Avant-propos
Cet article est une traduction de l’article de Jay Alammar : The illustrated word2vec. Ainsi si dans l’article vous lisez des « Je » ou des « Jay », cela provient d’exemple de l’article original que je n’ai pas pu traduire autrement. Merci à lui de m’avoir autorisé à effectuer cette traduction.
1. Exemple d’introduction
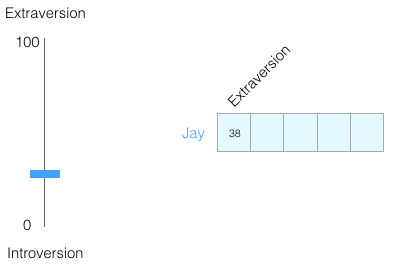
Sur une échelle de 0 à 100, dans quelle mesure êtes-vous introverti/extraverti (où 0 est le plus introverti et 100 le plus extraverti) ? Avez-vous déjà passé un test de personnalité comme le test des cinq grands traits de personnalité ? Si vous ne l’avez pas fait, ce sont des tests qui vous posent une liste de questions, puis vous notent sur un certain nombre d’axes, l’introversion/extraversion étant l’un d’eux.

Imaginez avoir obtenu 38/100 comme score d’introversion/extraversion. Nous pouvons tracer cela de cette façon :
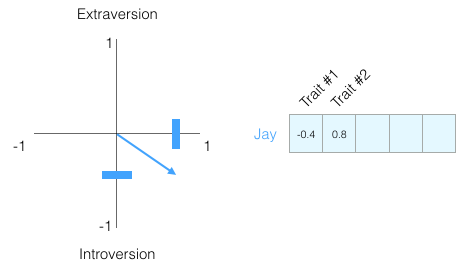
On se ramène à une échelle comprise entre -1 à 1 :

Dans quelle mesure avez-vous l’impression de connaître une personne en ne connaissant que cette seule information à son sujet ? Pas grand-chose. Les gens sont complexes. Ajoutons donc une autre dimension : le score d’un autre trait du test. Nous pouvons représenter les deux dimensions comme un point sur le graphique, ou mieux encore, comme un vecteur de l’origine à ce point.
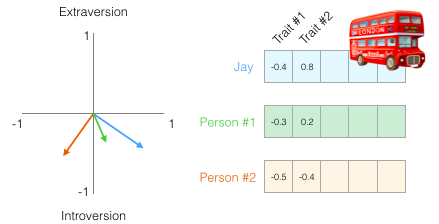
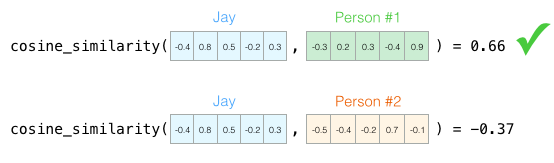
On peut maintenant dire que ce vecteur représente partiellement ma personnalité. L’utilité d’une telle représentation apparaît quand on veut comparer deux autres personnes à moi. Disons que je me fais renverser par un bus et que j’ai besoin d’être remplacé par quelqu’un avec une personnalité similaire. Dans la figure suivante, laquelle des deux personnes me ressemble le plus ?
Lorsqu’il s’agit de vecteurs, un moyen courant de calculer un score de similarité est le cosinus :

Encore une fois, deux dimensions ne suffisent pas pour saisir suffisamment d’information sur les différences entre les gens. Des décennies de recherche en psychologie ont mené à cinq traits principaux (et beaucoup de sous-traits). Utilisons donc les cinq dimensions dans notre comparaison :

Le problème avec les cinq dimensions est que nous perdons la capacité de dessiner des flèches nettes comme en deux dimensions. C’est un défi commun en apprentissage machine où nous devons souvent penser dans un espace plus vaste. Ce qui est bien, c’est que la similarité cosinus fonctionne toujours avec n’importe quel nombre de dimensions :
Deux idées centrales se dégagent de ce premier exemple :
- nous pouvons représenter les gens (et les choses) comme des vecteurs de nombres,
- nous pouvons facilement calculer à quel point les vecteurs sont similaires les uns aux autres.
2. Word Embeddings
Avec cette introduction, nous pouvons regarder des exemples d’enchâssements de mots entraînés (word embeddings en anglais, aussi connus dans la literrature en français sous le nom de plongement de mots) et commencer à examiner certaines de leurs propriétés intéressantes.
Voici un word embeddings pour le mot « king » (via GloVe qui est entraîné sur Wikipedia) :

C’est une liste de 50 numéros. Nous ne pouvons pas dire grand-chose en regardant les valeurs. Mais nous pouvons la comparer à d’autres enchâssements de mots. Mettons tous ces chiffres sur une ligne :

Colorons ensuite les cellules en fonction de leurs valeurs (rouge si elles sont proches de 2, blanc si elles sont proches de 0, bleu si elles sont proches de -2) :

Jusqu’à la fin de cette partie, continuons en ignorant les chiffres et en ne regardant que les couleurs pour indiquer les valeurs des cellules.
Comparons maintenant « king » à d’autres mots :
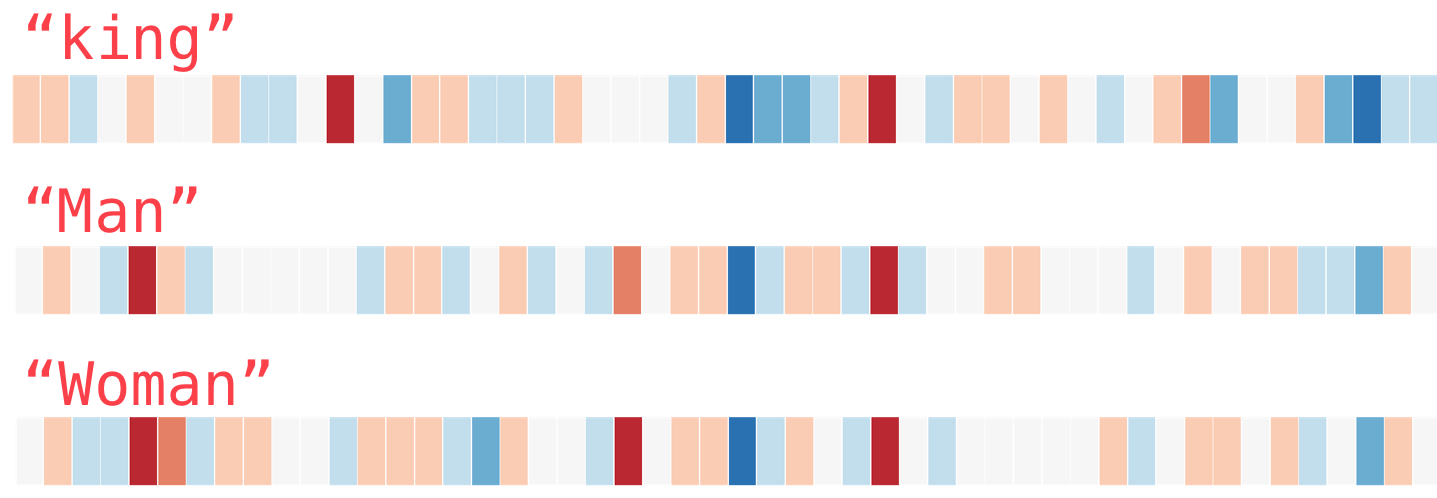
Vous voyez comme les mots « man » et « woman » sont beaucoup plus semblables l’un à l’autre qu’ils ne le sont à « king » ? Ces représentations vectorielles saisissent une bonne partie de l’information, du sens et des associations de ces mots.
Voici une autre liste d’exemples (comparez en regardant verticalement à la recherche de colonnes de couleurs similaires) :
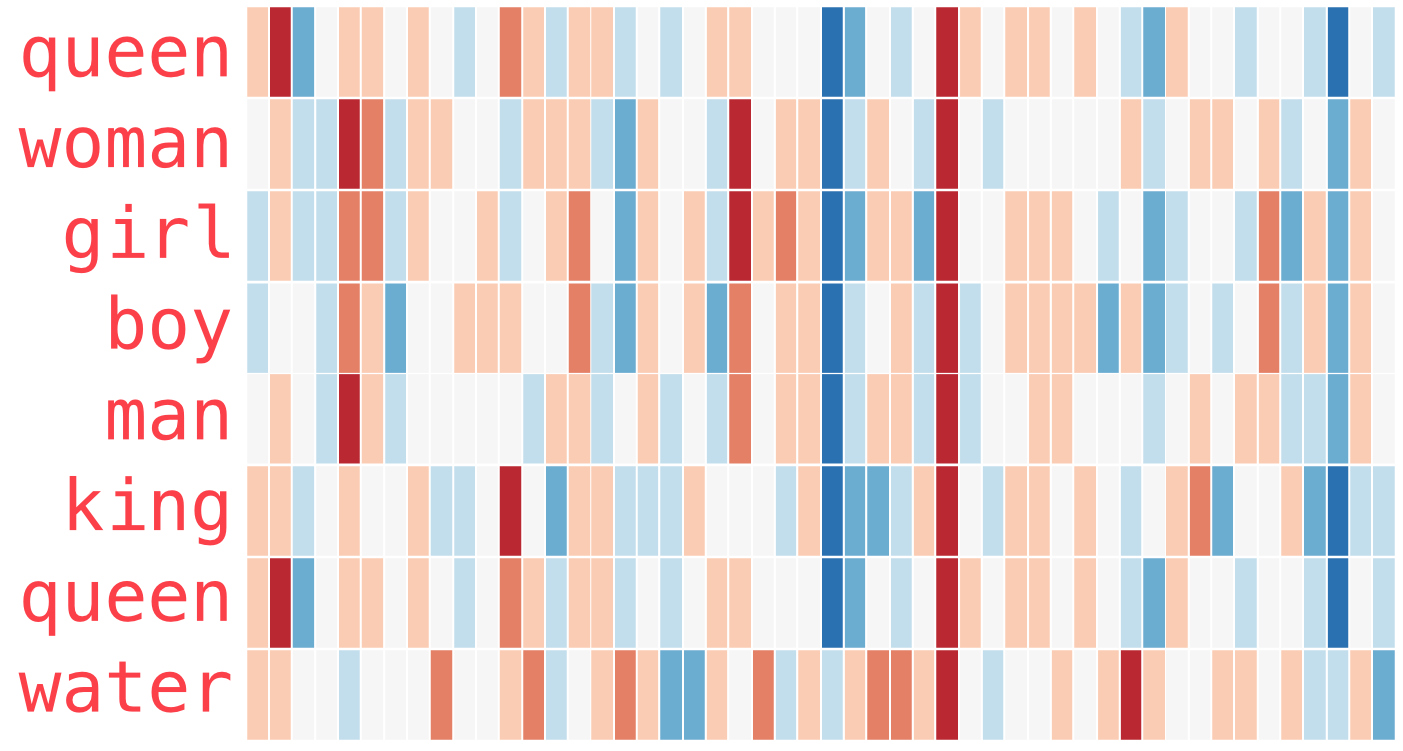
Quelques points à signaler :
- Il y a une colonne rouge traversant tous les mots. Ils sont donc similaires le long de cette dimension (mains ne savons pas à quoi chaque dimension correspond).
- Vous pouvez voir comment les mots « woman » et « girl » sont semblables l’un à l’autre dans beaucoup d’endroits. Il en va de même pour « man » et « boy ».
- « boy » et « girl » ont aussi des endroits où ils se ressemblent, mais où ils sont différents de « woman » ou « man ». Serait-ce le codage d’une vague conception de la jeunesse ?
- Tous les mots sauf le dernier sont des mots qui représentent les gens. J’ai ajouté un objet (water) pour montrer les différences entre les catégories. On peut voir, par exemple, une colonne bleue descendre jusqu’en bas et s’arrêter une fois arriver à l’enchâssement de « water ».
- Il y a des endroits clairs où « king » et « queen » sont semblables l’un à l’autre et distincts de tous les autres. Cela pourrait-il s’agir d’un vague concept de royauté ?
3. Analogies
Les exemples célèbres qui montrent une incroyable propriété des enchâssements est le concept d’analogies. Nous pouvons ajouter et soustraire des enchâssements de mots et arriver à des résultats intéressants.
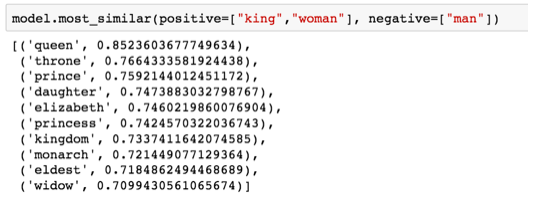
L’exemple le plus célèbre est la formule : « king » – « man » + « woman » :
4. Modélisation du langage
Maintenant que nous nous sommes penchés sur les enchâssements entrainés, nous allons en apprendre davantage sur le processus d’entraînement. Mais avant d’en arriver à Word2vec, nous devons nous pencher sur un parent conceptuel aux word embeddings : le modèle de langage.
Si l’on voulait donner un exemple d’une application de NLP, l’un des meilleurs exemples serait la fonction de prédiction du mot suivant d’un clavier de smartphone. C’est une caractéristique que des milliards de gens utilisent des centaines de fois par jour.
Cette tâche peut être traitée par un modèle linguistique. Un modèle linguistique peut prendre une liste de mots (disons deux mots) et tenter de prédire le mot qui les suit.
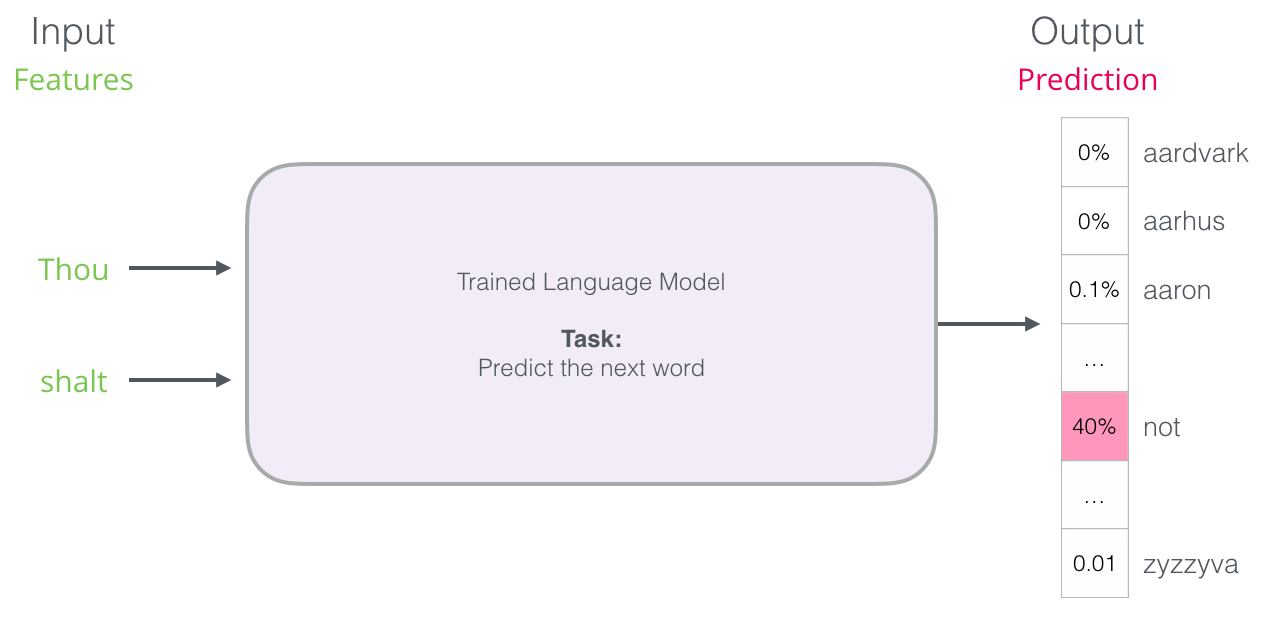
Dans la figure ci-dessus, nous pouvons penser que le modèle est celui qui a tenu compte des deux mots et qui a retourné une liste de suggestions (« not » étant celui avec la plus forte probabilité) :

On peut penser que le modèle ressemble à cette boîte noire :

Mais dans la pratique, le modèle ne produit pas un seul mot. Il produit en fait un score de probabilité pour tous les mots qu’il connaît (le vocabulaire du modèle pouvant varier de quelques milliers à plus d’un million de mots). L’application doit alors trouver les mots avec les scores les plus élevés et les présenter à l’utilisateur.
Après avoir été entraînés, les premiers modèles de langage (Bengio 2003) calculent une prédiction en trois étapes :
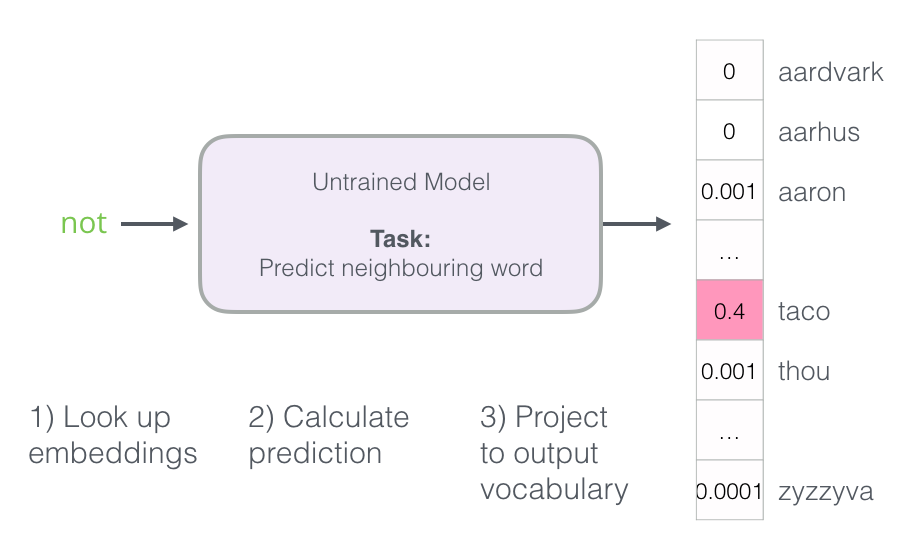
La première étape est la plus pertinente pour nous lorsque nous discutons de d’enchâssements.
L’un des résultats du processus d’entraînement est une matrice qui contient un enchâssement pour chaque mot de notre vocabulaire. Pendant lors de l’étape de prédiction, nous recherchons simplement les enchâssements du mot d’entrée et nous les utilisons pour calculer la prédiction :
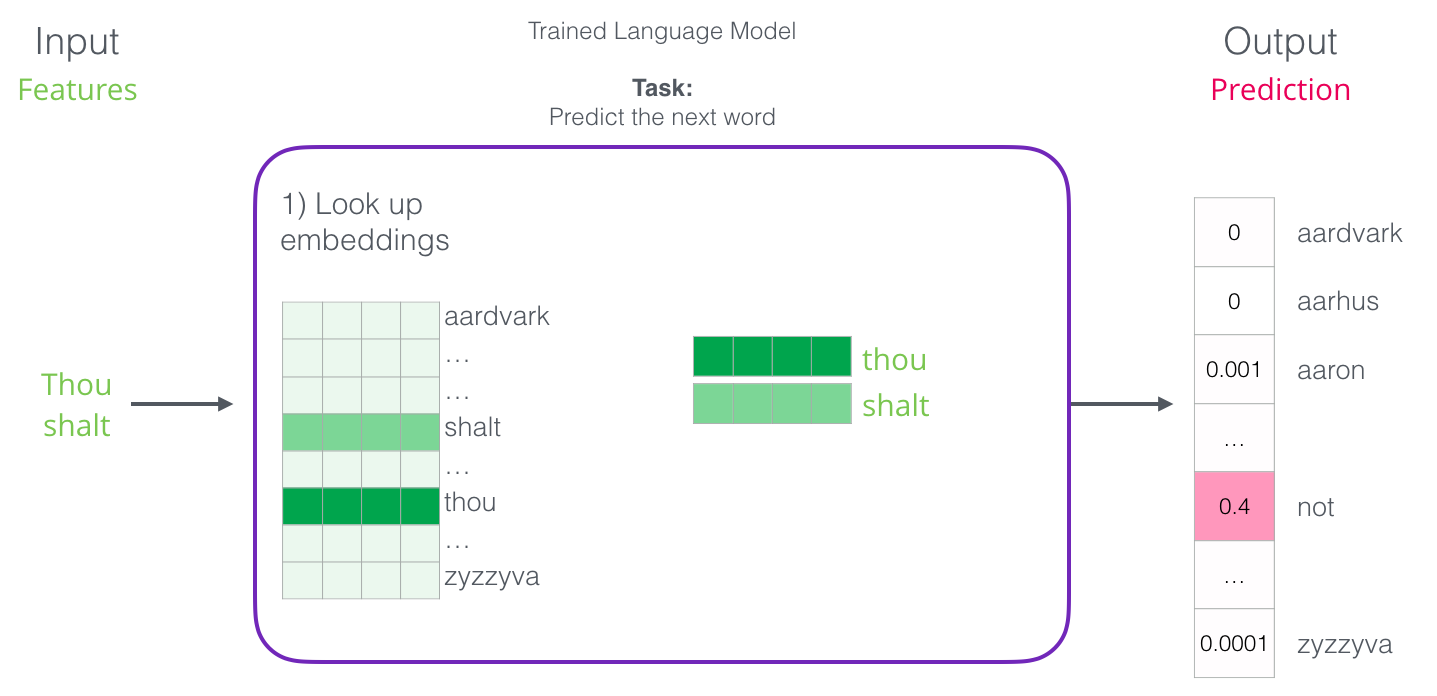
Passons à présent au processus d’entraînement pour en savoir plus sur la façon dont la matrice d’enchâssements a été créé.
5. Entraînement du modèle linguistique
Les modèles linguistiques ont un avantage énorme sur la plupart des autres modèles d’apprentissage machine. Cet avantage est que nous sommes en mesure de les entraîner sur des textes courants dont nous disposons en abondance. Pensez à tous les livres, articles, contenus Wikipédia et autres formes de données textuelles que nous avons. Comparez ceci aux autres modèles qui ont besoin d’annotations faites à la main et de données spécialement collectées.
Nous attribuons aux mots leurs enchâssements en regardant les autres mots à côté desquels ils ont tendance à apparaître. La mécanique est la suivante :
- Nous recevons beaucoup de données textuelles (tous les articles de Wikipedia par exemple).
- Nous avons une fenêtre (disons de trois mots) que nous faisons glisser sur tout ce texte.
- La fenêtre coulissante génère des exemples d’entraînement pour notre modèle.
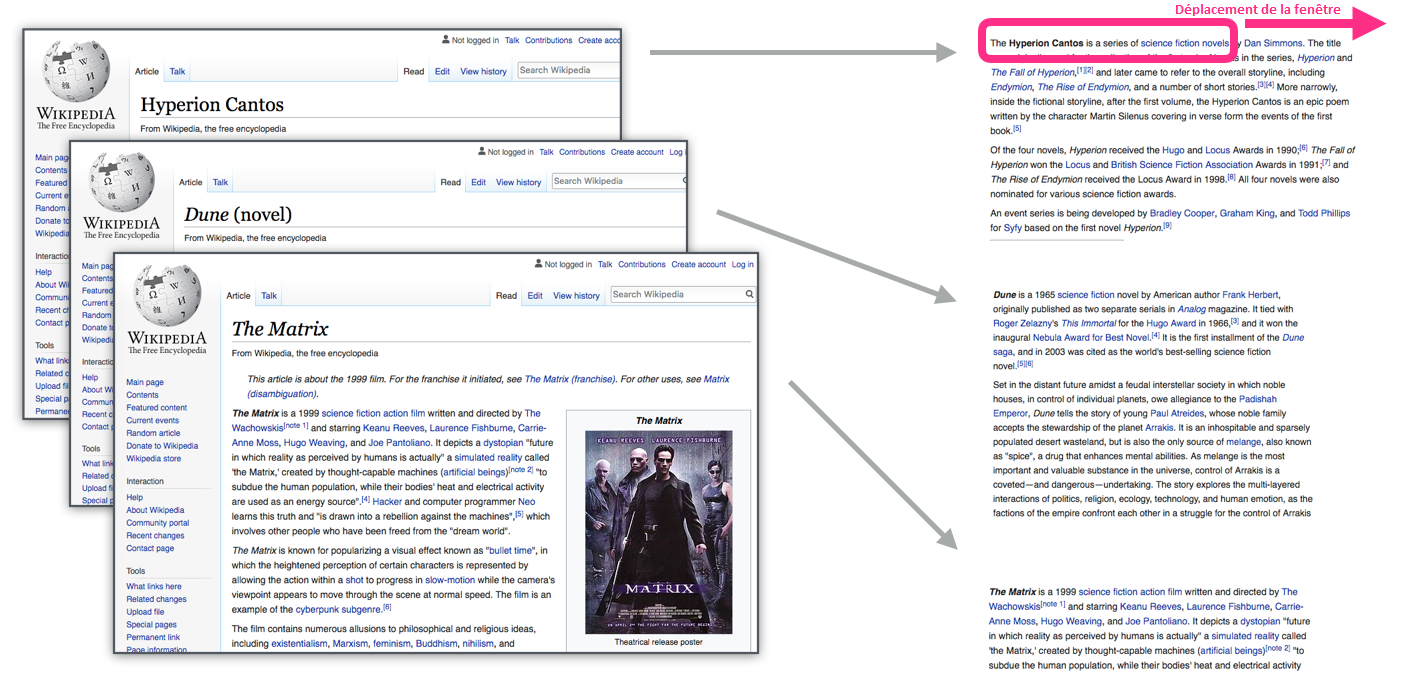
Lorsque la fenêtre glisse sur le texte, nous générons (virtuellement) un ensemble de données que nous utilisons pour entraîner un modèle. Pour voir exactement comment cela se fait, voyons comment la fenêtre coulissante traite cette phrase : « Thou shalt not make a machine in the likeness of a human mind » (Tu ne feras pas une machine à l’image d’un esprit humain).
Lorsque nous commençons, la fenêtre est sur les trois premiers mots de la phrase :

Nous prenons les deux premiers mots pour des caractéristiques et le troisième mot pour un label :

Nous glissons ensuite notre fenêtre à la position suivante et créons un deuxième échantillon :
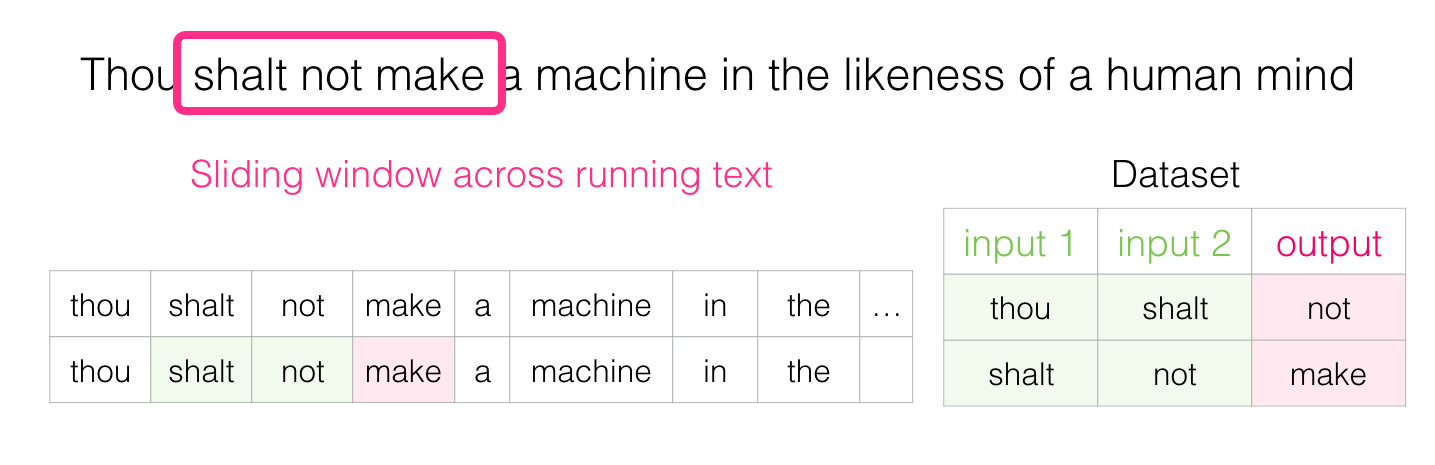
Et très rapidement, nous disposons d’un ensemble de données plus vaste dont les mots ont tendance à apparaître après différentes paires de mots :
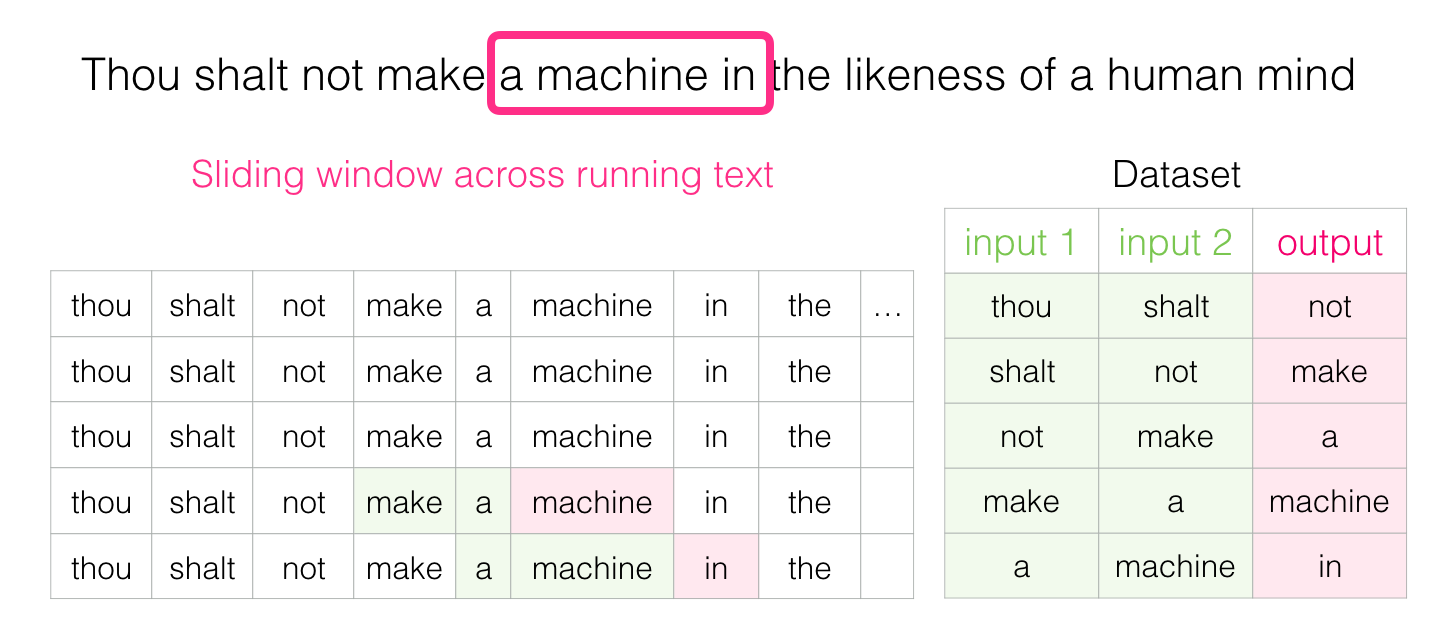
Dans la pratique, les modèles ont tendance à être entraînés pendant que nous glissons la fenêtre. Mais je trouve plus clair de séparer logiquement la phase génération du jeu de données de la phase d’entraînement. Outre les approches de modélisation du langage fondées sur les réseaux neuronaux, une technique appelée N-grams a été couramment utilisée pour entraîner des modèles de langage. Pour voir comment le passage des N-grams aux modèles neuronaux se reflète sur les produits du monde réel vous pouvez lire l’article suivant : https://blog.swiftkey.com/neural-networks-a-meaningful-leap-for-mobile-typing/ (en anglais). Cet exemple montre comment les propriétés algorithmiques des enchâssements peuvent être décrites dans un discours marketing.
6. Regarder des deux côtés
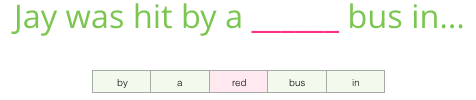
Sachant ce que vous avez lu plus tôt dans l’exemple d’introduction, remplissez le blanc :

Je suis sûr que la plupart des gens devineraient que le mot bus va dans le vide. Mais si je vous donnais une autre information, un mot après le blanc, cela changerait-il votre réponse ?

Cela change complètement ce qui devrait aller dans le blanc. Le mot « red » est maintenant le plus susceptible d’aller dans le blanc. Ce que nous apprenons de ceci est que les mots avant et après un mot spécifique ont une valeur informationnelle. Il s’avère que la prise en compte des deux sens (mots à gauche et à droite du mot que l’on devine) conduit à un meilleur enchâssement des mots.
Voyons comment nous pouvons ajuster la façon dont nous entraînons le modèle pour tenir compte de cela.
7. Skipgram
Au lieu de regarder seulement deux mots avant le mot cible, nous pouvons aussi regarder deux mots après lui.
Si nous faisons cela, l’ensemble de données que nous construisons et entrainons virtuellement ressemblerait à ceci :

C’est ce qu’on appelle une architecture de continuous bag*of-words.
Une autre architecture qui a aussi tendance à donner de bons résultats fait les choses un peu différemment. Au lieu de deviner un mot en fonction de son contexte (les mots avant et après), cette autre architecture essaie de deviner les mots voisins en utilisant le mot courant. On peut penser à la fenêtre qu’il glisse sur le texte d’entraînement comme ressemblant à ceci :

Les cases roses sont de différentes nuances parce que cette fenêtre coulissante crée en fait quatre échantillons distincts dans notre jeu de données d’entraînement :
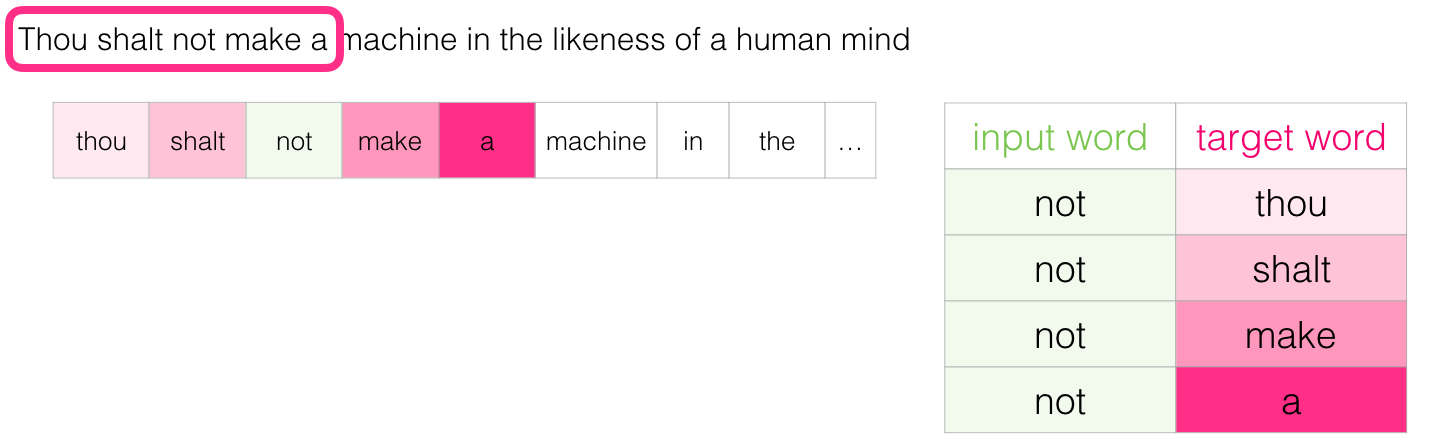
Cette méthode s’appelle l’architecture skipgram.
Nous pouvons visualiser la fenêtre coulissante comme suit :

Cela ajoute ces quatre échantillons à notre jeu de données d’entraînement :
Nous glissons ensuite notre fenêtre vers la position suivante :
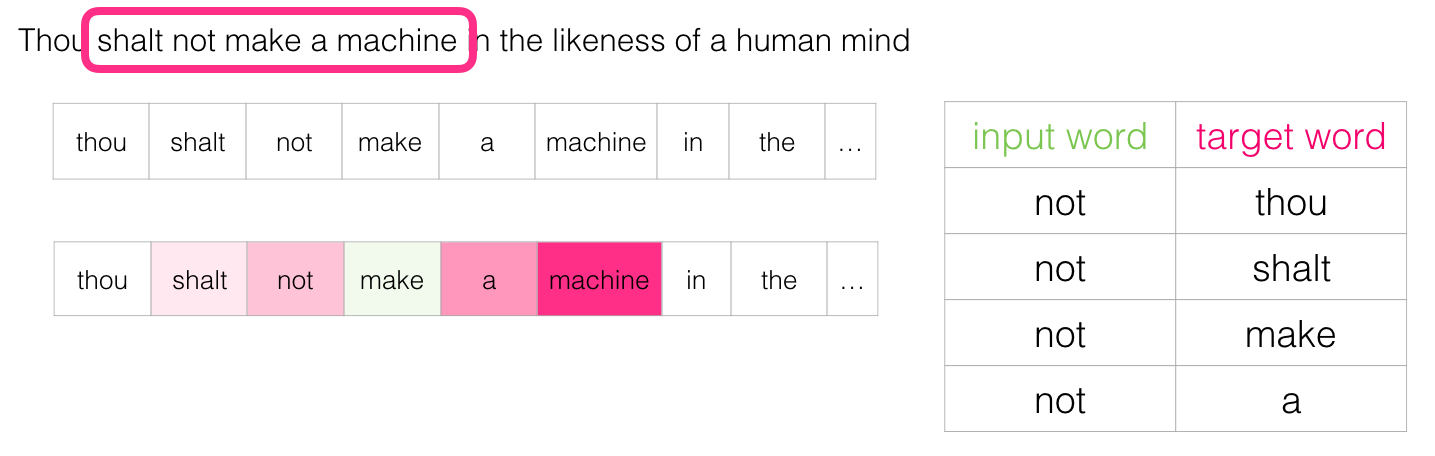
Ce qui génère nos quatre exemples suivants :

Quelques positions plus tard, nous avons beaucoup d’autres exemples :
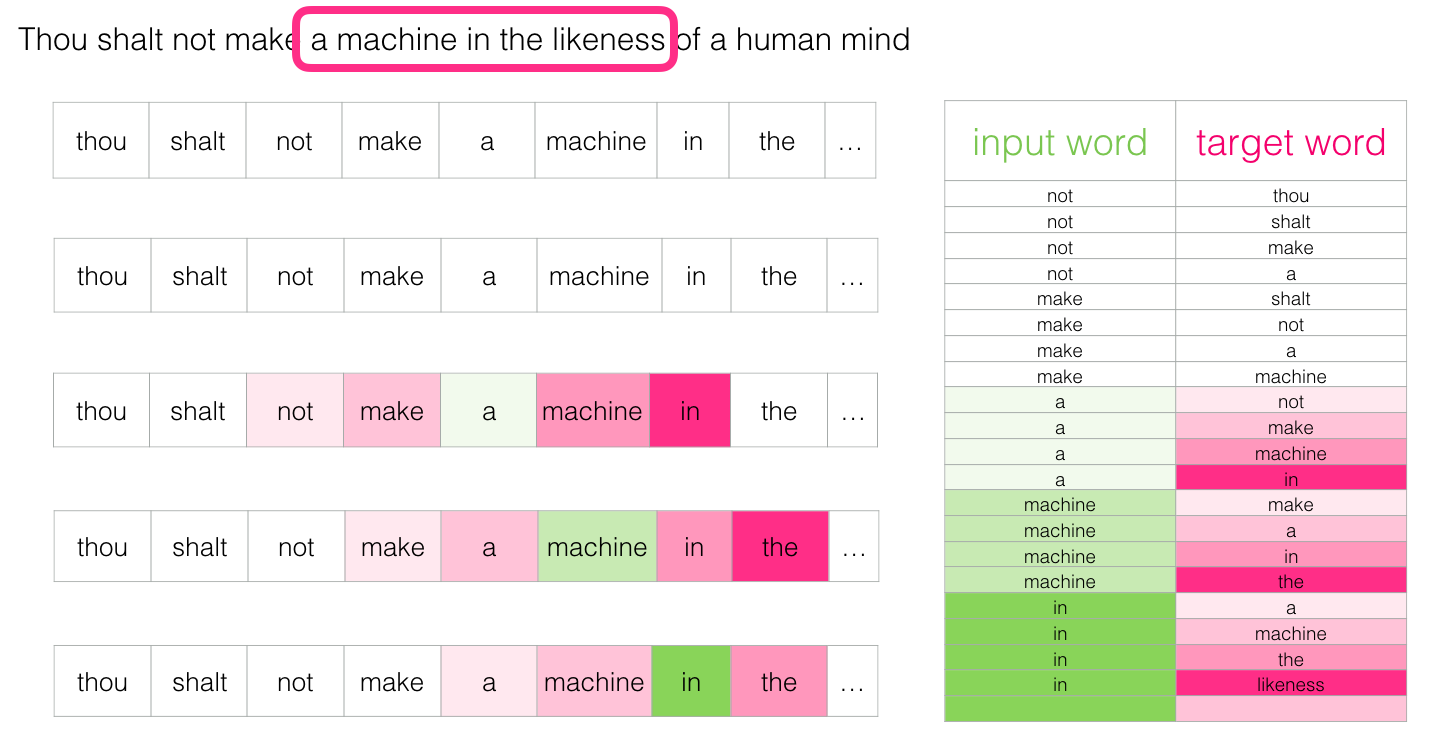
8. Repenser le processus d’entraînement
Maintenant que nous avons notre jeu de données d’entraînement extrait d’un texte pour la méthode skipgram, voyons comment nous l’utilisons pour entraîner un modèle de langage neuronal qui prédit le mot voisin.
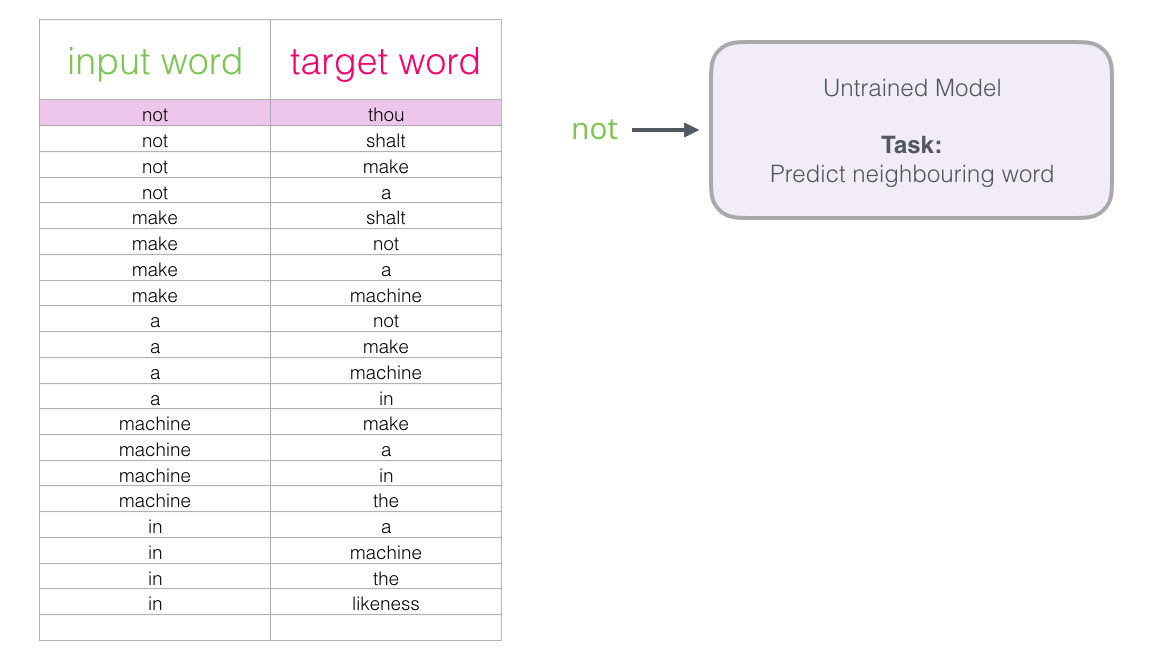
Nous commençons par le premier échantillon de notre jeu de données. Nous saisissons la caractéristique et l’envoyons au modèle non entrainé en lui demandant de prédire un mot voisin approprié.
Le modèle réalise les trois étapes et produit un vecteur de prédiction (avec une probabilité assignée à chaque mot de son vocabulaire). Comme le modèle n’est pas entrainé, sa prédiction est certainement erronée à ce stade. Mais ce n’est pas grave. Nous savons quel mot il aurait dû deviner :
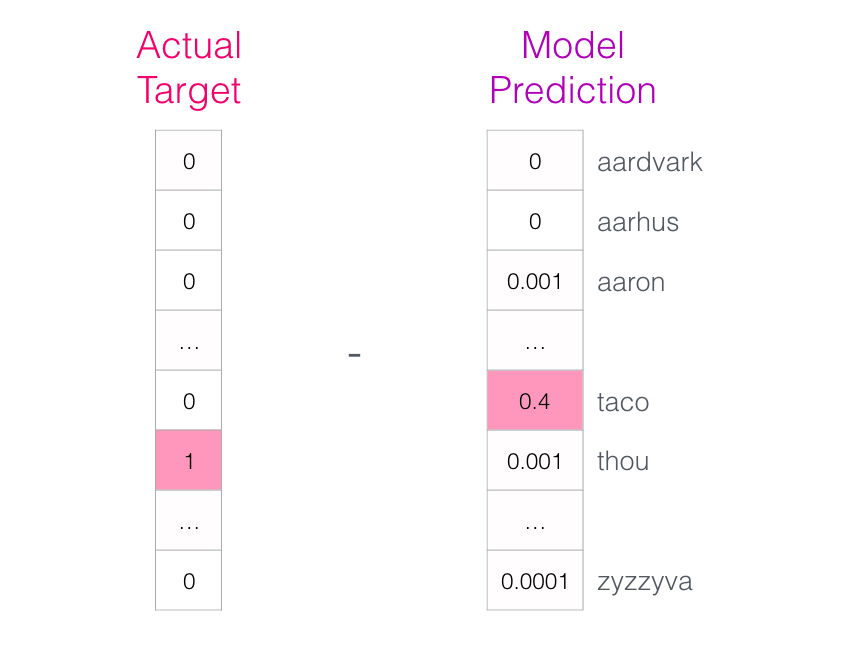
Nous soustrayons les deux vecteurs pour obtenir un vecteur d’erreur :
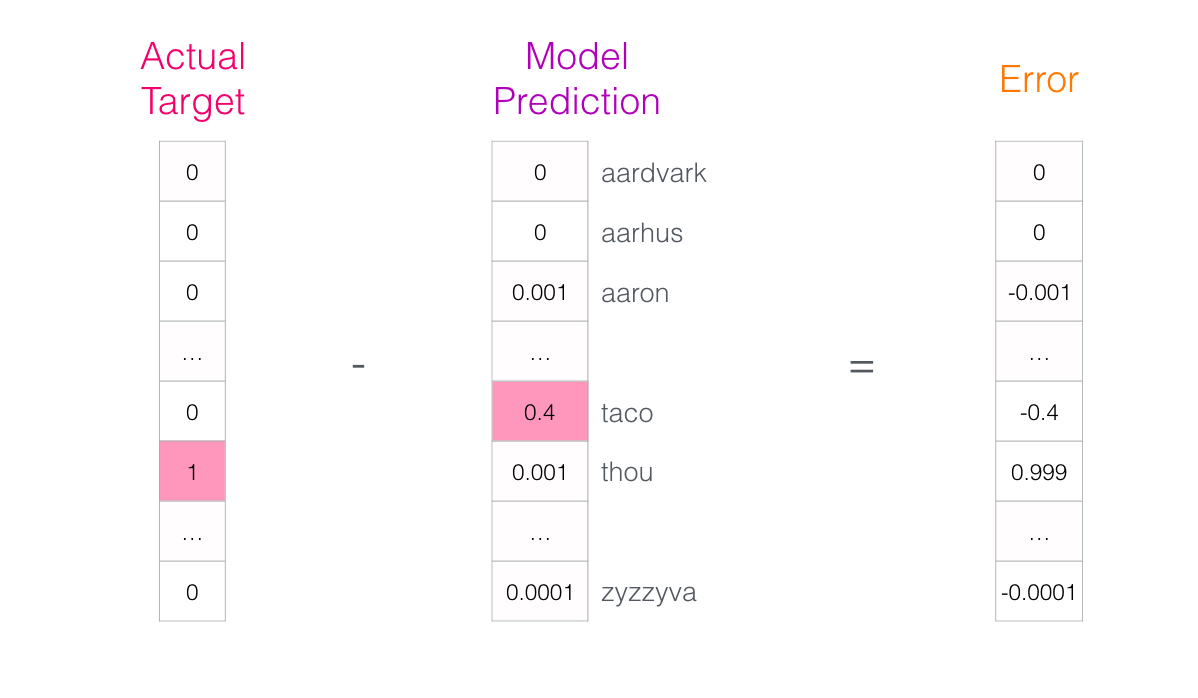
Ce vecteur d’erreur peut maintenant être utilisé pour mettre à jour le modèle de sorte que la prochaine fois, il est un peu plus susceptible de deviner « thou » quand il a « not » en entrée.
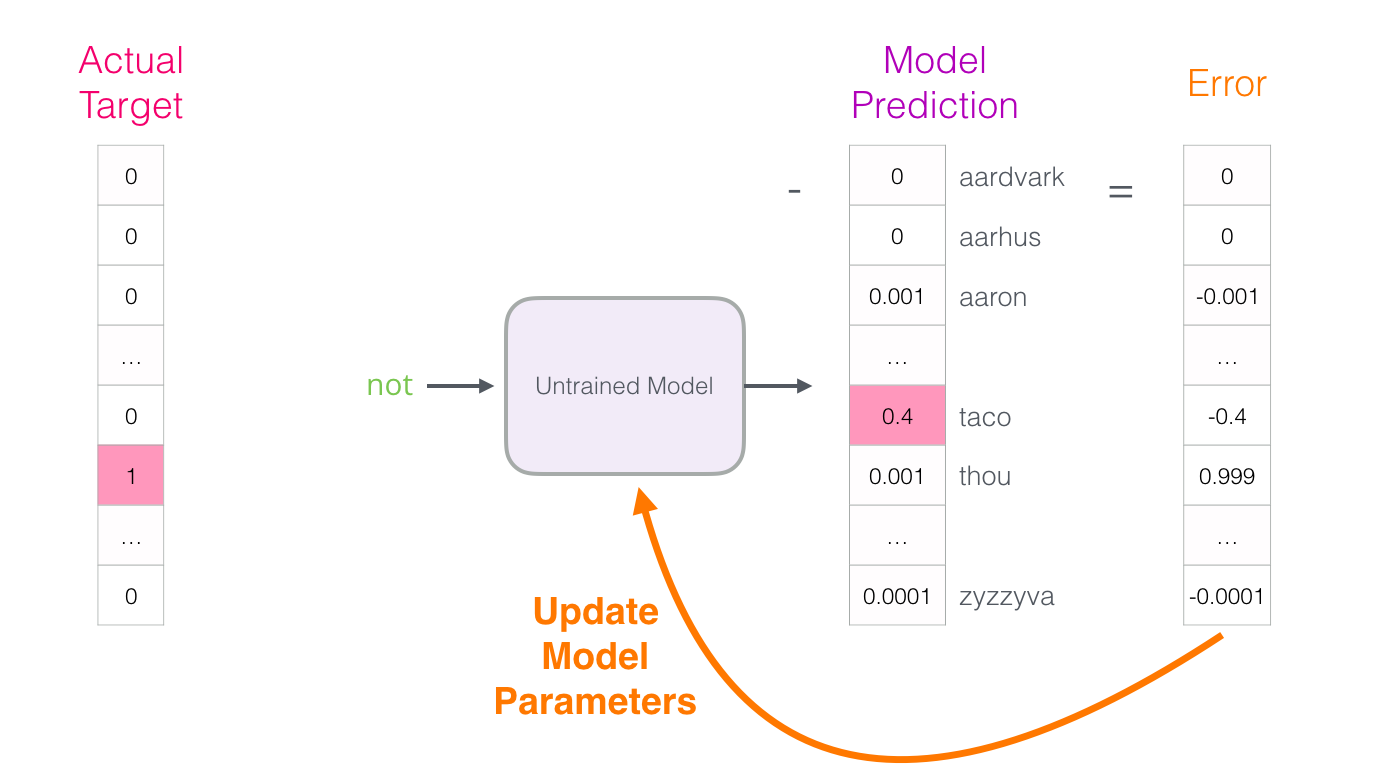
Voilà qui conclut la première étape d’entraînement. Nous procédons de la même façon avec le prochain échantillon de notre jeu de données, puis le suivant, jusqu’à ce que nous ayons couvert tous les échantillons. Cela conclut une époque d’entraînement. Nous recommençons pendant un certain nombre d’époques et nous obtenons notre modèle entraîné. Nous pouvons en extraire la matrice d’enchâssements et l’utiliser pour toute autre application.
Bien que cela élargisse notre compréhension du processus, ce n’est pas encore la façon dont word2vec est réellement entraîné. Il nous manque quelques idées clés.
9. Pêche à l’exemple négatif
Rappelez-vous les trois étapes de la façon dont ce modèle de langage neuronal calcule sa prédiction :
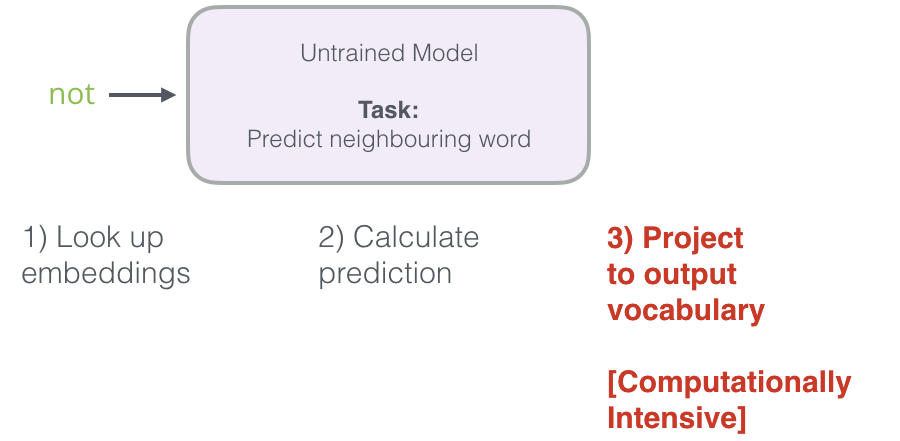
La troisième étape est très coûteuse d’un point de vue informatique (computationnel). Nous devons faire quelque chose pour améliorer nos performances.
Une façon de faire est de diviser notre cible en deux étapes :
1) Générer des enchâssements de mots de haute qualité (pas besoin de prédire le mot suivant).
2) Utiliser ces enchâssements de haute qualité pour entraîner un modèle de langage et faire la prédiction du mot suivant.
Nous nous concentrerons sur l’étape 1.
Pour générer des enchâssements de haute qualité, nous pouvons passer d’un modèle de prédiction d’un mot voisin à un modèle qui prend le mot d’entrée et le mot de sortie, et sort un score indiquant s’ils sont voisins ou non (0 pour « non voisin », 1 pour « voisin »).
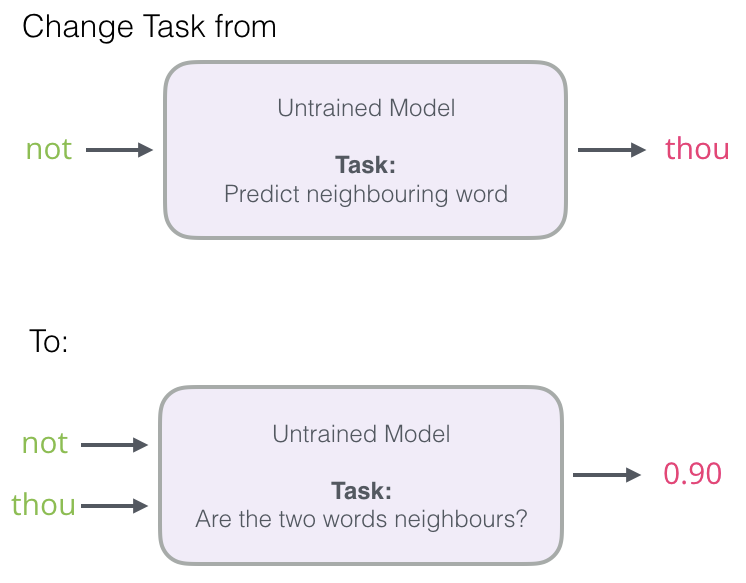
Ce simple changement transforme le modèle dont nous avons besoin. Nous passons d’un réseau neuronal à un modèle de régression logistique qui est ainsi beaucoup plus simple et beaucoup plus rapide à calculer.
Ce changement nécessite de changer la structure de notre ensemble de données : le label est maintenant une nouvelle colonne avec les valeurs 0 ou 1. Ils seront tous à 1 puisque tous les mots que nous avons ajoutés sont voisins.
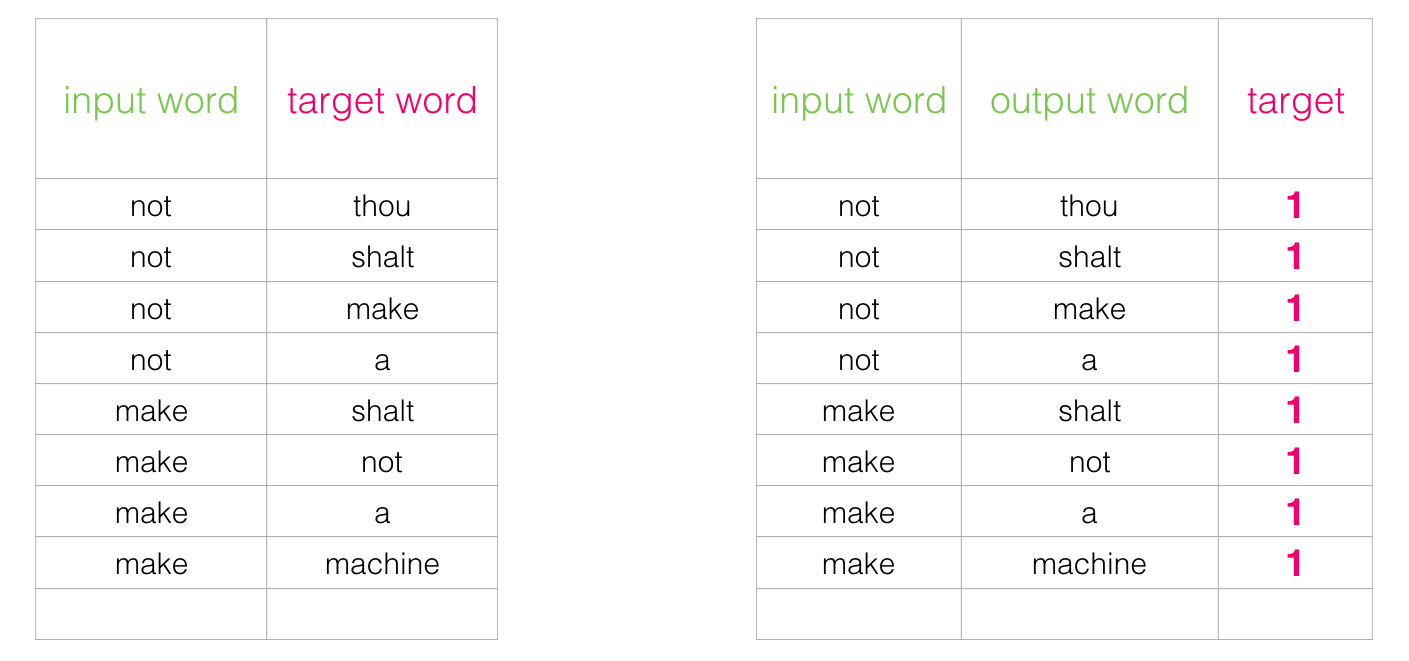
Le temps d’exécution est considérablement réduit, pouvant maintenant traiter des millions d’exemples en quelques minutes. Mais il y a une faille à combler. Si tous nos exemples sont positifs (cible : 1), nous nous ouvrons à la possibilité d’un modèle qui renvoie toujours 1 (atteignant 100% de précision mais n’apprenant rien et générant des enchâssements « déchets »).
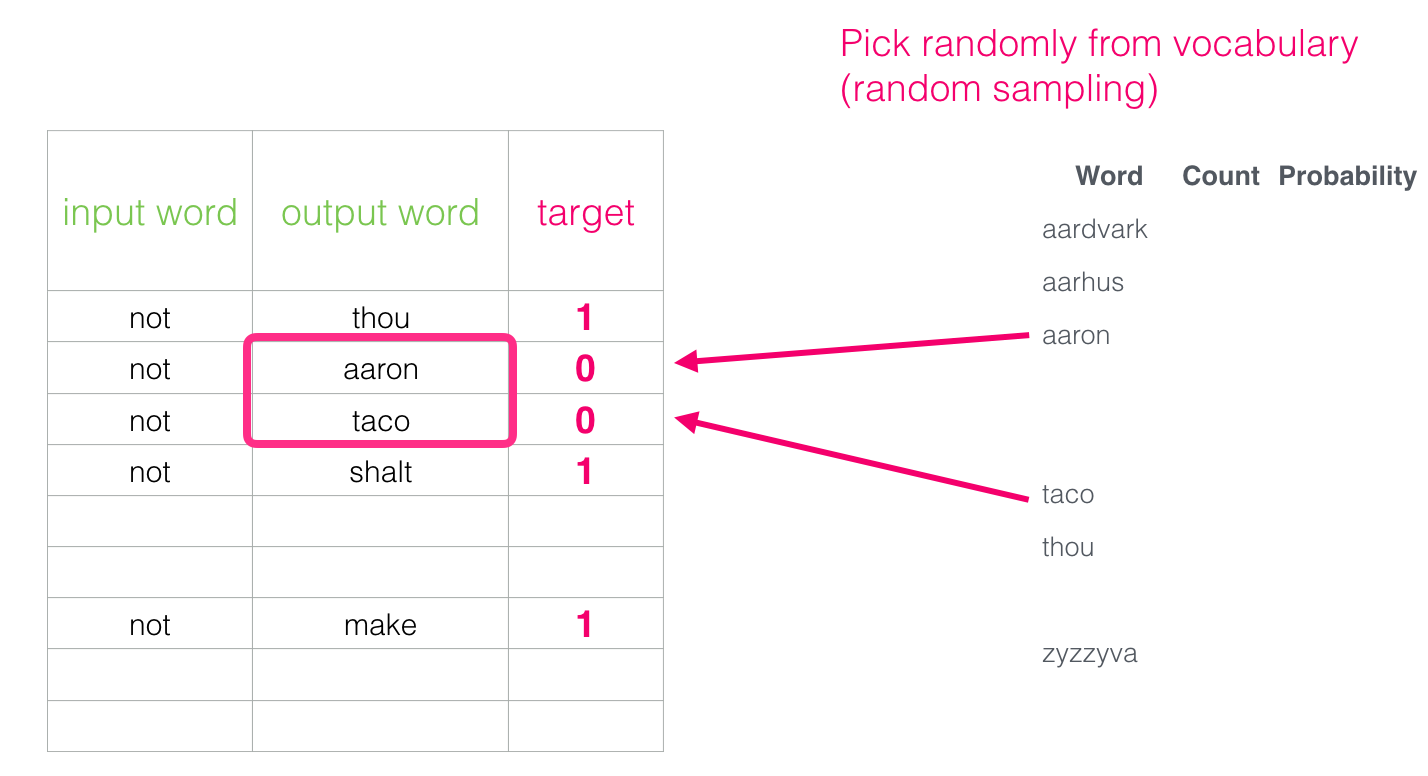
Pour y remédier, nous devons introduire des échantillons négatifs dans notre jeu de données, c’est à dire des échantillons de mots qui ne sont pas voisins. Notre modèle doit retourner 0 pour ces échantillons. C’est un défi que le modèle doit relever avec acharnement mais toujours à une vitesse fulgurante.

Nous assignons ensuite comme mot de sortie des mots pris au hasard dans notre vocabulaire.
Cette idée s’inspire de la Noise-Contrastive Estimation. Nous comparons le signal réel (exemples positifs de mots voisins) avec le bruit (mots choisis au hasard qui ne sont pas voisins). Il en résulte un grand compromis entre l’efficacité informatique et l’efficacité statistique.
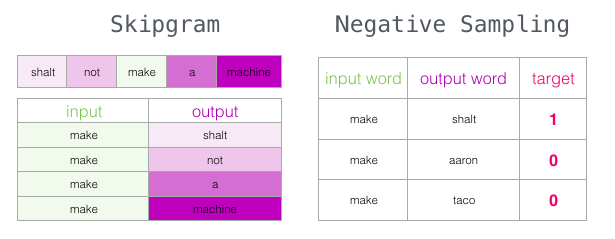
10. Skipgram with Negative Sampling (SGNS)
Nous avons maintenant couvert deux des idées centrales de Word2vec. Associées, elles s’appellent Skipgram with Negative Sampling.
11. Processus d’entraînement de Word2vec
Maintenant que nous avons établi les deux idées centrales du SGNS, nous pouvons examiner de plus près le processus d’entraînement de Word2vec.
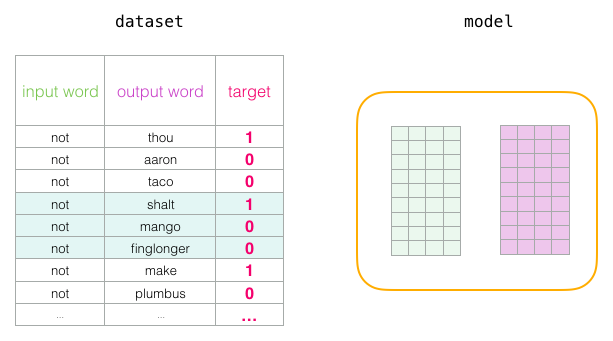
Avant le début du processus d’entraînement, nous prétraitons le texte sur lequel nous entraînons le modèle. Dans cette étape, nous déterminons la taille de notre vocabulaire (nous l’appellerons vocab_size, disons 10 000) et quels mots lui appartiennent.
Au début de la phase d’entraînement, nous créons deux matrices : une matrice d’enchâssements et une matrice ce contexte. Ces deux matrices ont un enchâssement pour chaque mot de notre vocabulaire (vocab_size est donc une de leurs dimensions). La seconde dimension est la longueur que nous voulons que chaque vecteur d’enchâssements soit (une valeur généralement utilisée de embedding_size est 300, mais nous avons regardé un exemple de 50 plus tôt dans ce post avec le mot « king »).

Au début de l’entraînement, nous initialisons ces matrices avec des valeurs aléatoires. Ensuite, nous commençons le processus. A chaque étape de l’entraînement, nous prenons un exemple positif et les exemples négatifs qui y sont associés. Prenons notre premier groupe :
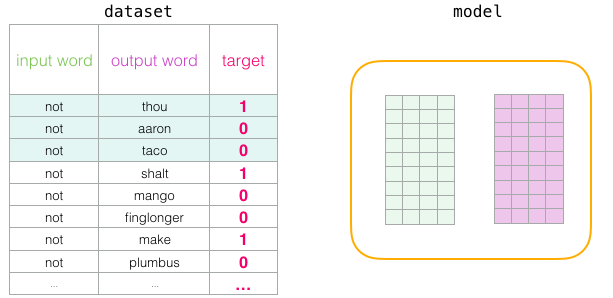
Maintenant nous avons quatre mots : le mot d’entrée « not » et les mots de sortie/contexte : « thou » (le voisin actuel), « aaron » et « taco » (les exemples négatifs).
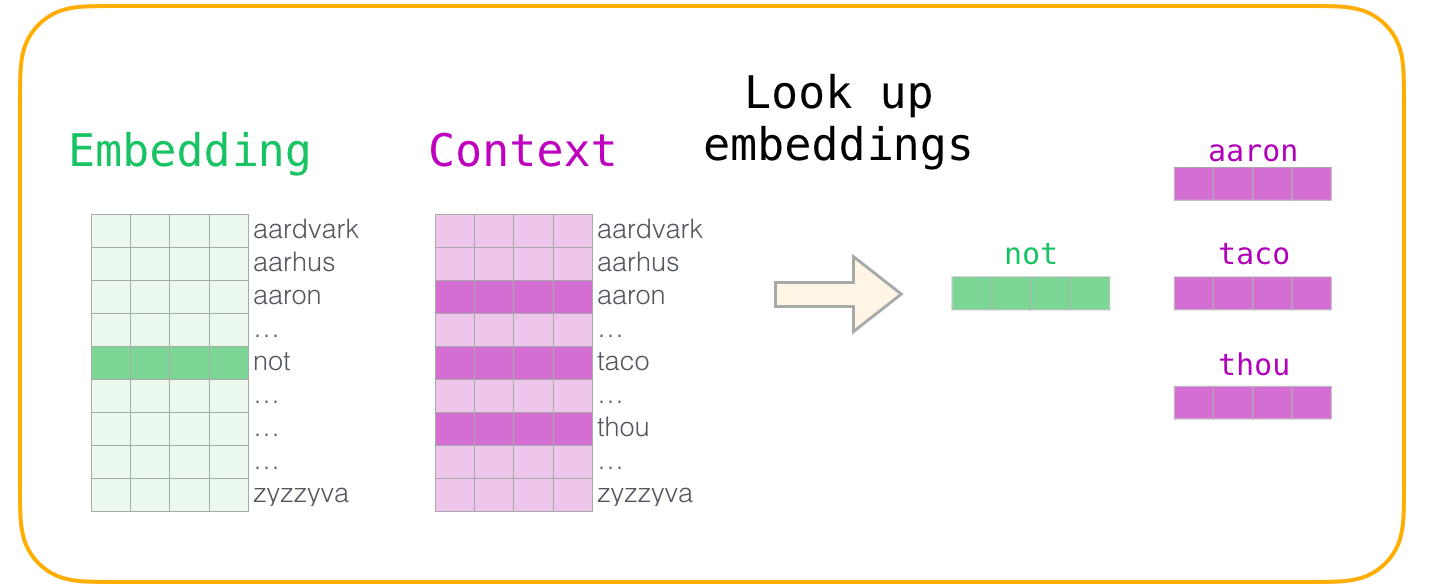
Nous procédons à la recherche de leurs enchâssements. Pour le mot d’entrée, nous regardons dans la matrice d’enchâssements. Pour les mots de contexte, nous regardons dans la matrice de contexte.
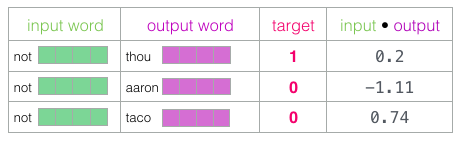
Ensuite, nous effectuons le produit scalaire de l’enchâssement d’entrée avec chacun des enchâssements de contexte. Dans chaque cas, cela donne un nombre indiquant la similarité entre les enchâssements d’entrée et de contexte.
Nous devons maintenant trouver un moyen de transformer ces scores en quelque chose qui ressemble à des probabilités. Nous avons besoin qu’ils soient tous positifs et qu’ils aient des valeurs entre 0 et 1. Pour cela, nous utilisons la fonction sigmoïde.
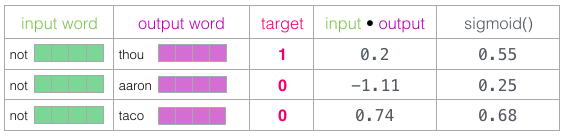
Vous pouvez voir que « taco » a le score le plus élevé et qu’« aaron » a toujours le score le plus bas avant et après les opérations sigmoïdes.
Maintenant que le modèle non entraîné a fait une prédiction, et vu que nous avons un label auquel la comparer, calculons l’erreur dans la prédiction du modèle. Pour ce faire, il suffit de soustraire les scores sigmoïdes des labels (colonne target).
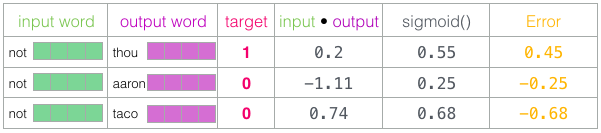
Nous pouvons maintenant utiliser ce score d’erreur pour ajuster les enchâssements de « not », « thou », « aaron », et « taco » afin que la prochaine fois que nous ferons ce calcul, le résultat soit plus proche des scores cibles.

L’étape d’entraînement est terminée. Nous en ressortons avec des enchâssements légèrement meilleurs pour les mots impliqués dans cette étape (« not », « thou », « aaron », et « taco »). Nous passons alors à l’échantillon positif (et les échantillons négatifs associés) suivant et recommençons le même processus.
L’enchâssement continue d’être amélioré pendant que nous parcourons l’ensemble de nos données un certain nombre de fois. Nous pouvons alors arrêter le processus d’entraînement. Nous abandonnons la matrice de contexte et utilisons la matrice d’enchâssements pour la tâche suivante.
12. Taille de la fenêtre et nombre d’exemples négatifs
La taille de la fenêtre et le nombre d’échantillons négatifs sont deux hyperparamètres clés dans le processus d’entraînement de Word2vec.
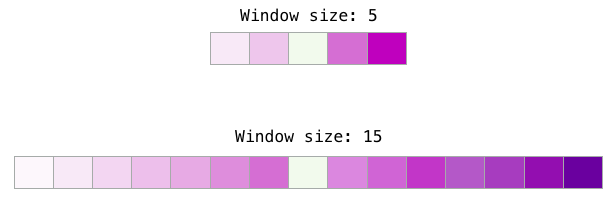
La taille de la fenêtre la plus adaptée varie en fonction de la tâche à effectuer.
Une heuristique est que des fenêtres de petite taille (2 à 15) conduisent à des enchâssements avec des scores de similarité élevés entre deux enchâssements. Cela signifie que les mots sont interchangeables (remarquez que les antonymes sont souvent interchangeables si l’on considère seulement les mots environnants. Par exemple, bon et mauvais apparaissent souvent dans des contextes similaires).
Des fenêtres de plus grande taille (15 à 50 ou même plus) mènent à des enchâssements où la similarité donne une indication sur la parenté des mots. Dans la pratique, vous devrez souvent fournir des annotations qui guident le processus d’enchâssements menant à une similarité utile pour votre tâche. La taille par défaut de la fenêtre de la librairie Gensim est 5 (deux mots avant et deux mots après le mot entré, en plus du mot entré lui-même).
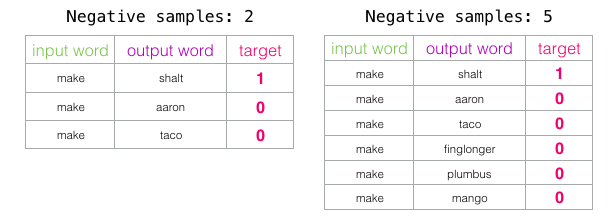
Le nombre d’échantillons négatifs est un autre facteur du processus d’entraînement. L’article original prescrit 5 à 20 comme étant un bon nombre d’échantillons négatifs. Il indique également que 2 à 5 semble être suffisant quand vous avez un jeu de données assez grand. La valeur par défaut de Gensim est de 5 échantillons négatifs.
Références
-
The illustrated word2vec de Jay Alammar (2019)
-
A Neural Probabilistic Language Model de Bengio et al. (2003)
-
Noise-contrastive estimation: A new estimation principleforunnormalized statistical models de Gutmann et Hyvärinen (2010)
Citation
@inproceedings{word_embeddings_blog_post,
author = {Loïck BOURDOIS},
title = {Illustration du Word Embedding et du Word2vec},
year = {2019},
url = {https://lbourdois.github.io/blog/nlp/word_embedding/}
}