Implémentation à partir de 0
Il est parfois utile de considérer la version la plus simple possible d’une chose pour mieux en comprendre le fonctionnement. C’est ce que nous allons essayer de faire dans ce notebook, en commençant par un modèle de diffusion jouet pour voir comment les différents éléments fonctionnent, puis en examinant en quoi ils diffèrent d’une mise en œuvre plus complexe.
Nous examinerons :
- Le processus de corruption (ajouter du bruit aux données)
- Ce qu’est un UNet, et comment en implémenter un extrêmement minimal à partir de zéro
- L’entraînement au modèle de diffusion
- La théorie de l’échantillonnage
Ensuite, nous comparerons nos versions avec l’implémentation DDPM des diffuseurs, en explorant :
- Les améliorations par rapport à notre mini UNet
- Le schéma de bruit du DDPM
- Les différences dans l’objectif d’entraînement
- Le conditionnement du pas de temps
- Les approches d’échantillonnage
Ce notebook est assez approfondi, et peut être sauté en toute sécurité si vous n’êtes pas enthousiaste à l’idée d’une plongée en profondeur à partir de zéro !
Il convient également de noter que la plupart du code ici est utilisé à des fins d’illustration, et nous ne recommandons pas de l’adopter directement pour votre propre travail (à moins que vous n’essayiez d’améliorer les exemples montrés ici à des fins d’apprentissage).
Configuration et importations
!pip install -q diffusers
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
Les données
Nous allons tester les choses avec un très petit jeu de données : MNIST. Si vous souhaitez donner au modèle un défi un peu plus difficile à relever sans rien changer d’autre, torchvision.datasets.FashionMNIST devrait faire l’affaire.
dataset = torchvision.datasets.MNIST(root="mnist/", train=True, download=True, transform=torchvision.transforms.ToTensor())
train_dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
x, y = next(iter(train_dataloader))
print('Input shape:', x.shape)
print('Labels:', y)
plt.imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
Input shape: torch.Size([8, 1, 28, 28])
Labels: tensor([1, 9, 7, 3, 5, 2, 1, 4])
Chaque image est un dessin en niveaux de gris de 28 par 28 pixels d’un chiffre, avec des valeurs allant de 0 à 1.
Le processus de corruption
Supposons que vous n’ayez lu aucun papier sur les modèles de diffusion, mais que vous sachiez que le processus implique l’ajout de bruit. Comment feriez-vous ?
Nous souhaitons probablement disposer d’un moyen simple de contrôler le degré de corruption. Et si nous prenions un paramètre pour la quantité de bruit à ajouter, et que nous le faisions :
noise = torch.rand_like(x)
noisy_x = (1-amount)*x + amount*noise
Si amount = 0, nous récupérons l’entrée sans aucun changement. Si le montant atteint $1$, nous récupérons du bruit sans aucune trace de l’entrée $x$. En mélangeant l’entrée avec du bruit de cette façon, nous gardons la sortie dans la même plage ($0$ à $1$).
Nous pouvons mettre cela en œuvre assez facilement (il suffit de surveiller les formes pour ne pas se faire piéger par les règles de diffusion) :
def corrupt(x, amount):
"""Corrompre l'entrée `x` en la mélangeant avec du bruit selon `amount`"""
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1) # Trier les formes pour que la transmission fonctionne
return x*(1-amount) + noise*amount
Et regarder les résultats visuellement pour voir que cela fonctionne comme prévu :
# Tracer les données d'entrée
fig, axs = plt.subplots(2, 1, figsize=(12, 5))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
# Ajouter du bruit
amount = torch.linspace(0, 1, x.shape[0]) # De gauche à droite -> plus de corruption
noised_x = corrupt(x, amount)
# Tracé de la version bruitée
axs[1].set_title('Corrupted data (-- amount increases -->)')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0], cmap='Greys')

Lorsque la quantité de bruit s’approche de 1, nos données commencent à ressembler à du bruit aléatoire pur. Mais pour la plupart des noise_amounts, vous pouvez deviner le chiffre assez bien. Pensez-vous que cela soit optimal ?
Le modèle
Nous aimerions un modèle qui prenne en compte des images bruitées de 28px et qui produise une prédiction de la même forme. Un choix populaire ici est une architecture appelée UNet. Inventé à l’origine pour les tâches de segmentation en imagerie médicale, un UNet se compose d’un “chemin de compression” par lequel les données sont comprimées et d’un “chemin d’expansion” par lequel elles s’étendent à nouveau jusqu’à la dimension d’origine (similaire à un autoencodeur), mais il comporte également des connexions de saut qui permettent aux informations et aux gradients de circuler à différents niveaux.
Certains UNets comportent des blocs complexes à chaque étape, mais pour cette petite démonstration, nous construirons un exemple minimal qui prend une image à un canal et la fait passer par trois couches convolutives sur le chemin descendant (les down_layers dans le diagramme et le code) et trois sur le chemin ascendant, avec des sauts de connexion entre les couches descendantes et ascendantes. Nous utiliserons max pooling pour le downsampling et nn.Upsample pour le upsampling plutôt que de nous appuyer sur des couches apprenantes comme les UNets plus complexes. Voici l’architecture approximative montrant le nombre de canaux dans la sortie de chaque couche :
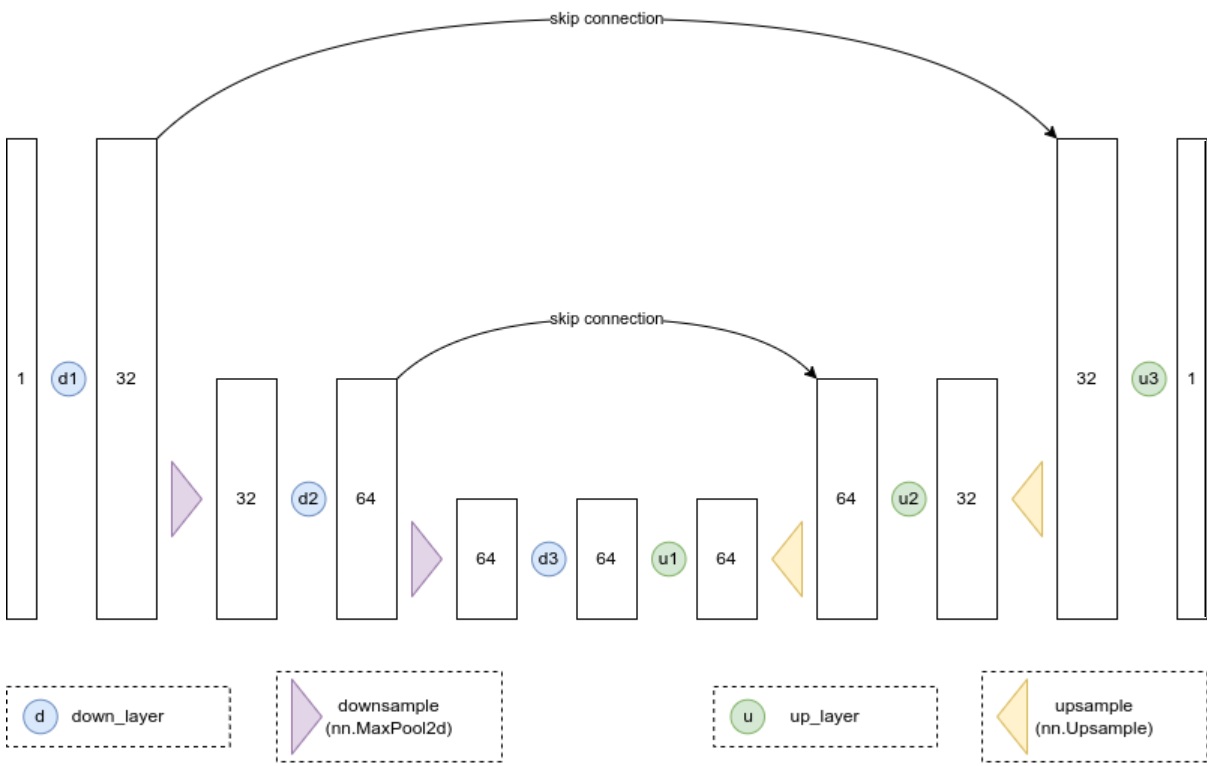
Voici à quoi cela ressemble dans le code :
class BasicUNet(nn.Module):
"""Une mise en œuvre minimale du UNet"""
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
self.down_layers = torch.nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 64, kernel_size=5, padding=2),
])
self.up_layers = torch.nn.ModuleList([
nn.Conv2d(64, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 32, kernel_size=5, padding=2),
nn.Conv2d(32, out_channels, kernel_size=5, padding=2),
])
self.act = nn.SiLU() # La fonction d'activation
self.downscale = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self, x):
h = []
for i, l in enumerate(self.down_layers):
x = self.act(l(x)) # À travers la couche et la fonction d'activation
if i < 2: # Pour toutes les couches sauf la troisième (dernière) :
h.append(x) # Stockage de la sortie pour la skip connexion
x = self.downscale(x) # Réduction d'échelle pour la couche suivante
for i, l in enumerate(self.up_layers):
if i > 0:
x = self.upscale(x) # Upscale
x += h.pop() # Récupération d'un résultat stocké (skip connection)
x = self.act(l(x)) # Par le biais de la couche et de la fonction d'activation
return x
Nous pouvons vérifier que la forme de la sortie est la même que celle de l’entrée, comme nous nous y attendions :
net = BasicUNet()
x = torch.rand(8, 1, 28, 28)
net(x).shape
torch.Size([8, 1, 28, 28])
Ce réseau compte un peu plus de 300 000 paramètres :
sum([p.numel() for p in net.parameters()])
309057
Vous pouvez envisager de modifier le nombre de canaux dans chaque couche ou d’intervertir les architectures si vous le souhaitez.
Entraîner le réseau
Que doit faire exactement le modèle ? Là encore, il y a plusieurs façons de procéder, mais pour cette démonstration, choisissons un cadre simple : étant donné une entrée corrompue noisy_x, le modèle doit produire sa meilleure estimation de ce à quoi ressemble l’original $x$. Nous comparerons cette valeur à la valeur réelle par le biais de l’erreur quadratique moyenne. Nous comparerons cette estimation à la valeur réelle par le biais de l’erreur quadratique moyenne.
Nous pouvons maintenant entraîner le réseau.
- Obtenir un batch de données
- Corrompre les données de manière aléatoire
- Nourrir le modèle avec ces données
- Comparer les prédictions du modèle avec les images propres pour calculer notre perte
- Mettre à jour les paramètres du modèle en conséquence.
N’hésitez pas à modifier ce modèle et à voir si vous pouvez l’améliorer !
# Chargeur de données (vous pouvez modifier la taille des batchs)
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# Combien de fois devrions-nous passer les données en revue ?
n_epochs = 3
# Créer le réseau
net = BasicUNet()
net.to(device)
# Notre fonction de perte
loss_fn = nn.MSELoss()
# L'optimiseur
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# Conserver une trace des pertes pour les consulter ultérieurement
losses = []
# La boucle d'entraînement
for epoch in range(n_epochs):
for x, y in train_dataloader:
# Obtenir des données et préparer la version corrompue
x = x.to(device) # Data on the GPU
noise_amount = torch.rand(x.shape[0]).to(device) # Prendre un montant de bruit aléatoirement
noisy_x = corrupt(x, noise_amount) # Create our noisy x
# Obtenir la prédiction du modèle
pred = net(noisy_x)
# Calculer la perte
loss = loss_fn(pred, x) # Dans quelle mesure la sortie est-elle proche du véritable x "propre" ?
# Rétropropager et mettre à jour les paramètres
opt.zero_grad()
loss.backward()
opt.step()
# Stocker la perte pour plus tard
losses.append(loss.item())
# Afficher la moyenne des valeurs de perte pour cette époque :
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
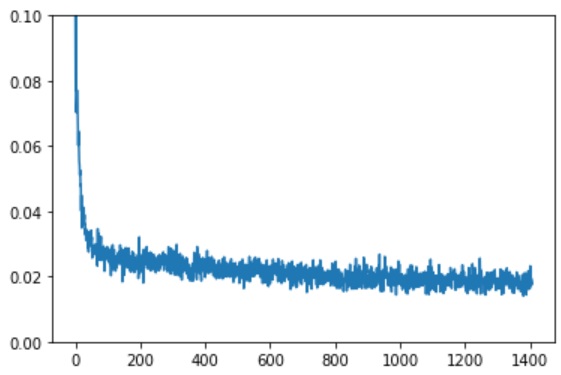
# Visualiser la courbe des pertes
plt.plot(losses)
plt.ylim(0, 0.1)
Finished epoch 0. Average loss for this epoch: 0.026736
Finished epoch 1. Average loss for this epoch: 0.020692
Finished epoch 2. Average loss for this epoch: 0.018887
Nous pouvons essayer de voir à quoi ressemblent les prédictions du modèle en saisissant un batch de données, en les corrompant à différents degrés et en visualisant ensuite les prédictions du modèle :
# Récupérer des données
x, y = next(iter(train_dataloader))
x = x[:8] # Seuls les 8 premiers sont utilisés pour faciliter le graphique
# Corruption avec une échelle de montants
amount = torch.linspace(0, 1, x.shape[0]) # De gauche à droite -> plus de corruption
noised_x = corrupt(x, amount)
# Obtenir les prédictions du modèle
with torch.no_grad():
preds = net(noised_x.to(device)).detach().cpu()
# Graphique
fig, axs = plt.subplots(3, 1, figsize=(12, 7))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0].clip(0, 1), cmap='Greys')
axs[1].set_title('Corrupted data')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0].clip(0, 1), cmap='Greys')
axs[2].set_title('Network Predictions')
axs[2].imshow(torchvision.utils.make_grid(preds)[0].clip(0, 1), cmap='Greys
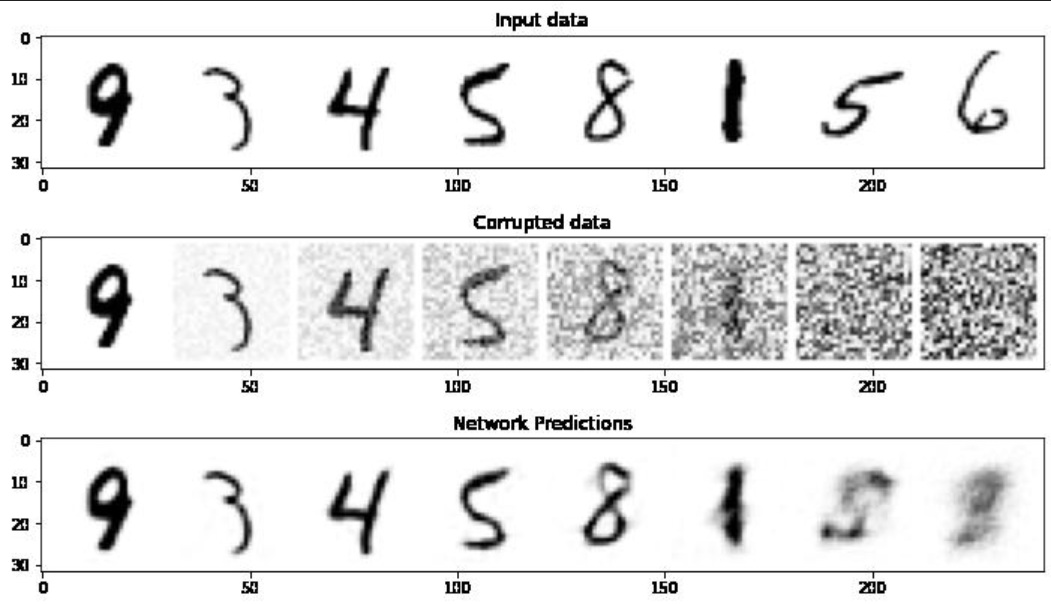
Vous pouvez constater que pour les montants les plus faibles, les prédictions sont plutôt bonnes ! Mais lorsque le niveau devient très élevé, le modèle a moins d’éléments pour travailler, et lorsque nous arrivons à amount=1, il produit un désordre flou proche de la moyenne du jeu de données pour essayer de couvrir ses paris sur ce à quoi la sortie pourrait ressembler…
Échantillonnage
Si nos prédictions à des niveaux de bruit élevés ne sont pas très bonnes, comment générer des images ?
Et si nous partions d’un bruit aléatoire, que nous regardions les prédictions du modèle, mais que nous ne nous rapprochions que très peu de cette prédiction (disons, 20 % du chemin). Nous disposons alors d’une image très bruyante dans laquelle il y a peut-être un soupçon de structure, que nous pouvons introduire dans le modèle pour obtenir une nouvelle prédiction. Nous espérons que cette nouvelle prédiction est légèrement meilleure que la première (puisque notre point de départ est légèrement moins bruité) et que nous pouvons donc faire un autre petit pas avec cette nouvelle et meilleure prédiction.
Nous répétons l’opération plusieurs fois et (si tout se passe bien) nous obtenons une image ! Voici ce processus illustré en seulement 5 étapes, en visualisant l’entrée du modèle (à gauche) et les images débruitées prédites (à droite) à chaque étape. Notez que même si le modèle prédit l’image débruitée dès l’étape 1, nous ne faisons qu’une partie du chemin. Au fil des étapes, les structures apparaissent et sont affinées, jusqu’à ce que nous obtenions nos résultats finaux.
n_steps = 5
x = torch.rand(8, 1, 28, 28).to(device) # Commencer au hasard
step_history = [x.detach().cpu()]
pred_output_history = []
for i in range(n_steps):
with torch.no_grad(): # Pas besoin de suivre les gradients pendant l'inférence
pred = net(x) # Prédire le x0 débruité
pred_output_history.append(pred.detach().cpu()) # Stocker les résultats du modèle pour les tracer
mix_factor = 1/(n_steps - i) # Dans quelle mesure nous nous rapprochons de la prédiction
x = x*(1-mix_factor) + pred*mix_factor # Déplacer une partie du chemin
step_history.append(x.detach().cpu()) # Stocker l'étape pour le graphique
fig, axs = plt.subplots(n_steps, 2, figsize=(9, 4), sharex=True)
axs[0,0].set_title('x (model input)')
axs[0,1].set_title('model prediction')
for i in range(n_steps):
axs[i, 0].imshow(torchvision.utils.make_grid(step_history[i])[0].clip(0, 1), cmap='Greys')
axs[i, 1].imshow(torchvision.utils.make_grid(pred_output_history[i])[0].clip(0, 1), cmap='Greys')

Nous pouvons diviser le processus en plusieurs étapes et espérer ainsi obtenir de meilleures images :
n_steps = 40
x = torch.rand(64, 1, 28, 28).to(device)
for i in range(n_steps):
noise_amount = torch.ones((x.shape[0], )).to(device) * (1-(i/n_steps))
with torch.no_grad():
pred = net(x)
mix_factor = 1/(n_steps - i)
x = x*(1-mix_factor) + pred*mix_factor
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ax.imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0].clip(0, 1), cmap='Greys')

Ce n’est pas génial, mais il y a des chiffres reconnaissables ! Vous pouvez expérimenter en entraînant plus longtemps (disons, 10 ou 20 époques) et en modifiant la configuration du modèle, le taux d’apprentissage, l’optimiseur, etc. N’oubliez pas non plus que fashionMNIST peut être remplacé en une ligne si vous voulez essayer un jeu de données un peu plus difficile.
Comparaison avec DDPM
Dans cette section, nous allons voir comment notre implémentation diffère de l’approche utilisée dans l’autre notebook (Introduction à Diffusers), qui est basé sur l’article de DDPM.
Nous verrons que
- Le diffuseur
UNet2DModelest un peu plus avancé que notre BasicUNet - Le processus de corruption est traité différemment
- L’objectif d’entraînement est différent, puisqu’il s’agit de prédire le bruit plutôt que l’image débruitée.
- Le modèle est conditionné sur la quantité de bruit présent via un conditionnement par pas de temps, où t est transmis comme un argument supplémentaire à la méthode forward.
- Il existe un certain nombre de stratégies d’échantillonnage différentes, qui devraient fonctionner mieux que notre version simpliste ci-dessus.
Un certain nombre d’améliorations ont été suggérées depuis la publication de l’article sur le DDPM, mais nous espérons que cet exemple est instructif en ce qui concerne les différentes décisions de conception possibles. Une fois que vous aurez lu cet article, vous pourrez vous plonger dans le document intitulé Elucidating the Design Space of Diffusion-Based Generative Models qui examine tous ces composants en détail et formule de nouvelles recommandations sur la manière d’obtenir les meilleures performances.
Si tout cela est trop technique ou intimidant, ne vous inquiétez pas ! N’hésitez pas à sauter le reste de ce notebook ou à le garder pour un jour de pluie.
Le UNet
Le modèle UNet2DModel de 🤗 Diffusers comporte un certain nombre d’améliorations par rapport à notre UNet de base ci-dessus :
- GroupNorm applique une normalisation par groupe aux entrées de chaque bloc
- Couches de dropout pour un entraînement plus doux
- Plusieurs couches de ResNet par bloc (si layers_per_block n’est pas fixé à 1)
- Attention (généralement utilisé uniquement pour les blocs à faible résolution)
- Conditionnement sur le pas de temps
- Blocs de sous-échantillonnage et de suréchantillonnage avec des paramètres pouvant être appris
Créons et inspectons un modèle UNet2DModel :
model = UNet2DModel(
sample_size=28, # la résolution de l'image cible
in_channels=1, # le nombre de canaux d'entrée, 3 pour les images RVB
out_channels=1, # le nombre de canaux de sortie
layers_per_block=2, # le nombre de couches ResNet à utiliser par bloc UNet
block_out_channels=(32, 64, 64), # Correspondant à peu près à notre exemple UNet de base
down_block_types=(
"DownBlock2D", # un bloc de sous-échantillonnage ResNet normal
"AttnDownBlock2D", # un bloc de sous-échantillonnage ResNet avec auto-attention spatiale
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # un bloc de suréchantillonnage ResNet avec auto-attention spatiale
"UpBlock2D", # un bloc de suréchantillonnage ResNet standard
),
)
print(model)
Afficher / masquer la sortie de print(model)
UNet2DModel(
(conv_in): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_proj): Timesteps()
(time_embedding): TimestepEmbedding(
(linear_1): Linear(in_features=32, out_features=128, bias=True)
(act): SiLU()
(linear_2): Linear(in_features=128, out_features=128, bias=True)
)
(down_blocks): ModuleList(
(0): DownBlock2D(
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 32, eps=1e-05, affine=True)
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=32, bias=True)
(norm2): GroupNorm(32, 32, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 32, eps=1e-05, affine=True)
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=32, bias=True)
(norm2): GroupNorm(32, 32, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)
(1): AttnDownBlock2D(
(attentions): ModuleList(
(0): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
(1): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 32, eps=1e-05, affine=True)
(conv1): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 64, eps=1e-05, affine=True)
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)
(2): AttnDownBlock2D(
(attentions): ModuleList(
(0): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
(1): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 64, eps=1e-05, affine=True)
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 64, eps=1e-05, affine=True)
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
)
)
(up_blocks): ModuleList(
(0): AttnUpBlock2D(
(attentions): ModuleList(
(0): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
(1): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
(2): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 128, eps=1e-05, affine=True)
(conv1): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 128, eps=1e-05, affine=True)
(conv1): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
)
(2): ResnetBlock2D(
(norm1): GroupNorm(32, 128, eps=1e-05, affine=True)
(conv1): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(1): AttnUpBlock2D(
(attentions): ModuleList(
(0): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
(1): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
(2): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 128, eps=1e-05, affine=True)
(conv1): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 128, eps=1e-05, affine=True)
(conv1): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
)
(2): ResnetBlock2D(
(norm1): GroupNorm(32, 96, eps=1e-05, affine=True)
(conv1): Conv2d(96, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(96, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(2): UpBlock2D(
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 96, eps=1e-05, affine=True)
(conv1): Conv2d(96, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=32, bias=True)
(norm2): GroupNorm(32, 32, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(96, 32, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 64, eps=1e-05, affine=True)
(conv1): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=32, bias=True)
(norm2): GroupNorm(32, 32, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
)
(2): ResnetBlock2D(
(norm1): GroupNorm(32, 64, eps=1e-05, affine=True)
(conv1): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=32, bias=True)
(norm2): GroupNorm(32, 32, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
)
)
)
)
(mid_block): UNetMidBlock2D(
(attentions): ModuleList(
(0): AttentionBlock(
(group_norm): GroupNorm(32, 64, eps=1e-05, affine=True)
(query): Linear(in_features=64, out_features=64, bias=True)
(key): Linear(in_features=64, out_features=64, bias=True)
(value): Linear(in_features=64, out_features=64, bias=True)
(proj_attn): Linear(in_features=64, out_features=64, bias=True)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 64, eps=1e-05, affine=True)
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 64, eps=1e-05, affine=True)
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=128, out_features=64, bias=True)
(norm2): GroupNorm(32, 64, eps=1e-05, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
)
(conv_norm_out): GroupNorm(32, 32, eps=1e-05, affine=True)
(conv_act): SiLU()
(conv_out): Conv2d(32, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
Comme vous pouvez le constater, il y a un peu plus de choses qui se passent ! Il a également beaucoup plus de paramètres que notre BasicUNet :
sum([p.numel() for p in model.parameters()])
1707009 # 1,7M contre les ~309k paramètres du BasicUNet
Nous pouvons reproduire l’entraînement présenté ci-dessus en utilisant ce modèle à la place de notre modèle original. Nous devons passer x et le pas de temps au modèle (ici, nous passons toujours t=0 pour montrer qu’il fonctionne sans ce conditionnement de pas de temps et pour faciliter le code d’échantillonnage, mais vous pouvez également essayer d’introduire (amount*1000) pour obtenir un équivalent de pas de temps à partir du montant de la corruption). Les lignes modifiées sont indiquées par #<<< si vous souhaitez inspecter le code.
# Dataloader (vous pouvez modifier la taille du batch)
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# Combien de fois devrions-nous passer les données en revue ?
n_epochs = 3
# Créer le réseau
net = UNet2DModel(
sample_size=28, # la résolution de l'image cible
in_channels=1, # le nombre de canaux d'entrée, 3 pour les images RVB
out_channels=1, # le nombre de canaux de sortie
layers_per_block=2, # le nombre de couches ResNet à utiliser par bloc UNet
block_out_channels=(32, 64, 64), # Correspondant à peu près à notre exemple UNet de base
down_block_types=(
"DownBlock2D", # un bloc de sous-échantillonnage ResNet normal
"AttnDownBlock2D", # un bloc de sous-échantillonnage ResNet avec auto-attention spatiale
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # un bloc de suréchantillonnage ResNet avec auto-attention spatiale
"UpBlock2D", # un bloc de suréchantillonnage ResNet standard
),
)
net.to(device)
# Notre protection contre la perte
loss_fn = nn.MSELoss()
# L'optimiseur
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# Conserver une trace des pertes pour les visualiser plus tard
losses = []
# La boucle d'entraînement
for epoch in range(n_epochs):
for x, y in train_dataloader:
# Obtenir des données et préparer la version corrompue
x = x.to(device) # Data on the GPU
noise_amount = torch.rand(x.shape[0]).to(device) # Choisir des quantités de bruit aléatoires
noisy_x = corrupt(x, noise_amount) # Créer notre bruit x
# Obtenir la prédiction du modèle
pred = net(noisy_x, 0).sample #<<< En utilisant toujours le pas de temps 0, en ajoutant .sample
# Calculer la perte
loss = loss_fn(pred, x) # Dans quelle mesure la sortie est-elle proche du véritable x "propre" ?
# Rétropropager et mettre à jour les paramètres
opt.zero_grad()
loss.backward()
opt.step()
# Stocker la perte pour plus tard
losses.append(loss.item())
# Afficher la moyenne des valeurs de perte pour cette époque :
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
# Graphique
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
# Perte
axs[0].plot(losses)
axs[0].set_ylim(0, 0.1)
axs[0].set_title('Loss over time')
# Échantillons
n_steps = 40
x = torch.rand(64, 1, 28, 28).to(device)
for i in range(n_steps):
noise_amount = torch.ones((x.shape[0], )).to(device) * (1-(i/n_steps)) # De haut en bas
with torch.no_grad():
pred = net(x, 0).sample
mix_factor = 1/(n_steps - i)
x = x*(1-mix_factor) + pred*mix_factor
axs[1].imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0].clip(0, 1), cmap='Greys')
axs[1].set_title('Generated Samples')
Finished epoch 0. Average loss for this epoch: 0.018925
Finished epoch 1. Average loss for this epoch: 0.012785
Finished epoch 2. Average loss for this epoch: 0.011694
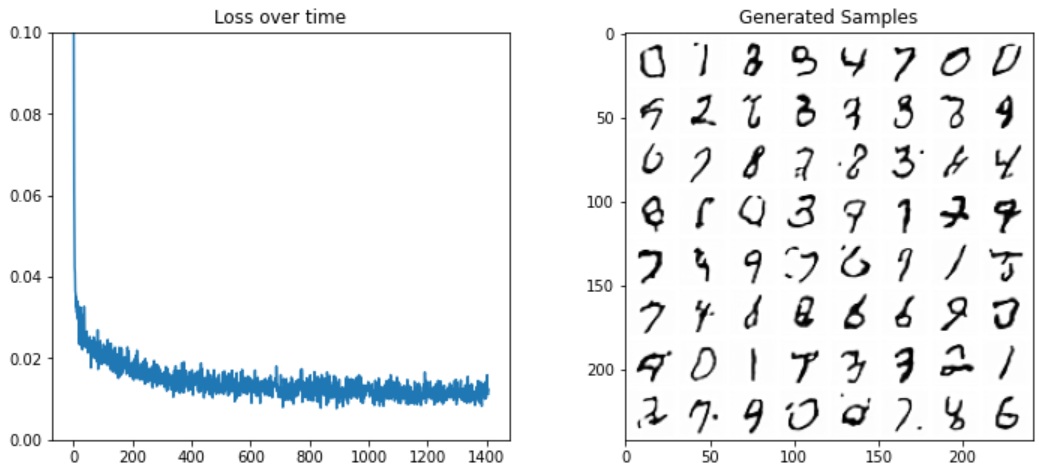
Ces résultats sont bien meilleurs que notre première série de résultats ! Vous pouvez envisager de modifier la configuration du Unet ou de prolonger l’entraînement afin d’obtenir des performances encore meilleures.
Le processus de corruption
Le papier DDPM décrit un processus de corruption qui ajoute une petite quantité de bruit à chaque « pas de temps ». Étant donné $x_{t-1}$ pour un certain pas de temps, nous pouvons obtenir la version suivante (légèrement plus bruitée) $x_t$ avec :
\[\begin{aligned} q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) &= \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t\mathbf{I}) \\ q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) &= \prod^T_{t=1} q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) \end{aligned}\]Nous prenons $x_{t-1}$, l’échelonnons de $\sqrt{1 - \beta_t}$ et ajoutons du bruit échelonné de $\beta_t$.
Ce $\beta$ est défini pour chaque t en fonction d’un certain planificateur, et détermine la quantité de bruit ajoutée par pas de temps.
Nous ne voulons pas nécessairement faire cette opération 500 fois pour obtenir $x_{500}$, nous avons donc une autre formule pour obtenir $x_t$ pour n’importe quel t étant donné $x_0$ :
où :
\[\bar{\alpha}_t = \prod_{i=1}^{T} \alpha_i,\quad \alpha_i = 1 - \beta_i\]noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
plt.plot(noise_scheduler.alphas_cumprod.cpu() ** 0.5, label=r"${\sqrt{\bar{\alpha}_t}}$")
plt.plot((1 - noise_scheduler.alphas_cumprod.cpu()) ** 0.5, label=r"$\sqrt{(1 - \bar{\alpha}_t)}$")
plt.legend(fontsize="x-large")
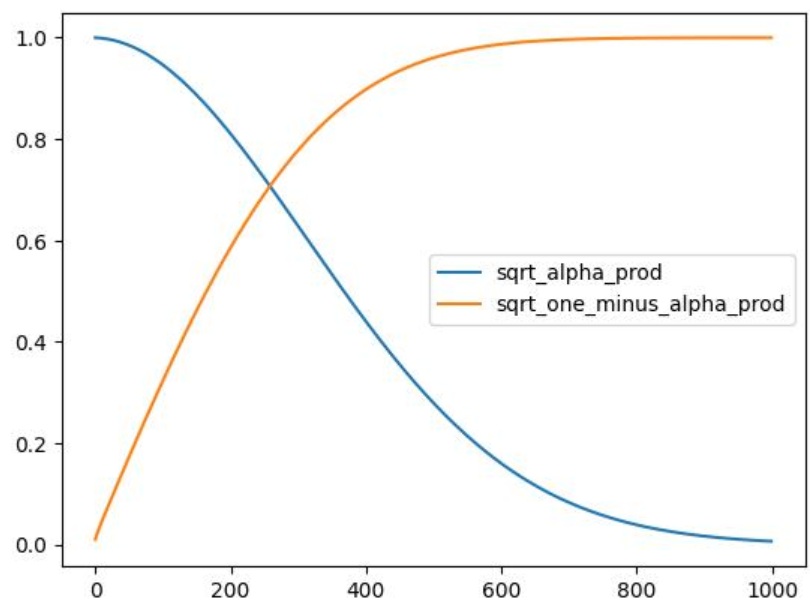
Au départ, le $x$ bruité est principalement $x$ (sqrt_alpha_prod ~= 1), mais au fil du temps, la contribution de $x$ diminue et la composante bruit augmente. Contrairement à notre mélange linéaire de $x$ et de bruit en fonction de la quantité, celui-ci devient bruyant relativement rapidement. Nous pouvons visualiser cela sur quelques données :
# Bruit d'un batch d'images pour visualiser l'effet
fig, axs = plt.subplots(3, 1, figsize=(16, 10))
xb, yb = next(iter(train_dataloader))
xb = xb.to(device)[:8]
xb = xb * 2. - 1. # Pour aller dans (-1, 1)
print('X shape', xb.shape)
# Afficher les entrées propres
axs[0].imshow(torchvision.utils.make_grid(xb[:8])[0].detach().cpu(), cmap='Greys')
axs[0].set_title('Clean X')
# Ajouter du bruit avec le planificateur
timesteps = torch.linspace(0, 999, 8).long().to(device)
noise = torch.randn_like(xb) # << NB: randn et non rand
noisy_xb = noise_scheduler.add_noise(xb, noise, timesteps)
print('Noisy X shape', noisy_xb.shape)
# Afficher la version bruyante (avec et sans coupure)
axs[1].imshow(torchvision.utils.make_grid(noisy_xb[:8])[0].detach().cpu().clip(-1, 1), cmap='Greys')
axs[1].set_title('Noisy X (clipped to (-1, 1)')
axs[2].imshow(torchvision.utils.make_grid(noisy_xb[:8])[0].detach().cpu(), cmap='Greys')
axs[2].set_title('Noisy X')
X shape torch.Size([8, 1, 28, 28])
Noisy X shape torch.Size([8, 1, 28, 28])

Une autre dynamique est en jeu : la version DDPM ajoute un bruit tiré d’une distribution gaussienne (moyenne 0, écart-type 1 de torch.randn) plutôt que le bruit uniforme entre 0 et 1 (de torch.rand) que nous avons utilisé dans notre fonction corrompue d’origine. En général, il est judicieux de normaliser également les données d’entraînement. Dans l’autre notebook, vous verrez Normalize(0.5, 0.5) dans la liste des transformations, qui fait correspondre les données de l’image de (0, 1) à (-1, 1) et qui est “suffisante” pour nos besoins. Nous ne l’avons pas fait pour ce notebook, mais la cellule de visualisation ci-dessus l’ajoute pour une mise à l’échelle et une visualisation plus précises.
Objectif d’entraînement
Dans notre exemple, le modèle tente de prédire l’image débruitée. Dans le DDPM et dans de nombreuses autres implémentations de modèles de diffusion, le modèle prédit le bruit utilisé dans le processus de corruption (avant la mise à l’échelle, donc un bruit à variance unitaire). Dans le code, cela ressemble à quelque chose comme :
noise = torch.randn_like(xb) # << NB: randn et non rand
noisy_x = noise_scheduler.add_noise(x, noise, timesteps)
model_prediction = model(noisy_x, timesteps).sample
loss = mse_loss(model_prediction, noise) # le bruit comme cible
Vous pouvez penser que prédire le bruit (à partir duquel nous pouvons déduire à quoi ressemble l’image débruitée) est équivalent à prédire directement l’image débruitée. Alors pourquoi privilégier l’une plutôt que l’autre : est-ce simplement pour des raisons de commodité mathématique ?
Il s’avère qu’il existe une autre subtilité. Nous calculons la perte à différents moments (choisis au hasard) au cours de l’entraînement. Ces différents objectifs conduiront à une “pondération implicite” différente de ces pertes, où la prédiction du bruit donne plus de poids aux niveaux de bruit plus faibles. Vous pouvez choisir des objectifs plus complexes pour modifier cette “pondération implicite des pertes”. Vous pouvez aussi choisir un calendrier de bruit qui donnera plus d’exemples à un niveau de bruit plus élevé. Vous pouvez demander au modèle de prédire une “vitesse” v, que nous définissons comme une combinaison de l’image et du bruit dépendant du niveau de bruit (voir Progressive Distillation for Fast Sampling of Diffusion Models). Il se peut que le modèle prédise le bruit, mais qu’il réduise ensuite la perte en fonction d’un facteur dépendant de la quantité de bruit, sur la base d’un peu de théorie (voir Perception Prioritized Training of Diffusion Models) ou d’expériences visant à déterminer quels niveaux de bruit sont les plus informatifs pour le modèle (voir Elucidating the Design Space of Diffusion-Based Generative Models). En résumé : le choix de l’objectif a un effet sur les performances du modèle, et des recherches sont en cours pour déterminer la “meilleure” option.
Pour l’instant, la prédiction du bruit (epsilon ou eps) est l’approche privilégiée, mais avec le temps, nous verrons probablement d’autres objectifs pris en charge dans la bibliothèque et utilisés dans différentes situations.
Conditionnement du pas de temps
Le modèle UNet2DModel prend en compte à la fois x et le pas de temps. Ce dernier est transformé en intégration et introduit dans le modèle à plusieurs endroits.
La théorie sous-jacente est qu’en donnant au modèle des informations sur le niveau de bruit, il peut mieux accomplir sa tâche. Bien qu’il soit possible d’entraîner un modèle sans ce conditionnement du pas de temps, cela semble améliorer les performances dans certains cas et la plupart des implémentations l’incluent, du moins dans la littérature actuelle.
Échantillonnage
Étant donné un modèle qui estime le bruit présent dans une entrée bruyante (ou qui prédit la version débruitée), comment produire de nouvelles images ?
Nous pourrions introduire du bruit pur et espérer que le modèle prédise une bonne image en tant que version débruitée en une seule étape. Cependant, comme nous l’avons vu dans les expériences ci-dessus, cela ne fonctionne généralement pas bien. C’est pourquoi nous procédons à un certain nombre de petites étapes basées sur la prédiction du modèle, en éliminant de manière itérative une petite partie du bruit à la fois.
La manière exacte de procéder dépend de la méthode d’échantillonnage utilisée. Nous n’entrerons pas dans la théorie trop profondément, mais les questions clés de la conception sont les suivantes :
- Quelle est l’ampleur du pas à franchir ? En d’autres termes, quel « calendrier de bruit » devez-vous suivre ?
- Utilisez-vous uniquement la prédiction actuelle du modèle pour informer l’étape de mise à jour (comme DDPM, DDIM et beaucoup d’autres) ? Évaluez-vous le modèle plusieurs fois pour estimer les gradients d’ordre supérieur en vue d’une étape plus importante et plus précise (méthodes d’ordre supérieur et certains solveurs d’EDO discrètes) ? Ou bien conservez-vous un historique des prédictions passées pour essayer de mieux informer l’étape de mise à jour actuelle (échantillonneurs linéaires multi-étapes et ancestraux) ?
- Ajoutez-vous du bruit supplémentaire (parfois appelé « churn ») pour ajouter plus de stochasticité (caractère aléatoire) au processus d’échantillonnage, ou le gardez-vous complètement déterministe ? De nombreux échantillonneurs contrôlent ce paramètre (tel que « eta » pour les échantillonneurs DDIM) afin que l’utilisateur puisse choisir.
La recherche sur les méthodes d’échantillonnage pour les modèles de diffusion évolue rapidement et de plus en plus de méthodes permettant de trouver de bonnes solutions en moins d’étapes sont proposées. Les courageux et les curieux trouveront peut-être intéressant de parcourir le code des différentes implémentations disponibles dans la bibliothèque 🤗 Diffusers ici ou de consulter la documentation qui renvoient souvent aux articles pertinents.
Conclusions
Nous espérons que ce notebook vous a permis d’aborder les modèles de diffusion sous un angle légèrement différent.
Ce notebook a été écrit pour le cours de Hugging Face par Jonathan Whitaker, et recoupe une version incluse dans son propre cours, The Generative Landscape. Consultez-le (en anglais) si vous souhaitez voir cet exemple de base étendu avec du bruit et du conditionnement de classe. Les questions ou les bugs peuvent être communiqués via Discord. Vous pouvez également envoyer un message via Twitter à @johnowhitaker.