance scaling schedules")
Expérimentez avec différents planificateurs, échelles de guidage et toute autre astuce à laquelle vous pouvez penser (l’écrêtage des gradients dans une certaine plage est une modification populaire) pour voir jusqu’à quel point vous pouvez obtenir ce résultat ! N’oubliez pas non plus d’essayer d’intervertir d’autres modèles. Peut-être le modèle de visages que nous avons chargé au début ; pouvez-vous le guider de manière fiable pour produire un visage masculin ? Que se passe-t-il si vous combinez le guidage CLIP avec la perte de couleur que nous avons utilisée plus tôt ? Etc.
Si vous consultez quelques codes pour la diffusion guidée par CLIP en pratique, vous verrez une approche plus complexe avec une meilleure classe pour choisir des découpes aléatoires dans les images et de nombreux ajustements supplémentaires de la fonction de perte pour de meilleures performances. Avant l’apparition des modèles de diffusion conditionnés par le texte, il s’agissait du meilleur système de conversion texte-image qui soit ! La petite version de notre jouet peut encore être améliorée, mais elle capture l’idée principale : grâce au guidage et aux capacités étonnantes de CLIP, nous pouvons ajouter le contrôle du texte à un modèle de diffusion inconditionnel 🎨.
Partager une boucle d’échantillonnage personnalisée en tant que démo Gradio
Vous avez peut-être trouvé une perte amusante pour guider la génération et vous souhaitez maintenant partager avec le monde entier votre modèle finetuné et cette stratégie d’échantillonnage personnalisée…
Entrez dans Gradio. Gradio est un outil gratuit et open-source qui permet aux utilisateurs de créer et de partager facilement des modèles interactifs d’apprentissage automatique via une simple interface web. Avec Gradio, les utilisateurs peuvent construire des interfaces personnalisées pour leurs modèles d’apprentissage automatique, qui peuvent ensuite être partagés avec d’autres par le biais d’une URL unique. Il est également intégré à 🤗 Spaces, ce qui permet d’héberger facilement des démos et de les partager avec d’autres.
Nous placerons notre logique de base dans une fonction qui prend certaines entrées et produit une image en sortie. Cette fonction peut ensuite être enveloppée dans une interface simple qui permet à l’utilisateur de spécifier certains paramètres (qui sont transmis en tant qu’entrées à la fonction principale de génération). De nombreux composants sont disponibles ; pour cet exemple, nous utiliserons un curseur pour l’échelle d’orientation et un sélecteur de couleurs pour définir la couleur cible.
!pip install -q gradio
import gradio as gr
from PIL import Image, ImageColor
# La fonction qui fait le gros du travail
def generate(color, guidance_loss_scale):
target_color = ImageColor.getcolor(color, "RGB") # Couleur cible en RGB
target_color = [a / 255 for a in target_color] # Rééchelonner de (0, 255) à (0, 1)
x = torch.randn(1, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = x.detach().requires_grad_()
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
loss = color_loss(x0, target_color) * guidance_loss_scale
cond_grad = -torch.autograd.grad(loss, x)[0]
x = x.detach() + cond_grad
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
im = Image.fromarray(np.array(im * 255).astype(np.uint8))
im.save("test.jpeg")
return im
# Voir la documentation de gradio pour les types d'entrées et de sorties disponibles.
inputs = [
gr.ColorPicker(label="color", value="55FFAA"), # Ajoutez ici toutes les entrées dont vous avez besoin
gr.Slider(label="guidance_scale", minimum=0, maximum=30, value=3),
]
outputs = gr.Image(label="result")
# Et l'interface minimale
demo = gr.Interface(
fn=generate,
inputs=inputs,
outputs=outputs,
examples=[
["#BB2266", 3],
["#44CCAA", 5], # Vous pouvez fournir des exemples d'entrées pour aider les gens à démarrer
],
)
demo.launch(debug=True) # debug=True vous permet de voir les erreurs et les sorties dans Colab
Il est possible de construire des interfaces beaucoup plus compliquées, avec un style fantaisiste et un large éventail d’entrées possibles, mais pour cette démo, nous la gardons aussi simple que possible.
Les démos sur 🤗 Spaces s’exécutent par défaut sur CPU, il est donc préférable de prototyper votre interface dans Colab (comme ci-dessus) avant de la migrer. Lorsque vous êtes prêt à partager votre démo, vous devez créer un Space, mettre en place un fichier requirements.txt listant les bibliothèques que votre code utilisera, puis placer tout le code dans un fichier app.py qui définit les fonctions pertinentes et l’interface.
Heureusement pour vous, il est également possible de “dupliquer” un Space. Vous pouvez visiter le Space ici et cliquer sur “Dupliquer cet espace” pour obtenir un modèle que vous pouvez ensuite modifier pour utiliser votre propre modèle et votre propre fonction d’orientation.
Dans les paramètres, vous pouvez configurer votre Space pour qu’il fonctionne avec du matériel plus sophistiqué (qui est facturé à l’heure). Vous avez créé quelque chose d’extraordinaire et vous voulez le partager sur un meilleur matériel, mais vous n’avez pas l’argent nécessaire ? Faites-le nous savoir via Discord et nous verrons si nous pouvons vous aider !
Résumé et prochaines étapes
Nous avons couvert beaucoup de choses dans ce notebook ! Récapitulons les idées principales :
- Il est relativement facile de charger des modèles existants et de les échantillonner avec différents planificateurs
- Le finetuning ressemble à l’entraînement à partir de zéro, sauf qu’en partant d’un modèle existant, nous espérons obtenir de meilleurs résultats plus rapidement.
- Pour finetuner de grands modèles sur de grandes images, nous pouvons utiliser des astuces comme l’accumulation de gradient pour contourner les limitations de la taille des batchs.
- L’enregistrement d’échantillons d’images est important pour le finetuning, où une courbe de perte peut ne pas fournir beaucoup d’informations utiles.
- Le guidage nous permet de prendre un modèle inconditionnel et d’orienter le processus de génération sur la base d’une fonction de guidage/perte, où à chaque étape nous trouvons le gradient de la perte par rapport à l’image bruitée $x$ et l’actualisons en fonction de ce gradient avant de passer à l’étape temporelle suivante.
- Le guidage avec CLIP nous permet de contrôler des modèles inconditionnels avec du texte !
Pour mettre cela en pratique, voici quelques étapes spécifiques que vous pouvez suivre :
- Finetuné votre propre modèle et le pousser vers le Hub. Cela implique de choisir un point de départ (par exemple, un modèle entraîné sur faces, bedrooms, cats ou wikiart et un jeu de données (peut-être ces faces d’animaux ou vos propres images), puis d’entraîner soit le code de ce notebook, soit le script d’exemple (utilisation de démonstration ci-dessous).
- Explorer le guidage en utilisant votre modèle finetuné, soit en utilisant l’une des fonctions de guidage de l’exemple (color_loss ou CLIP), soit en inventant la vôtre.
- Partagez une démo basée sur ceci en utilisant Gradio, soit en modifiant le Space d’exemple pour utiliser votre propre modèle, soit en créant votre propre version personnalisée avec plus de fonctionnalités.