Avant-propos
Cet article est une traduction de l’article de Jay Alammar : Visualizing neural machine translation mechanics of seq2seq models with attention.
Merci à lui de m’avoir autorisé à effectuer cette traduction.
1. Introduction
Les modèles de séquence à séquence sont des modèles d’apprentissage profond qui ont connu beaucoup de succès dans des tâches comme la traduction automatique, le résumé de texte et le sous-titrage d’images. Google Translate a commencé à utiliser un tel modèle à partir de fin 2016. Ces modèles sont expliqués dans les deux études pionnières (Sutskever et al., 2014, Cho et al., 2014).
Pour bien comprendre le modèle et le mettre en œuvre, il faut démêler une série de concepts qui s’imbriquent les uns dans les autres.
L’objectif de cet article est qu’il puisse être un compagnon utile à la lecture des documents mentionnés ci-dessus (et des documents sur l’attention exposés plus loin dans l’article).
Un modèle de séquence à séquence est un modèle qui prend une séquence d’éléments (mots, lettres, caractéristiques d’une image, etc.) et en sort une autre séquence. Un modèle entraîné fonctionnerait comme ça :
En traduction automatique, une séquence est une série de mots, traités les uns après les autres. Le résultat est donc aussi une série de mots :
2. Regardons sous le capot
Sous le capot, le modèle est composé d’un encodeur et d’un décodeur.
L’encodeur traite chaque élément de la séquence d’entrée. Il compile les informations qu’il capture dans un vecteur (appelé context). Après avoir traité toute la séquence d’entrée, l’encodeur envoie le contexte au décodeur, qui commence à produire la séquence de sortie item par item.
La même logique est appliquée dans le cas de la traduction automatique.
Le contexte est un vecteur (un tableau de nombres essentiellement) dans le cas de la traduction automatique. L’encodeur et le décodeur ont tendance à être tous deux des réseaux de neurones récurrents.

Vous pouvez définir la taille du vecteur de context lorsque vous configurez votre modèle.
C’est essentiellement le nombre d’unités cachées dans l’encodeur RNN.
Ces visualisations montrent un vecteur de taille 4, mais dans les applications du monde réel le vecteur de contexte serait de taille 256, 512, ou 1024.
Par conception, un RNN prend deux entrées à chaque pas de temps : une entrée (dans le cas de l’encodeur, un mot de la phrase d’entrée), et un état caché. Le mot, cependant, doit être représenté par un vecteur. Pour transformer un mot en vecteur, nous nous tournons vers les méthodes d’enchâssement de mots (cf. l’article sur le word embedding du blog). Ils transforment les mots en espaces vectoriels qui capturent une grande partie de l’information sémantique des mots (ex : roi – homme + femme = reine).
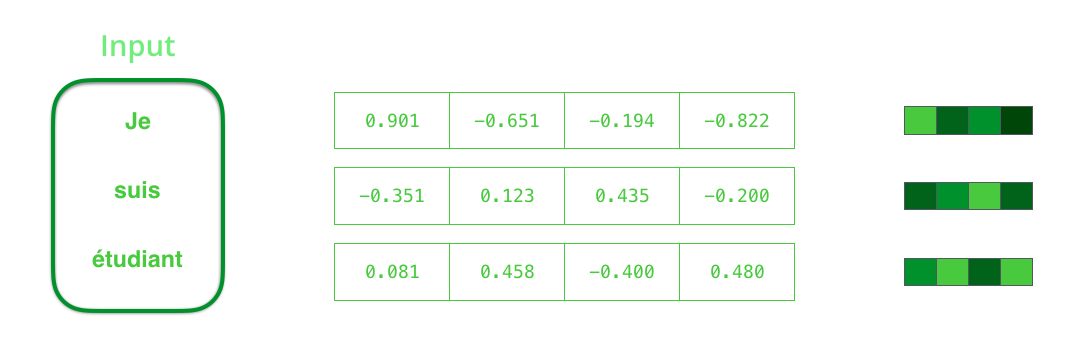
Maintenant que nous avons présenté nos principaux vecteurs, récapitulons la mécanique d’un RNN et établissons un visuel pour décrire ces modèles :
Dans la visualisation suivante, chaque « impulsion » pour l’encodeur et le décodeur représente le traitement des entrées par le RNN et la génération de la sortie. Comme l’encodeur et le décodeur sont tous deux des RNNs, chaque fois que l’une des deux étapes effectue un certain traitement, elle met à jour son état caché en fonction de ses entrées et des entrées précédentes qu’elle a vues.
Regardons les états cachés de l’encodeur. Remarquez comment le dernier état caché est en fait le contexte que nous transmettons au décodeur :
Le décodeur maintient également un état caché qu’il passe d’une étape à l’autre. Nous ne l’avons tout simplement pas visualisé dans ce graphique car nous nous préoccupons des principales parties du modèle pour le moment.
Voyons maintenant une autre façon de visualiser un modèle de séquence à séquence. Cette animation facilitera la compréhension des graphiques statiques qui décrivent ces modèles. C’est ce qu’on appelle une vue « déroulée » où au lieu de montrer le décodeur, on en montre une copie pour chaque pas de temps. De cette façon, nous pouvons examiner les entrées et les sorties de chaque étape.
3. L’attention
Le vecteur de contexte s’est avéré être un goulot d’étranglement pour ces types de modèles. Il était donc difficile pour les modèles de composer avec de longues phrases. Une solution a été proposée dans Bahdanau et al., 2014 et Luong et al., 2015. Ces articles introduisirent et affinèrent une technique appelée « attention », qui améliora considérablement la qualité des systèmes de traduction automatique. L’attention permet au modèle de se concentrer sur les parties pertinentes de la séquence d’entrée si nécessaire.
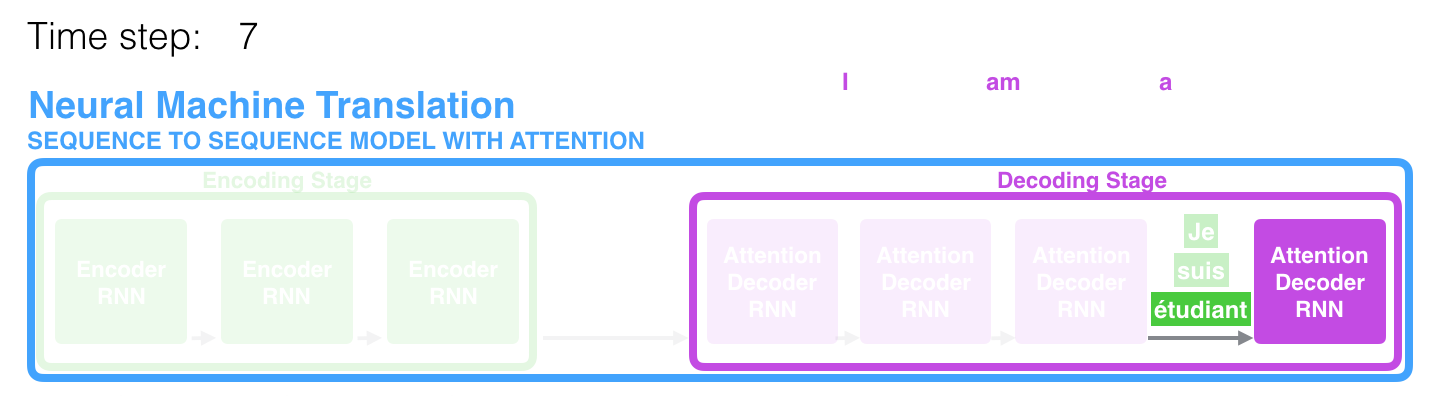
A l’étape 7, le mécanisme d’attention permet au décodeur de se concentrer sur le mot « étudiant » avant de générer la traduction anglaise. Cette capacité d’amplifier le signal de la partie pertinente de la séquence d’entrée permet aux modèles d’attention de produire de meilleurs résultats que les modèles sans attention.
Continuons à regarder les modèles d’attention à ce haut niveau d’abstraction. Un modèle d’attention diffère d’un modèle de sequence à sequence classique de deux façons principales :
- Tout d’abord, l’encodeur transmet beaucoup plus de données au decodeur. Au lieu de passer le dernier état caché de l’étape d’encodage, l’encodeur passe tous les états cachés au decodeur :
- Deuxièmement, un décodeur d’attention fait une étape supplémentaire avant de produire sa sortie. Afin de se concentrer sur les parties de l’entrée qui sont pertinentes, le décodeur fait ce qui suit :
- Il regarde l’ensemble des états cachés de l’encodeur qu’il a reçu (chaque état caché de l’encodeur est le plus souvent associé à un certain mot dans la phrase d’entrée).
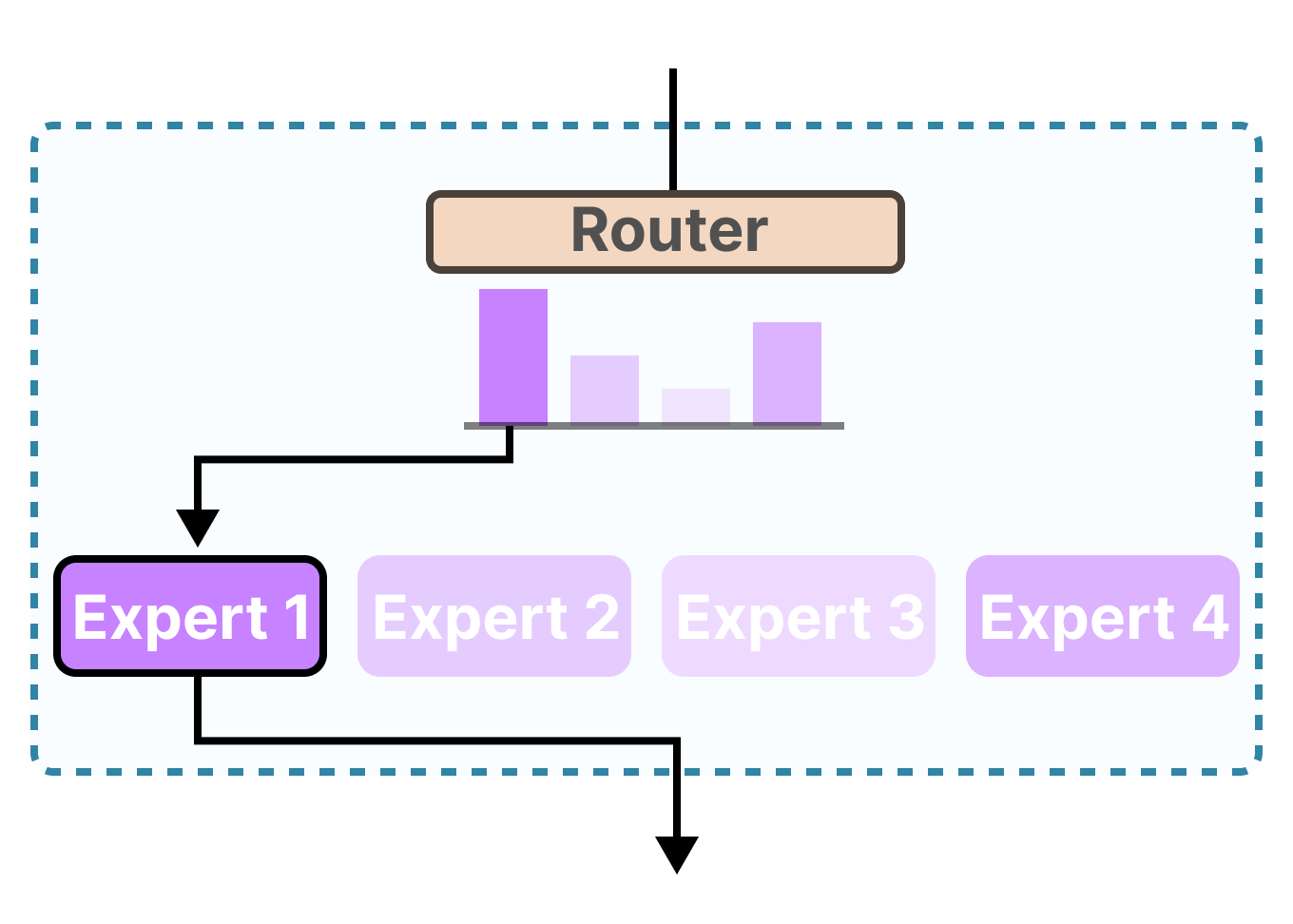
- Il donne un score à chaque état caché (on passe l’étape de comment le scoring se fait pour le moment)
- Il multiplie chaque état caché par son score attribué via softmax (amplifiant ainsi les états cachés avec des scores élevés, et noyant les états cachés avec des scores faibles)
Le « scorage » se fait à chaque pas de temps (nouveau mot) du côté du décodeur.
Regardons maintenant comment fonctionne le processus de l’attention et regroupons le tout dans la visualisation qui suit :
1) Le décodeur d’attention prend en entrée l’enchâssement du token
2) Le RNN traite ces entrées, produisant une sortie et un nouveau vecteur d’état caché (\(h_{4}\)). La sortie est supprimée.
3) L’étape d’attention : nous utilisons les états cachés de l’encoder et le vecteur (\(h_{4}\)) pour calculer un vecteur de contexte (\(C_{4}\)) pour cette étape.
4) Nous concaténons \(h_{4}\) et \(C_{4}\) en un seul vecteur.
5) Nous faisons passer ce vecteur par un réseau neuronal feed-forward (un réseau entraîné conjointement avec le modèle).
6) La sortie du réseau feed-forward indique le mot de sortie de ce pas de temps (= la traduction du mot en entrée).
7) On répète les étapes précédentes pour chaque mots. L’état caché fournit en entrée n’étant plus l’initial mais celui de la couche précédente (\(h_{4}\) dans notre exemple) et l’enchâssement n’est plus celui du token
Une autre façon de voir à quelle partie de la phrase d’entrée nous prêtons attention à chaque étape de décodage :
Notons que le modèle n’associe pas seulement le premier mot de la sortie avec le premier mot de l’entrée. En fait, il a appris pendant la phase d’entrainement la façon dont sont liés les mots dans cette paire de langues (le français et l’anglais dans notre exemple). Un exemple de ce mécanisme est donné dans l’article de Bahdanau et al., 2014 :

Un tutoriel sur l’implémentation en Python (TensorFlow) d’un tel modèle est disponible sur ce Github : https://github.com/tensorflow/nmt.
Conclusion
Cet article est une introduction au mécanisme d’attention. Il se veut assez général car il existe en réalité plusieurs variantes de ce mécanisme. Ainsi si vous n’avez pas forcément tout compris, nous revenons plus en détails sur ces variantes dans les articles consacrés au transformer, au modèle BERT et au modèle GPT-2.
Si vous préférez les vidéos aux textes, vous pouvez regarder la vidéo de présentation du phénomène d’attention par César Laurent (doctorant au MILA sous la co-direction de Pascal Vincent et Yoshua Bengio) : https://www.youtube.com/watch?v=stD_mY2OYj4.
Il donne des exemples d’application tel que la traduction ou encore la génération de légende à partir d’un texte ou d’une vidéo.
Références
- Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) de Jay Alammar (2018)
- Neural Machine Translation by Jointly Learning to Align and Translate de Bahdanau et al. (2014)
- EH2018-11 - Modèle : Réseaux récurrents (Partie 2) de César Laurent (2018)
- Effective Approaches to Attention-based Neural Machine Translation de Luong et al. (2015)
- Neural Machine Translation (seq2seq) Tutorial de Luong et al. (2017)
Citation
@inproceedings{seq_to_seq_blog_post,
author = {Loïck BOURDOIS},
title = {Le seq2seq et le processus d'attention},
year = {2019},
url = {https://lbourdois.github.io/blog/nlp/Seq2seq-et-attention/}
}