Modèle de diffusion conditionné par la classe
Dans ce notebook, nous allons illustrer une façon d’ajouter des informations de conditionnement à un modèle de diffusion. Plus précisément, nous allons entraîner un modèle de diffusion conditionné par la classe sur MNIST à la suite de l’exemple d’entraînement à partir de 0 de l’unité 1, où nous pouvons spécifier quel chiffre nous voulons que le modèle génère au moment de l’inférence.
Comme indiqué dans l’introduction de cette unité, il s’agit d’une des nombreuses façons d’ajouter des informations de conditionnement supplémentaires à un modèle de diffusion, et elle a été choisie pour sa relative simplicité. Tout comme le notebook de l’unité 1, ce notebook n’a qu’un but illustratif et vous pouvez l’ignorer si vous le souhaitez.
Configuration et préparation des données
!pip install -q diffusers
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
from tqdm.auto import tqdm
device = 'mps' if torch.backends.mps.is_available() else 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'Using device: {device}')
# Charger le jeu de données
dataset = torchvision.datasets.MNIST(root="mnist/", train=True, download=True, transform=torchvision.transforms.ToTensor())
# Introduire les données dans un chargeur de données (batch de taille 8 ici pour la démonstration)
train_dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# Visualiser quelques exemples
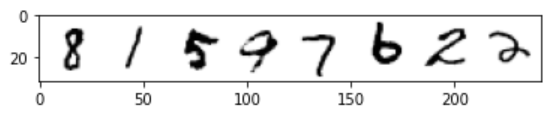
x, y = next(iter(train_dataloader))
print('Input shape:', x.shape)
print('Labels:', y)
plt.imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
Input shape: torch.Size([8, 1, 28, 28])
Labels: tensor([8, 1, 5, 9, 7, 6, 2, 2])
Création d’une UNet conditionnée par la classe
La façon dont nous introduirons le conditionnement de la classe est la suivante :
- Créer un
UNet2DModelstandard avec quelques canaux d’entrée supplémentaires. - Associer l’étiquette de la classe à un vecteur appris de forme (
class_emb_size) via une couche d’enchâssement. - Concaténer ces informations en tant que canaux supplémentaires pour l’entrée interne du UNet avec
net_input = torch.cat((x, class_cond), 1) - Introduire ce
net_input(qui a (class_emb_size+1) canaux au total) dans l’UNet pour obtenir la prédiction finale.
Dans cet exemple, nous avons fixé la taille de class_emb_size à 4, mais c’est complètement arbitraire et vous pourriez envisager de la fixer à 1 (pour voir si cela fonctionne toujours), à 10 (pour correspondre au nombre de classes), ou de remplacer le nn.Embedding appris par un simple encodage à un coup de l’étiquette de la classe directement.
Voici à quoi ressemble l’implémentation :
class ClassConditionedUNet(nn.Module):
def __init__(self, num_classes=10, class_emb_size=4):
super().__init__()
# La couche d'intégration associe l'étiquette de la classe à un vecteur de taille `class_emb_size`
self.class_emb = nn.Embedding(num_classes, class_emb_size)
# Self.model est un UNet inconditionnel avec des canaux d'entrée supplémentaires pour accepter les informations de conditionnement (l'enchâssement de la classe).
self.model = UNet2DModel(
sample_size=28, # la résolution de l'image cible
in_channels=1 + class_emb_size, # Canaux d'entrée supplémentaires pour la classe conditionnée
out_channels=1, # le nombre de canaux de sortie
layers_per_block=2, # le nombre de couches ResNet à utiliser par bloc UNet
block_out_channels=(32, 64, 64),
down_block_types=(
"DownBlock2D", # un bloc de sous-échantillonnage ResNet standard
"AttnDownBlock2D", # un bloc de sous-échantillonnage ResNet avec auto-attention spatiale
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # un bloc de suréchantillonnage ResNet avec auto-attention spatiale
"UpBlock2D", # un bloc de suréchantillonnage ResNet standard
),
)
# Notre méthode de transfert prend maintenant les étiquettes de la classe comme argument supplémentaire
def forward(self, x, t, class_labels):
# Forme de x :
bs, ch, w, h = x.shape
# conditionnement de la classe en bon état pour l'ajouter comme canaux d'entrée supplémentaires
class_cond = self.class_emb(class_labels) # Map to embedding dinemsion
class_cond = class_cond.view(bs, class_cond.shape[1], 1, 1).expand(bs, class_cond.shape[1], w, h)
# x est de forme (bs, 1, 28, 28) et class_cond est maintenant (bs, 4, 28, 28)
# L'entrée nette est maintenant x et la classe cond concaténée ensemble le long de la dimension 1
net_input = torch.cat((x, class_cond), 1) # (bs, 5, 28, 28)
# Cette information est transmise à l'UNet en même temps que le pas de temps et renvoie la prédiction
return self.model(net_input, t).sample # (bs, 1, 28, 28)
Si l’une des formes ou des transformations vous semble confuse, ajoutez des print() pour afficher les formes pertinentes et vérifiez qu’elles correspondent à vos attentes. Nous avons également annoté les formes de certaines variables intermédiaires dans l’espoir de rendre les choses plus claires.
Entraînement et échantillonnage
Alors qu’auparavant nous faisions quelque chose comme prediction = UNet(x, t), nous allons maintenant ajouter les bonnes étiquettes comme troisième argument (prediction = UNet(x, t, y)) pendant l’entraînement, et lors de l’inférence nous pouvons passer les étiquettes que nous voulons et si tout va bien le modèle devrait générer des images qui correspondent. $y$ dans ce cas est l’étiquette des chiffres MNIST, avec des valeurs de 0 à 9.
La boucle d’entraînement est très similaire à l’exemple de l’unité 1. Nous prédisons maintenant le bruit (plutôt que l’image débruitée comme dans l’unité 1) pour correspondre à l’objectif attendu par le DDPMScheduler par défaut que nous utilisons pour ajouter du bruit pendant l’entraînement et pour générer des échantillons au moment de l’inférence. L’entraînement prend du temps. L’accélérer pourrait être un mini-projet amusant, mais la plupart d’entre vous peuvent probablement parcourir le code (et en fait tout ce notebook) sans l’exécuter puisque nous ne faisons qu’illustrer une idée.
# Créer un planificateur
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule='squaredcos_cap_v2')
# Redéfinition du chargeur de données pour fixer la taille du batch à un niveau supérieur à la démonstration de 8
train_dataloader = DataLoader(dataset, batch_size=128, shuffle=True)
# Combien de fois devrions-nous passer les données en revue ?
n_epochs = 10
# Notre réseau
net = ClassConditionedUNet().to(device)
# Notre fonction de perte
loss_fn = nn.MSELoss()
# L'optimiseur
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# Conserver une trace des pertes pour les consulter ultérieurement
losses = []
# La boucle d'entraînement
for epoch in range(n_epochs):
for x, y in tqdm(train_dataloader):
# Obtenir des données et préparer la version corrompue
x = x.to(device) * 2 - 1 # Données sur le GPU (sur (-1, 1))
y = y.to(device)
noise = torch.randn_like(x)
timesteps = torch.randint(0, 999, (x.shape[0],)).long().to(device)
noisy_x = noise_scheduler.add_noise(x, noise, timesteps)
# Obtenir la prédiction du modèle
pred = net(noisy_x, timesteps, y) # Notez que nous passons les étiquettes y
# Calculer la perte
loss = loss_fn(pred, noise) # Quelle est la distance entre la sortie et le bruit ?
# Rétropopagation et mise à jour des paramètres :
opt.zero_grad()
loss.backward()
opt.step()
# Stocker la perte pour plus tard
losses.append(loss.item())
# Afficher la moyenne des 100 dernières valeurs de perte pour vous faire une idée de la progression :
avg_loss = sum(losses[-100:])/100
print(f'Finished epoch {epoch}. Average of the last 100 loss values: {avg_loss:05f}')
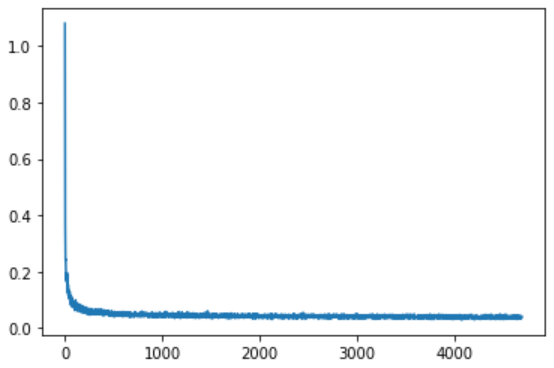
# Visualiser la courbe des pertes
plt.plot(losses)
Une fois l’entraînement terminé, nous pouvons échantillonner quelques images en introduisant différentes étiquettes comme conditionnement :
# Préparer un x aléatoire comme point de départ, ainsi que les étiquettes souhaitées y
x = torch.randn(80, 1, 28, 28).to(device)
y = torch.tensor([[i]*8 for i in range(10)]).flatten().to(device)
# Boucle d'échantillonnage
for i, t in tqdm(enumerate(noise_scheduler.timesteps)):
# Obtenir la prédiction du modèle
with torch.no_grad():
residual = net(x, t, y) # Notez à nouveau que nous transmettons nos étiquettes y
# Mise à jour de l'échantillon avec l'étape
x = noise_scheduler.step(residual, t, x).prev_sample
# Montrer les résultats
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ax.imshow(torchvision.utils.make_grid(x.detach().cpu().clip(-1, 1), nrow=8)[0], cmap='Greys')
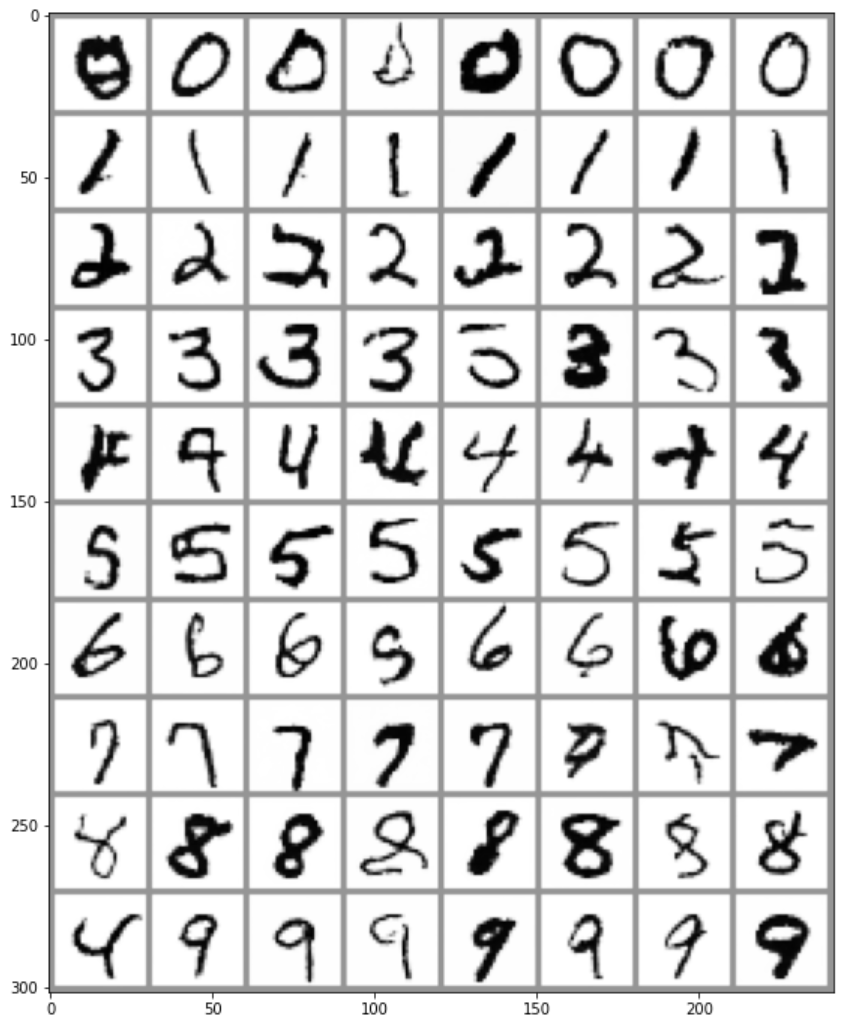
Nous y voilà ! Nous pouvons maintenant contrôler les images produites.
Nous espérons que cet exemple vous a plu. Comme toujours, n’hésitez pas à poser des questions sur Discord.
✏️ À votre tour !
Essayez de refaire la même chose avec FashionMNIST. Modifiez le taux d’apprentissage, la taille du batch et le nombre d’époques.Pouvez-vous obtenir des images de mode décentes avec moins de temps d’entraînement que dans l’exemple ci-dessus ?