Débruitage inverse des modèles de diffusion implicites (DDIM)
Dans ce notebook, nous allons explorer l’inversion, voir comment elle est liée à l’échantillonnage, et l’appliquer à la tâche d’édition d’images avec Stable Diffusion. Ce que vous allez apprendre :
- Comment fonctionne l’échantillonnage DDIM
- Échantillonneurs déterministes et stochastiques
- La théorie derrière l’inversion DDIM
- L’édition d’images avec l’inversion
Commençons !
Configuration
# !pip install -q transformers diffusers accelerate
import torch
import requests
import torch.nn as nn
import torch.nn.functional as F
from PIL import Image
from io import BytesIO
from tqdm.auto import tqdm
from matplotlib import pyplot as plt
from torchvision import transforms as tfms
from diffusers import StableDiffusionPipeline, DDIMScheduler
# Une fonction utile pour plus tard
def load_image(url, size=None):
response = requests.get(url,timeout=0.2)
img = Image.open(BytesIO(response.content)).convert('RGB')
if size is not None:
img = img.resize(size)
return img
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Chargement d’un pipeline existant
# Charger un pipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5").to(device)
# Mettre en place un planificateur DDIM
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
# Échantillon d'une image pour s'assurer que tout fonctionne bien
prompt = 'Beautiful DSLR Photograph of a penguin on the beach, golden hour'
negative_prompt = 'blurry, ugly, stock photo'
im = pipe(prompt, negative_prompt=negative_prompt).images[0]
im.resize((256, 256)) # redimensionner pour une meilleure visualisation

Echantillonage DDIM
À un moment donné $t$, l’image bruitée $x_t$ est un mélange de l’image originale ($x_0$) et de bruit ($\epsilon$). Voici la formule pour $x_t$ tirée de l’article DDIM, à laquelle nous nous référerons dans cette section :
\[x_t = \sqrt{\alpha_t}x_0 + \sqrt{1-\alpha_t}\epsilon\]$\epsilon$ est un bruit gaussien de variance unitaire
$\alpha_t$ (“alpha”) est la valeur qui est appelée de manière confuse $\bar{\alpha}$ (“alpha_bar”) dans le papier DDPM ( !!) et qui définit le planificateur de bruit. Dans 🤗 Diffusers, le planificateur alpha est calculé et les valeurs sont stockées dans le scheduler.alphas_cumprod. Je sais que c’est déroutant ! Traçons ces valeurs, et n’oubliez pas que pour le reste de ce notebook, nous utiliserons la notation de DDIM.
# Tracer 'alpha' (alpha_bar dans DDPM, alphas_cumprod dans Diffusers)
timesteps = pipe.scheduler.timesteps.cpu()
alphas = pipe.scheduler.alphas_cumprod[timesteps]
plt.plot(timesteps, alphas, label='alpha_t');
plt.legend()
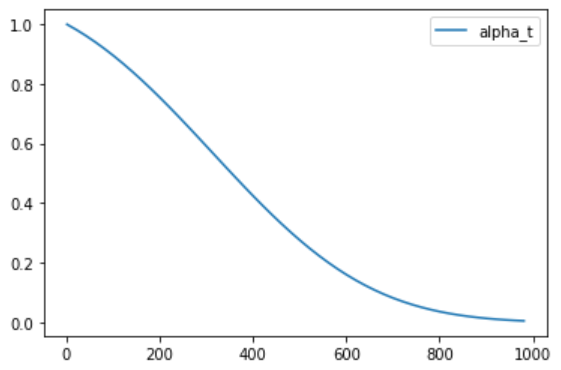
Au départ (étape 0, côté gauche du graphique), nous commençons avec une image propre et sans bruit. $\alpha_t = 1$. Au fur et à mesure que nous passons à des pas de temps plus élevés, nous nous retrouvons avec presque tout le bruit et $\alpha_t$ chute vers 0.
Lors de l’échantillonnage, nous commençons avec du bruit pur au pas de temps $1000$ et nous nous rapprochons lentement du pas de temps $0$. Pour calculer le prochain $t$ de la trajectoire d’échantillonnage ($x_{t-1}$ puisque nous passons d’un $t$ élevé à un $t$ faible), nous prédisons le bruit ($\epsilon_\theta(x_t)$, qui est la sortie de notre modèle) et nous l’utilisons pour calculer l’image débruitée prédite $x_0$. Nous utilisons ensuite cette prédiction pour nous déplacer sur une petite distance dans la « direction pointant vers $x_t$ ». Enfin, nous pouvons ajouter du bruit supplémentaire à l’échelle de $\sigma_t$. Voici la section de l’article qui montre cette méthode en action :

Nous disposons donc d’une équation permettant de passer de $x_t$ à $x_{t-1}$, avec une quantité de bruit contrôlable. Dans notre cas présent, nous nous intéressons plus particulièrement au cas où nous n’ajoutons aucun bruit supplémentaire, ce qui nous donne un échantillonnage DDIM entièrement déterministe. Voyons ce que cela donne en code :
# Fonction d'échantillonnage (DDIM standard)
@torch.no_grad()
def sample(prompt, start_step=0, start_latents=None,
guidance_scale=3.5, num_inference_steps=30,
num_images_per_prompt=1, do_classifier_free_guidance=True,
negative_prompt='', device=device):
# Encoder le prompt
text_embeddings = pipe._encode_prompt(
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
)
# Nombre d'étapes d'inférence
pipe.scheduler.set_timesteps(num_inference_steps, device=device)
# Créer un point de départ aléatoire si nous n'en avons pas déjà un
if start_latents is None:
start_latents = torch.randn(1, 4, 64, 64, device=device)
start_latents *= pipe.scheduler.init_noise_sigma
latents = start_latents.clone()
for i in tqdm(range(start_step, num_inference_steps)):
t = pipe.scheduler.timesteps[i]
# développer les latents si l'on procède à un guidage sans classifieur
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = pipe.scheduler.scale_model_input(latent_model_input, t)
# prédire le bruit résiduel
noise_pred = pipe.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
#réaliser un guidage
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# Normalement, nous devrions nous fier au planificateur pour gérer l'étape de mise à jour :
# latents = pipe.scheduler.step(noise_pred, t, latents).prev_sample
# Au lieu de cela, faisons-le nous-mêmes :
prev_t = max(1, t.item() - (1000//num_inference_steps)) # t-1
alpha_t = pipe.scheduler.alphas_cumprod[t.item()]
alpha_t_prev = pipe.scheduler.alphas_cumprod[prev_t]
predicted_x0 = (latents - (1-alpha_t).sqrt()*noise_pred) / alpha_t.sqrt()
direction_pointing_to_xt = (1-alpha_t_prev).sqrt()*noise_pred
latents = alpha_t_prev.sqrt()*predicted_x0 + direction_pointing_to_xt
# Post-traitement
images = pipe.decode_latents(latents)
images = pipe.numpy_to_pil(images)
return images
# Tester notre fonction d'échantillonnage en générant une image
sample('Watercolor painting of a beach sunset', negative_prompt=negative_prompt, num_inference_steps=50)[0].resize((256, 256))

Voyez si vous pouvez faire correspondre le code avec l’équation de l’article. Notez que $\sigma$=0 puisque nous ne nous intéressons qu’au cas où il n’y a pas de bruit supplémentaire, nous pouvons donc laisser de côté ces éléments de l’équation.
Inversion
L’objectif est d’inverser le processus d’échantillonnage. Nous voulons obtenir un latent bruité qui, s’il est utilisé comme point de départ de notre procédure d’échantillonnage habituelle, permet de générer l’image originale.
Ici, nous chargeons une image comme image initiale, mais vous pouvez également en générer une vous-même pour l’utiliser à la place.
# https://www.pexels.com/photo/a-beagle-on-green-grass-field-8306128/
input_image = load_image('https://images.pexels.com/photos/8306128/pexels-photo-8306128.jpeg', size=(512, 512))
input_image

Nous allons également utiliser un prompt pour effectuer l’inversion avec l’aide d’un classifieur libre, alors entrez une description de l’image :
input_image_prompt = "Photograph of a puppy on the grass"
Ensuite, nous devons transformer cette image PIL en un ensemble de latents que nous utiliserons comme point de départ de notre inversion :
# encoder avec le VAE
with torch.no_grad(): latent = pipe.vae.encode(tfms.functional.to_tensor(input_image).unsqueeze(0).to(device)*2-1)
l = 0.18215 * latent.latent_dist.sample()
Très bien, il est temps de passer à la partie amusante. Cette fonction ressemble à la fonction d’échantillonnage ci-dessus, mais nous nous déplaçons à travers les pas de temps dans la direction opposée, en commençant à $t=0$ et en nous déplaçant vers un bruit de plus en plus élevé. Et au lieu de mettre à jour nos latents pour qu’ils soient moins bruyants, nous estimons le bruit prédit et l’utilisons pour ANNULER une étape de mise à jour, en les déplaçant de $t$ à $t+1$.
## Inversion
@torch.no_grad()
def invert(start_latents, prompt, guidance_scale=3.5, num_inference_steps=80,
num_images_per_prompt=1, do_classifier_free_guidance=True,
negative_prompt='', device=device):
# Encoder le prompt
text_embeddings = pipe._encode_prompt(
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
)
# les latents sont maintenant les latents de départ spécifiés
latents = start_latents.clone()
# Nous garderons une liste des latents inversés au fur et à mesure du processus
intermediate_latents = []
# Définir le nombre d'étapes de l'inférence
pipe.scheduler.set_timesteps(num_inference_steps, device=device)
# Pas de temps inversés <<<<<<<<<<<<<<<<<<<<
timesteps = reversed(pipe.scheduler.timesteps)
for i in tqdm(range(1, num_inference_steps), total=num_inference_steps-1):
# Nous allons sauter l'itération finale
if i >= num_inference_steps - 1: continue
t = timesteps[i]
# développer les latents si l'on fait de l'orientation sans classifieur
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = pipe.scheduler.scale_model_input(latent_model_input, t)
# prédire le bruit résiduel
noise_pred = pipe.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# effectuer un guidage
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
current_t = max(0, t.item() - (1000//num_inference_steps))#t
next_t = t # min(999, t.item() + (1000//num_inference_steps)) # t+1
alpha_t = pipe.scheduler.alphas_cumprod[current_t]
alpha_t_next = pipe.scheduler.alphas_cumprod[next_t]
# Étape de mise à jour inversée (réorganisation de l'étape de mise à jour pour obtenir x(t) (nouveaux latents) en fonction de x(t-1) (latents actuels)
latents = (latents - (1-alpha_t).sqrt()*noise_pred)*(alpha_t_next.sqrt()/alpha_t.sqrt()) + (1-alpha_t_next).sqrt()*noise_pred
# Stockage
intermediate_latents.append(latents)
return torch.cat(intermediate_latents)
En l’exécutant sur la représentation latente de notre photo de chiot, nous obtenons un ensemble de tous les latents intermédiaires créés au cours du processus d’inversion :
inverted_latents = invert(l, input_image_prompt,num_inference_steps=50)
inverted_latents.shape
torch.Size([48, 4, 64, 64])
Nous pouvons visualiser l’ensemble final de latents - ceux-ci constitueront, nous l’espérons, le point de départ bruyant de nos nouvelles tentatives d’échantillonnage :
# Décoder les latents inversés finaux
with torch.no_grad():
im = pipe.decode_latents(inverted_latents[-1].unsqueeze(0))
pipe.numpy_to_pil(im)[0]

Vous pouvez transmettre ces latents inversés au pipeline en utilisant la méthode__call__ normale :
pipe(input_image_prompt, latents=inverted_latents[-1][None], num_inference_steps=50, guidance_scale=3.5).images[0]

Mais c’est là que nous voyons notre premier problème : ce n’est pas tout à fait l’image avec laquelle nous avons commencé ! En effet, l’inversion DDIM repose sur une hypothèse critique selon laquelle la prédiction du bruit à l’instant $t$ et à l’instant $t+1$ sera la même, ce qui n’est pas vrai lorsque l’inversion ne porte que sur $50$ ou $100$ pas de temps. Nous pourrions utiliser davantage de pas de temps pour espérer obtenir une inversion plus précise, mais nous pouvons également tricher et commencer à partir de, disons, $20/50$ pas d’échantillonnage avec les latents intermédiaires correspondants que nous avons sauvegardés lors de l’inversion :
# La raison pour laquelle nous voulons pouvoir spécifier l'étape de démarrage
start_step=20
sample(input_image_prompt, start_latents=inverted_latents[-(start_step+1)][None],
start_step=start_step, num_inference_steps=50)[0]

Très proche de notre image d’entrée ! Pourquoi faisons-nous cela ? Eh bien, l’espoir est que si nous échantillonnons maintenant avec un nouveau prompt, nous obtiendrons une image qui correspond à l’original SAUF aux endroits pertinents pour le nouveau prompt. Par exemple, en remplaçant « puppy » par « cat », nous devrions voir un chat avec un dos et un arrière-plan presque identiques :
# Échantillonnage avec un nouveau prompt
start_step=10
new_prompt = input_image_prompt.replace('puppy', 'cat')
sample(new_prompt, start_latents=inverted_latents[-(start_step+1)][None],
start_step=start_step, num_inference_steps=50)[0]

Pourquoi ne pas utiliser img2img ?
Pourquoi s’embêter à inverser ? Ne peut-on pas simplement ajouter du bruit à l’image d’entrée et la débruiter avec le nouveau prompt ? Nous le pouvons, mais cela entraînera des changements beaucoup plus radicaux partout (si nous ajoutons beaucoup de bruit) ou des changements insuffisants partout (si nous ajoutons moins de bruit). Essayez vous-même :
start_step = 10
num_inference_steps=50
pipe.scheduler.set_timesteps(num_inference_steps)
noisy_l = pipe.scheduler.add_noise(l, torch.randn_like(l), pipe.scheduler.timesteps[start_step])
sample(new_prompt, start_latents=noisy_l, start_step=start_step, num_inference_steps=num_inference_steps)[0]

Notez la modification beaucoup plus importante de la pelouse et de l’arrière-plan.
Rassembler le tout
Rassemblons le code que nous avons écrit jusqu’à présent dans une fonction simple qui prend une image et deux prompts et effectue une modification en utilisant l’inversion :
def edit(input_image, input_image_prompt, edit_prompt, num_steps=100, start_step=30, guidance_scale=3.5):
with torch.no_grad(): latent = pipe.vae.encode(tfms.functional.to_tensor(input_image).unsqueeze(0).to(device)*2-1)
l = 0.18215 * latent.latent_dist.sample()
inverted_latents = invert(l, input_image_prompt,num_inference_steps=num_steps)
final_im = sample(edit_prompt, start_latents=inverted_latents[-(start_step+1)][None],
start_step=start_step, num_inference_steps=num_steps, guidance_scale=guidance_scale)[0]
return final_im
Et en action :
edit(input_image, 'A puppy on the grass', 'an old grey dog on the grass', num_steps=50, start_step=10)

edit(input_image, 'A puppy on the grass', 'A blue dog on the lawn', num_steps=50, start_step=12, guidance_scale=6)

✏️ À votre tour !
Essayez ceci sur d’autres images ! Explorez les différents paramètres.
Plus de pas = meilleure performance
Si vous avez des problèmes avec des inversions moins précises, vous pouvez essayer d’utiliser plus de pas (au prix d’un temps d’exécution plus long). Pour tester l’inversion, vous pouvez utiliser notre fonction d’édition avec le même prompt :
# Test d'inversion avec beaucoup plus d'étapes :
edit(input_image, 'A puppy on the grass', 'A puppy on the grass', num_steps=350, start_step=1)

C’est beaucoup mieux ! Et en essayant de l’éditer :
edit(input_image, 'A photograph of a puppy', 'A photograph of a grey cat', num_steps=150, start_step=30, guidance_scale=5.5)

# source: https://www.pexels.com/photo/girl-taking-photo-1493111/
face = load_image('https://images.pexels.com/photos/1493111/pexels-photo-1493111.jpeg', size=(512, 512))
face

edit(face, 'A photograph of a face', 'A photograph of a face with sunglasses', num_steps=250, start_step=30, guidance_scale=3.5)

edit(face, 'A photograph of a face', 'Acrylic palette knife painting of a face, colorful', num_steps=250, start_step=65, guidance_scale=5.5)

Et ensuite ?
Armé des connaissances de ce notebook, nous vous recommandons d’étudier Null-text Inversion qui s’appuie sur DDIM en optimisant le texte nul (prompt inconditionnel) lors de l’inversion pour des inversions plus précises et de meilleures éditions.