Avant-propos
Cet article est une traduction de celui de Maarten Grootendorst : A Visual Guide to LLM Agents.
Maarten est co-auteur du livre Hands-On Large Language Models.
Cet article aborde la partie « théorique » du fonctionnement des agents. Pour une partie davantage « pratique », vous pouvez consultez le cours d’Hugging Face sur le sujet dont j’ai participé à la traduction en français. Il aborde notamment comment implémenter des agents avec les librairies smolagents, LlamaIndex ou encore LangGraph.
Introduction
Les agents basés sur un LLM se popularisent, semblant prendre le pas sur l’interaction la plus populaire avec les LLM que nous connaissons à savoir la discussion. Ces capacités incroyables ne sont pas faciles à créer et nécessitent de nombreux composants fonctionnant en tandem.
Dans cet article, nous allons explorer le domaine des agents, leurs principaux composants, et les frameworks Multi-Agents via plus de 60 illustrations.
Qu’est-ce qu’un agent ?
Pour comprendre ce que sont les agents basés sur un LLM, explorons d’abord les capacités de base de ces modèles. Traditionnellement, un LLM ne fait rien de plus que de prédire le token suivant.
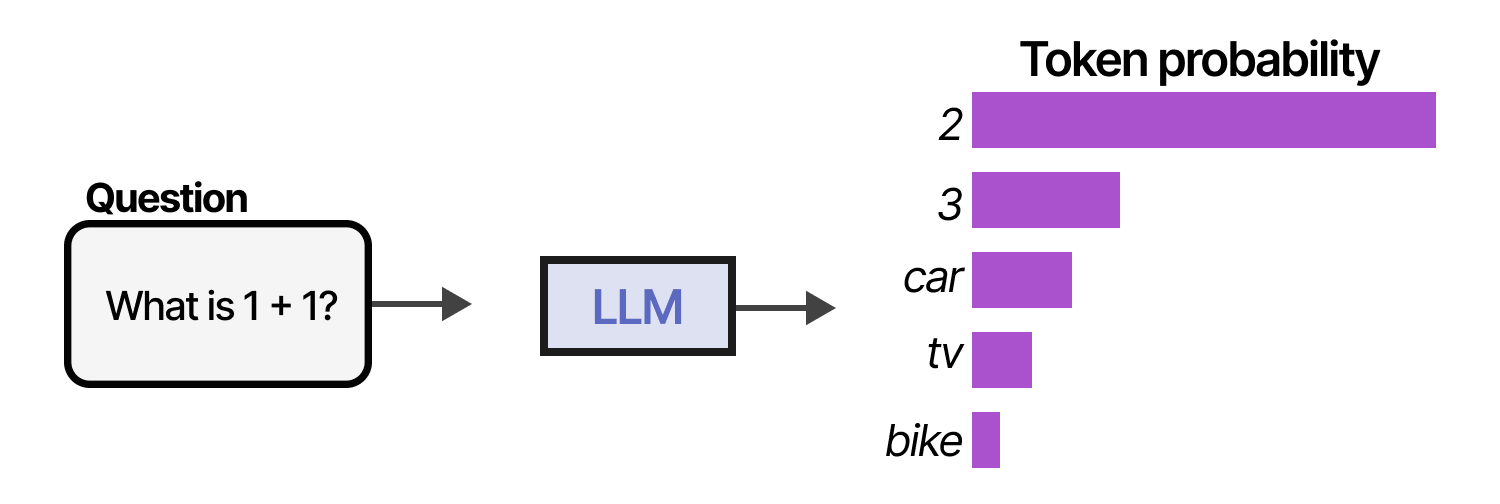
En échantillonnant de nombreux tokens à la suite, nous pouvons imiter les conversations et utiliser le LLM pour donner des réponses plus complètes à nos requêtes.

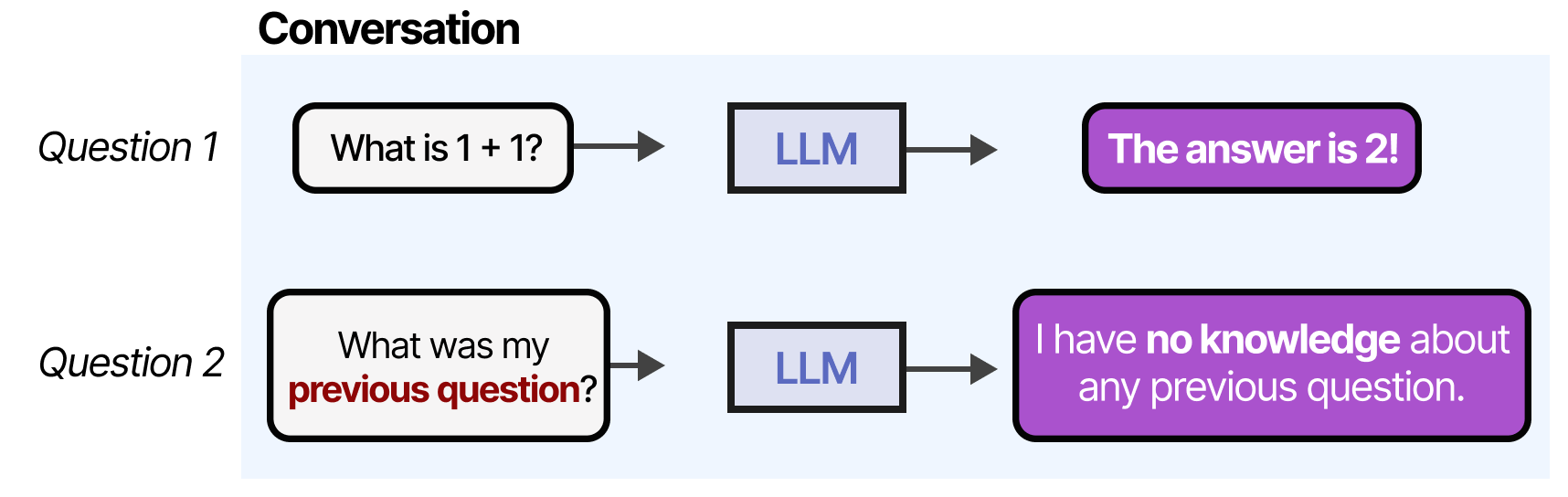
Cependant, si nous poursuivons la « conversation », se produira l’un de des principaux inconvénients de n’importe quel LLM : il ne se souviendra pas des échanges précédents.
Les LLM échouent souvent également dans de nombreuses autres tâches, notamment les mathématiques de base telles que les multiplications et les divisions :

Cela signifie-t-il que les LLM sont horribles ? Certainement pas ! Il n’est pas nécessaire qu’ils soient capables de tout car nous pouvons compenser leur désavantage par des outils externes, des systèmes de mémoire et de récupération. Grâce à des systèmes externes, les capacités du LLM peuvent être améliorées. Anthropic appelle cela le « LLM augmenté ».

Par exemple, face à une question de mathématiques, le LLM peut décider d’utiliser l’outil approprié (une calculatrice).
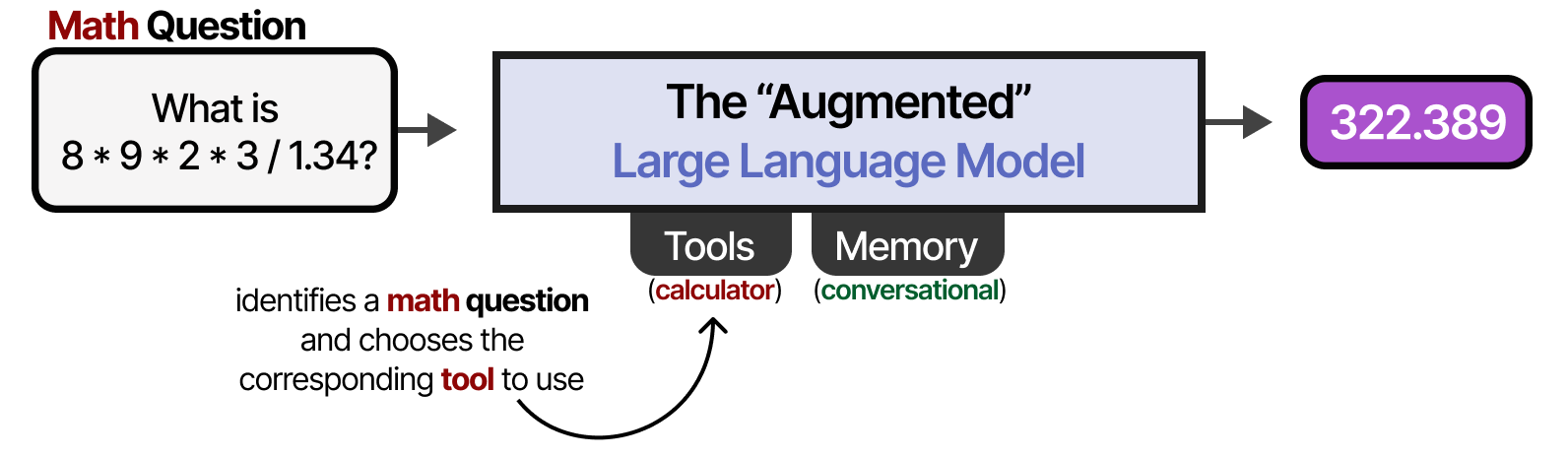
Ce « LLM augmenté » est-il donc un agent ? Non ! Mais peut-être un peu oui…
Commençons en donnant la définition des agents de Russell & Norvig (2016) :
Un agent est tout ce qui peut être considéré comme percevant son environnement par le biais de capteurs et agissant sur cet environnement par le biais d’actionneurs.
Les agents interagissent avec leur environnement et se composent généralement de plusieurs éléments importants :
- Environnements : le monde avec lequel l’agent interagit
- Capteurs : utilisés pour observer l’environnement
- Actionneurs : outils utilisés pour interagir avec l’environnement
- Effecteurs : le « cerveau » ou les règles qui décident comment passer des observations aux actions.
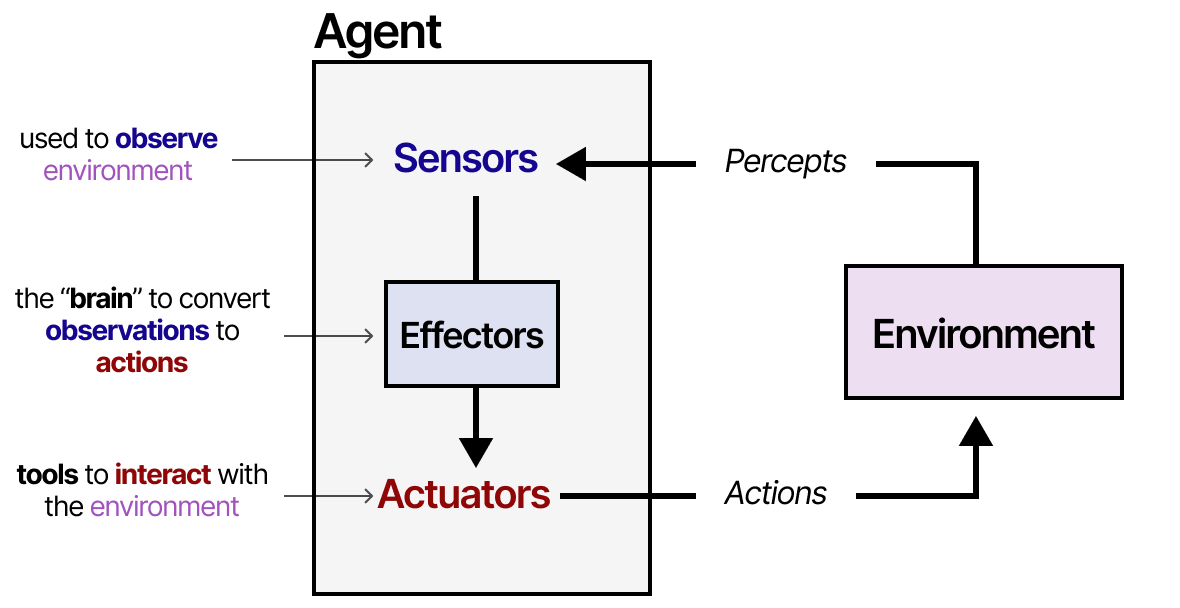
Ce cadre est utilisé pour tous les types d’agents qui interagissent avec toutes sortes d’environnements, comme les robots qui interagissent avec leur environnement physique ou les agents d’intelligence artificielle qui interagissent avec des logiciels. Nous pouvons généraliser un peu ce cadre pour qu’il convienne davantage au « LLM augmenté ».
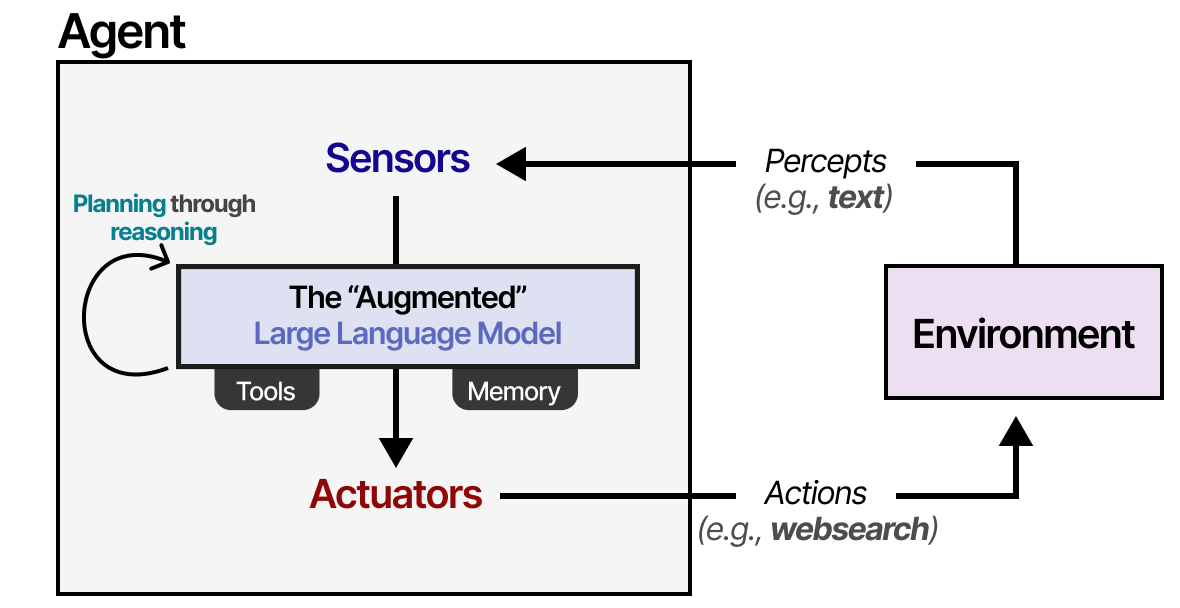
En utilisant le « LLM augmenté », l’agent peut observer l’environnement par le biais d’entrées textuelles (les LLM étant généralement des modèles textuels) et effectuer certaines actions grâce à l’utilisation d’outils (comme la recherche sur internet).
Pour choisir les actions à entreprendre, l’agent basé sur un LLM dispose d’un élément vital : sa capacité à planifier. Pour cela, les LLM doivent être capables de « raisonner » grâce à des méthodes telles que la chaîne de pensée.
Pour plus d’informations sur le raisonnement, consultez le Guide visuel sur les LLM avec raisonnement.
En utilisant ce mécanisme, les agents vont planifier les actions nécessaires à entreprendre.

Ce comportement permet à l’agent de comprendre la situation (LLM), de planifier les prochaines étapes (planification), de prendre des actions (outils) et de garder une trace des actions prises (mémoire).
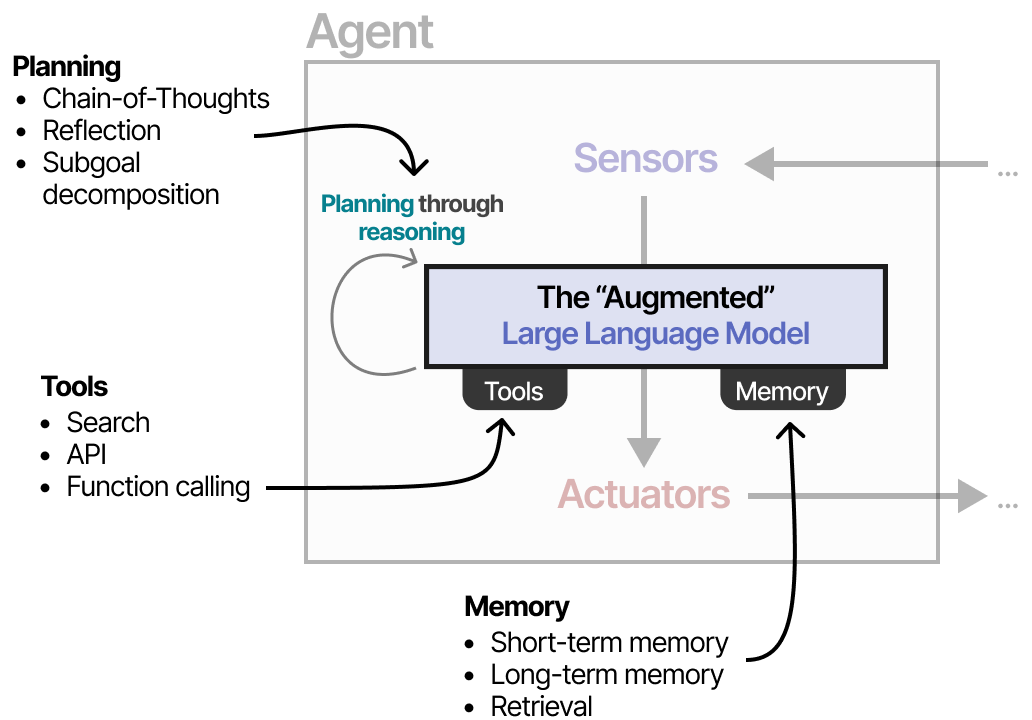
Selon le système, il est possible de laisser aux agents plus ou moins d’autonomie.
Selon les personnes interrogées, un système est d’autant plus « agentique » que le LLM décide de la manière dont le système peut se comporter.
Dans les sections suivantes, nous passerons en revue différentes méthodes de comportement autonome à travers les trois composants principaux de l’agent LLM : Mémoire, Outils et Planification.
Mémoire
Les LLM sont des systèmes oubliant ou, plus précisément, qui n’effectuent aucune mémorisation lorsqu’on interagissent avec eux. Par exemple, si vous posez une question à un LLM et que vous la faites suivre d’une autre question, il ne se souviendra pas de la première.
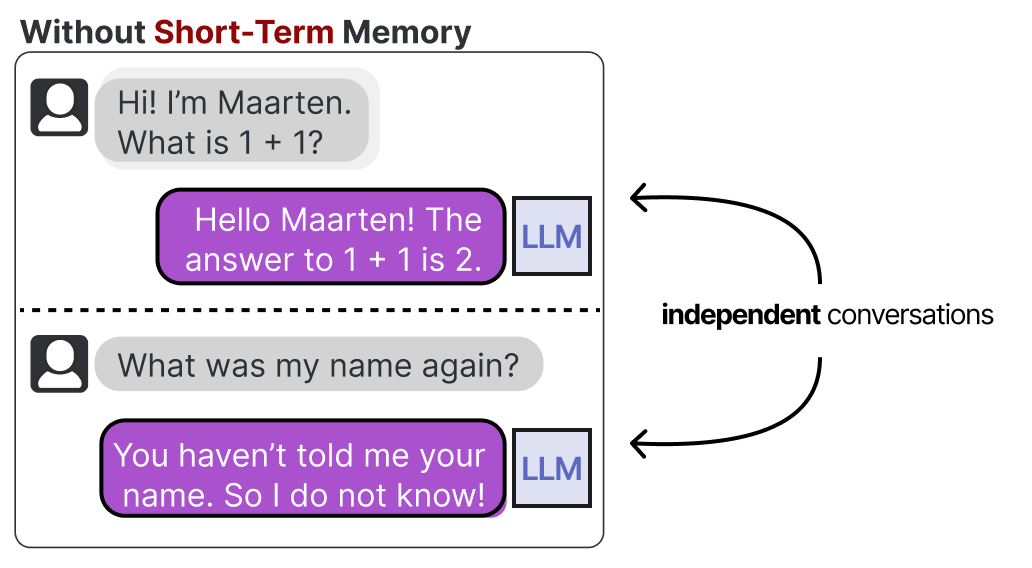
Il s’agit généralement de la mémoire à court terme, également appelée mémoire de travail, qui sert de mémoire tampon pour le contexte (quasi) immédiat. Cela inclut les actions récentes entreprises par l’agent. Cependant, l’agent doit également garder la trace de dizaines d’étapes potentielles, et pas seulement des actions les plus récentes.
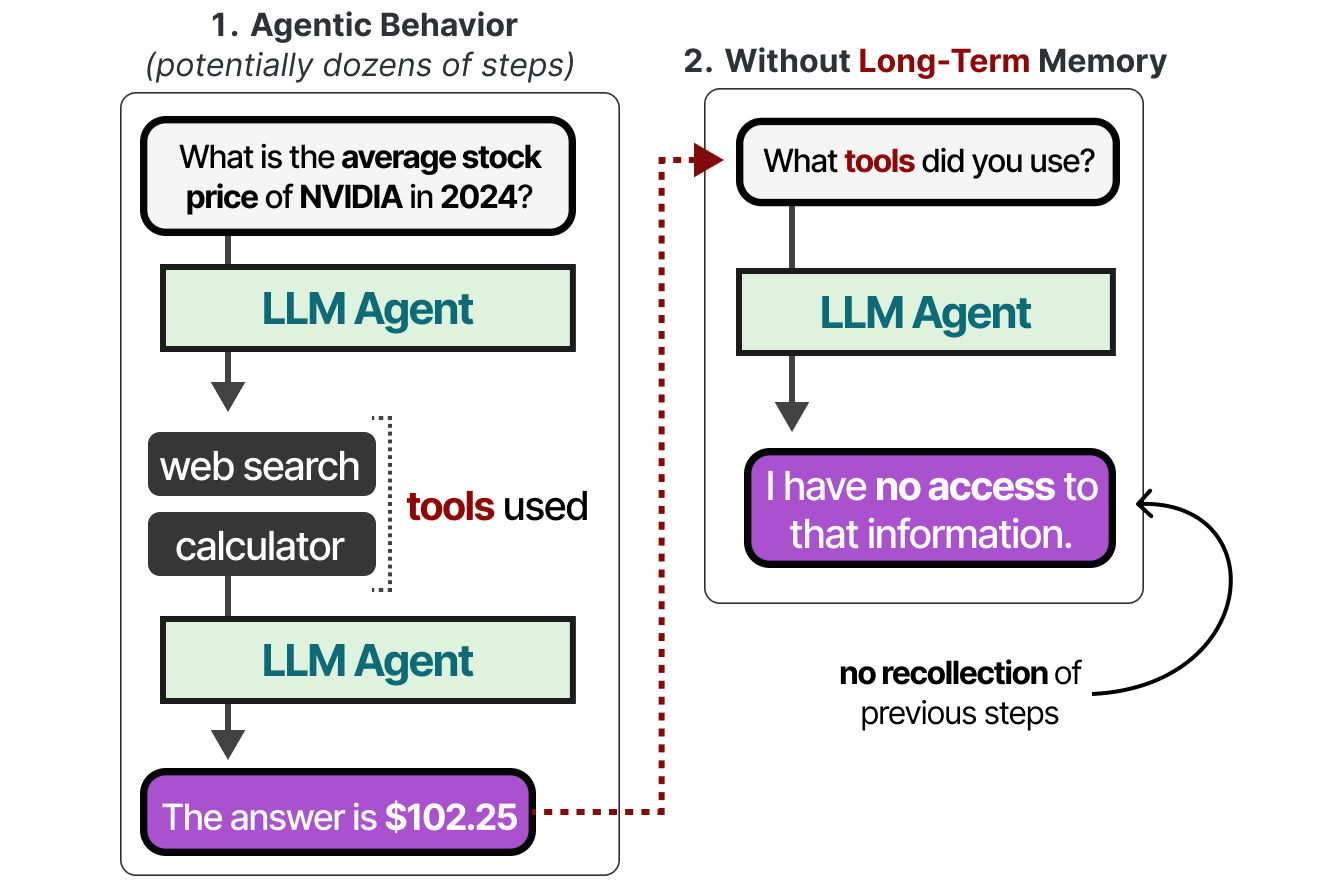
C’est ce qu’on appelle la mémoire à long terme, car l’agent peut théoriquement suivre des dizaines, voire des centaines d’étapes qui doivent être mémorisées.

Explorons quelques astuces pour fournir de la mémoire à ces modèles.
Mémoire à court terme
La méthode la plus simple pour activer la mémoire à court terme consiste à utiliser la fenêtre contextuelle du modèle, qui est essentiellement le nombre de tokens qu’un LLM peut traiter.
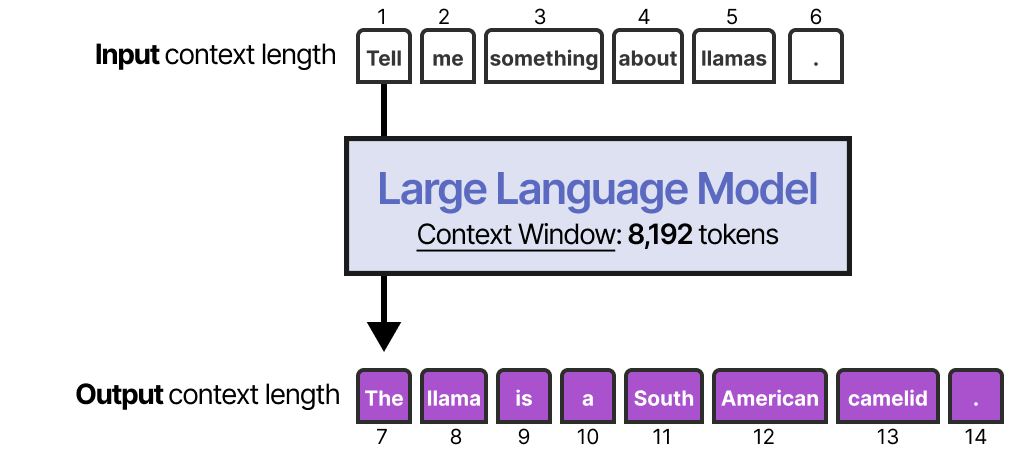
La fenêtre contextuelle contient généralement au moins 8192 tokens et peut parfois atteindre des centaines de milliers de tokens ! Une grande fenêtre contextuelle peut être utilisée pour suivre l’historique complet de la conversation dans chaque nouveau prompt.
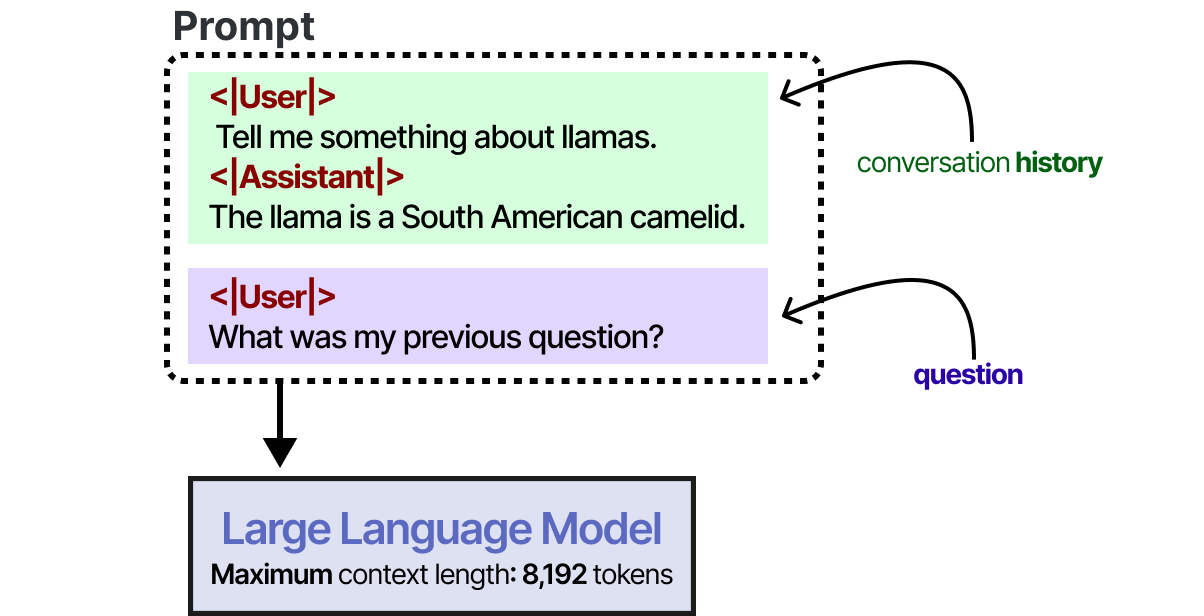
Cela fonctionne tant que l’historique de la conversation s’inscrit dans la fenêtre contextuelle du LLM et constitue une bonne façon d’imiter la mémoire. Cependant, au lieu de mémoriser une conversation, nous disons essentiellement au LLM quelle était cette conversation. Pour les modèles avec une fenêtre de contexte plus petite, ou lorsque l’historique des conversations est important, nous pouvons utiliser un autre LLM pour résumer les conversations qui ont eu lieu jusqu’à présent.
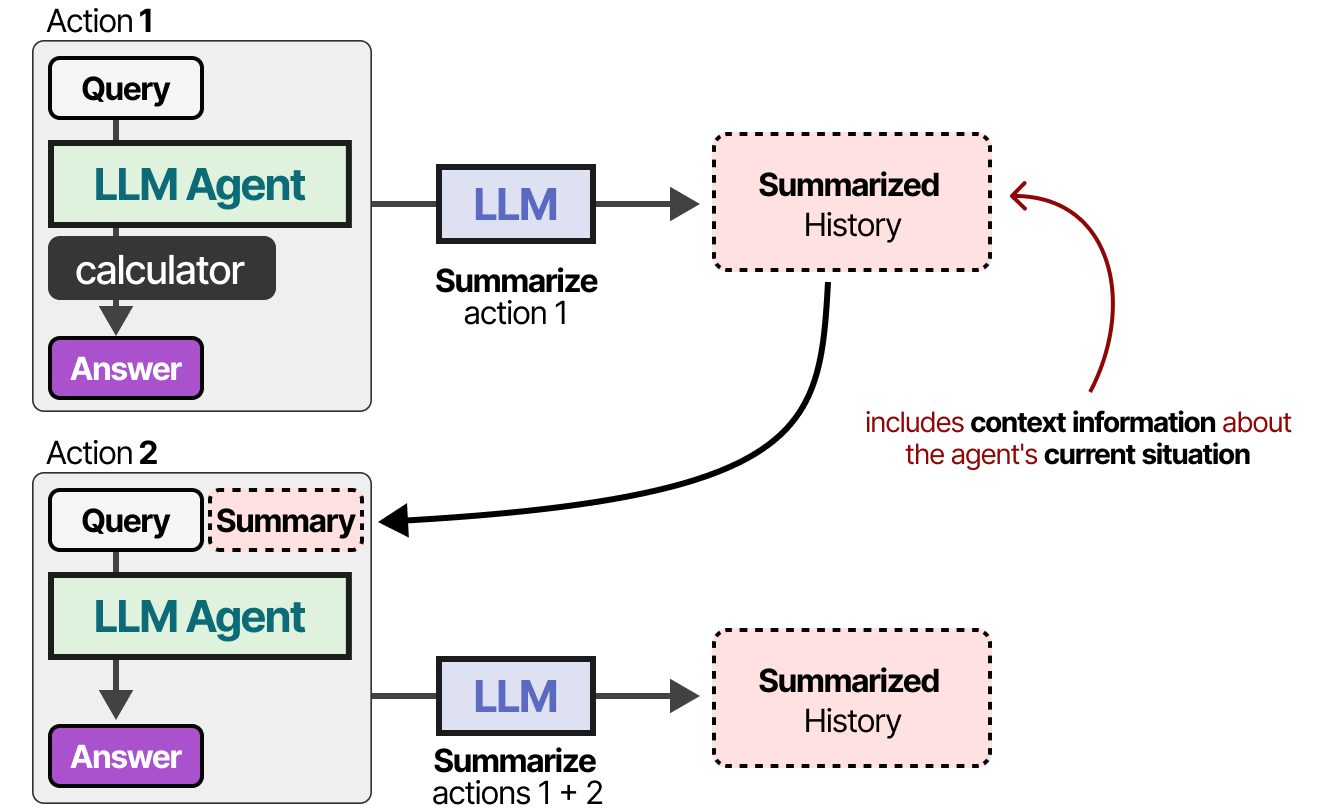
En résumant continuellement les conversations, nous pouvons en limiter la taille. Cela permet de réduire le nombre de tokens tout en ne conservant que les informations les plus importantes.
Mémoire à long terme
La mémoire à long terme des agents comprend l’espace d’action passé de l’agent qui doit être conservé sur une longue période. Une technique courante pour activer la mémoire à long terme consiste à stocker toutes les interactions, actions et conversations antérieures dans une base de données vectorielle externe. Pour construire une telle base de données, les conversations sont d’abord vectorisées par un modèle pour en capturer leur sens.
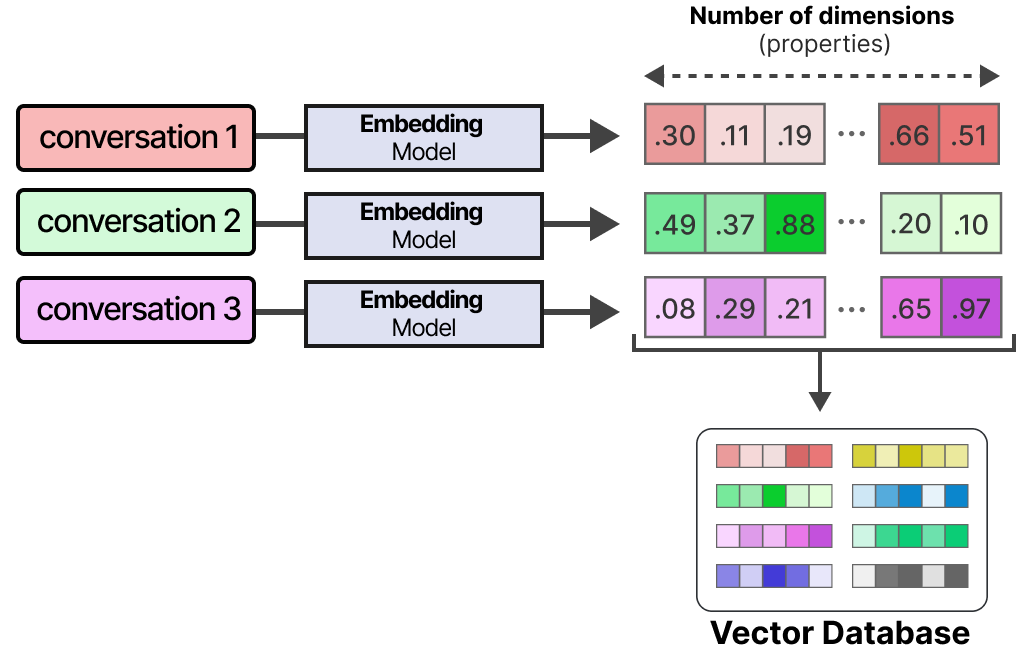
Après avoir constitué la base de données, nous pouvons vectoriser un prompt donné et trouver les informations les plus pertinentes dans la base de données vectorielle en comparant le vecteur du prompts avec ceux contenus dans la base de données.
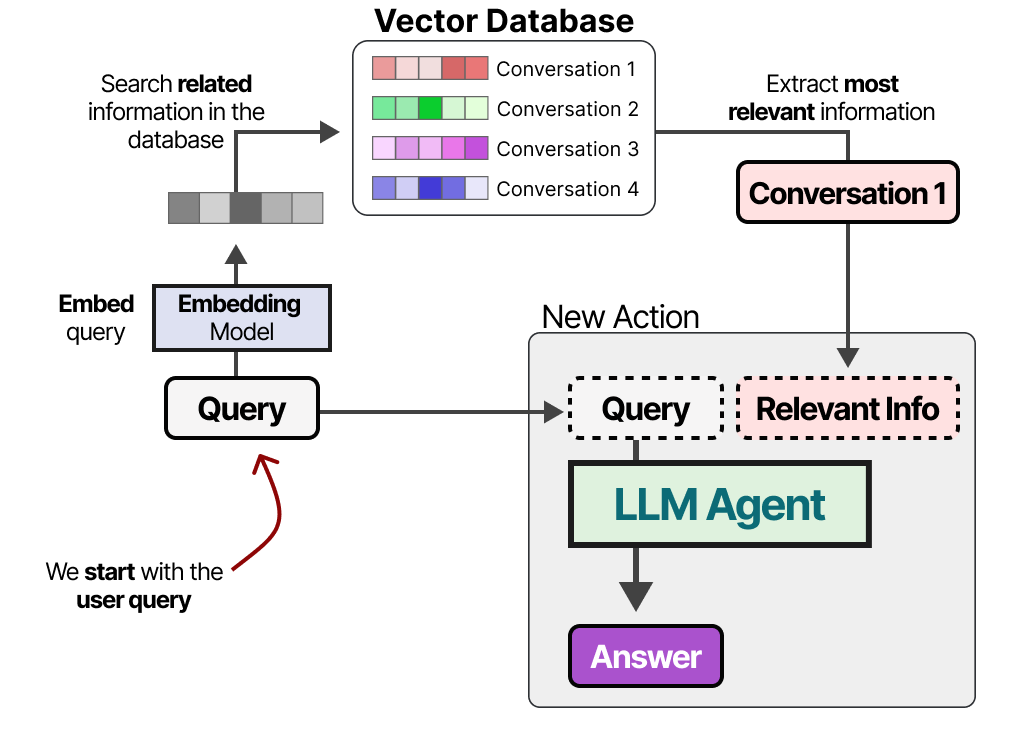
Cette méthode est souvent désignée sous le nom de Retrieval-Augmented Generation (RAG). La mémoire à long terme peut également impliquer la conservation d’informations provenant de différentes sessions. Par exemple, vous pouvez souhaiter qu’un agent se souvienne des recherches qu’il a effectuées au cours des sessions précédentes. Les différents types d’informations peuvent également être liés à différents types de mémoire à stocker. En psychologie, il existe de nombreux types de mémoire. Le papier Cognitive Architectures for Language Agents de Sumers, Yao et al. (2023) en distingue quatre pour les agents :

Cette différenciation aide à construire des cadres agentiques. La mémoire sémantique (faits concernant le monde) peut être stockée dans une base de données différente de la mémoire de travail (circonstances actuelles et récentes).
Outils
Les outils permettent à un LLM d’interagir avec un environnement externe (comme les bases de données) ou d’utiliser des applications externes (comme un code personnalisé à exécuter).

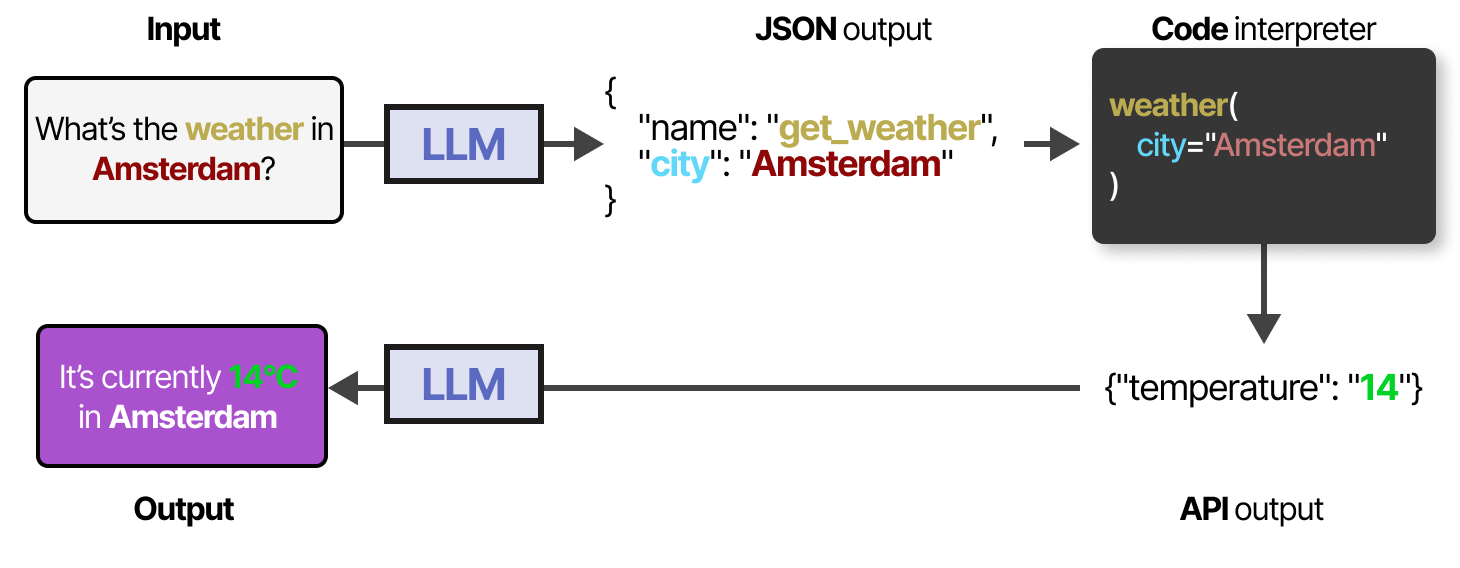
Les outils ont généralement deux cas d’utilisation : la recherche de données pour obtenir des informations actualisées et l’exécution d’actions telles que l’organisation d’une réunion ou la commande d’un repas. Pour utiliser un outil, le LLM doit générer un texte qui correspond à l’API de l’outil en question. Usuellement, nous attendons à des sorties qui peuvent être formatées en JSON afin qu’elles puissent facilement être transmises à un interpréteur de code.
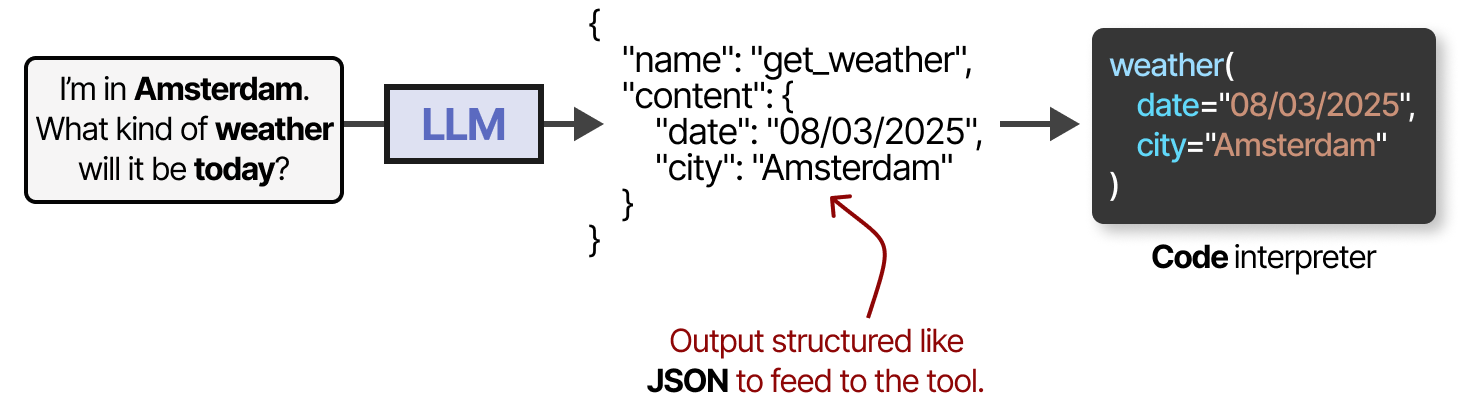
Notez que cela n’est pas limité à du JSON, nous pouvons également appeler l’outil dans le code lui-même ! Vous pouvez également générer des fonctions personnalisées que le LLM peut utiliser, comme une fonction de multiplication de base. C’est ce qu’on appelle souvent l’appel de fonction.

Certains LLM peuvent utiliser n’importe quel outil s’ils sont promptés à le faire correctement et de manière approfondie. L’utilisation d’outils est une chose dont la plupart des LLM actuels sont capables.
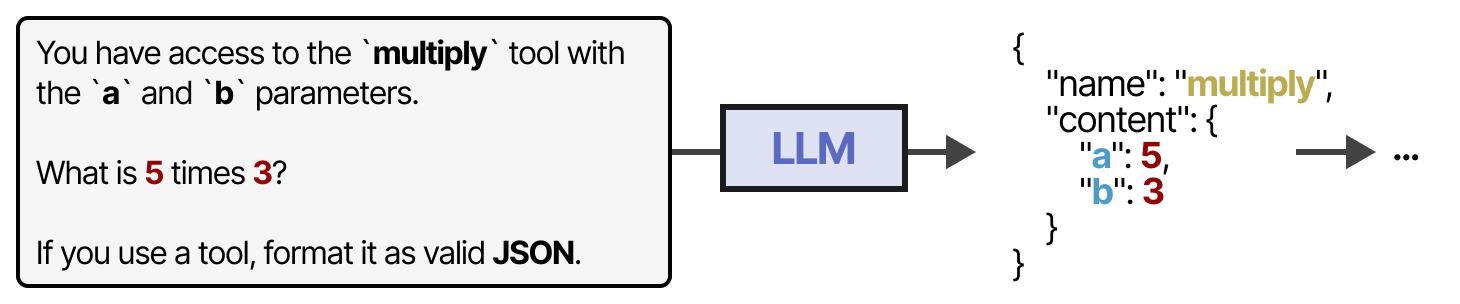
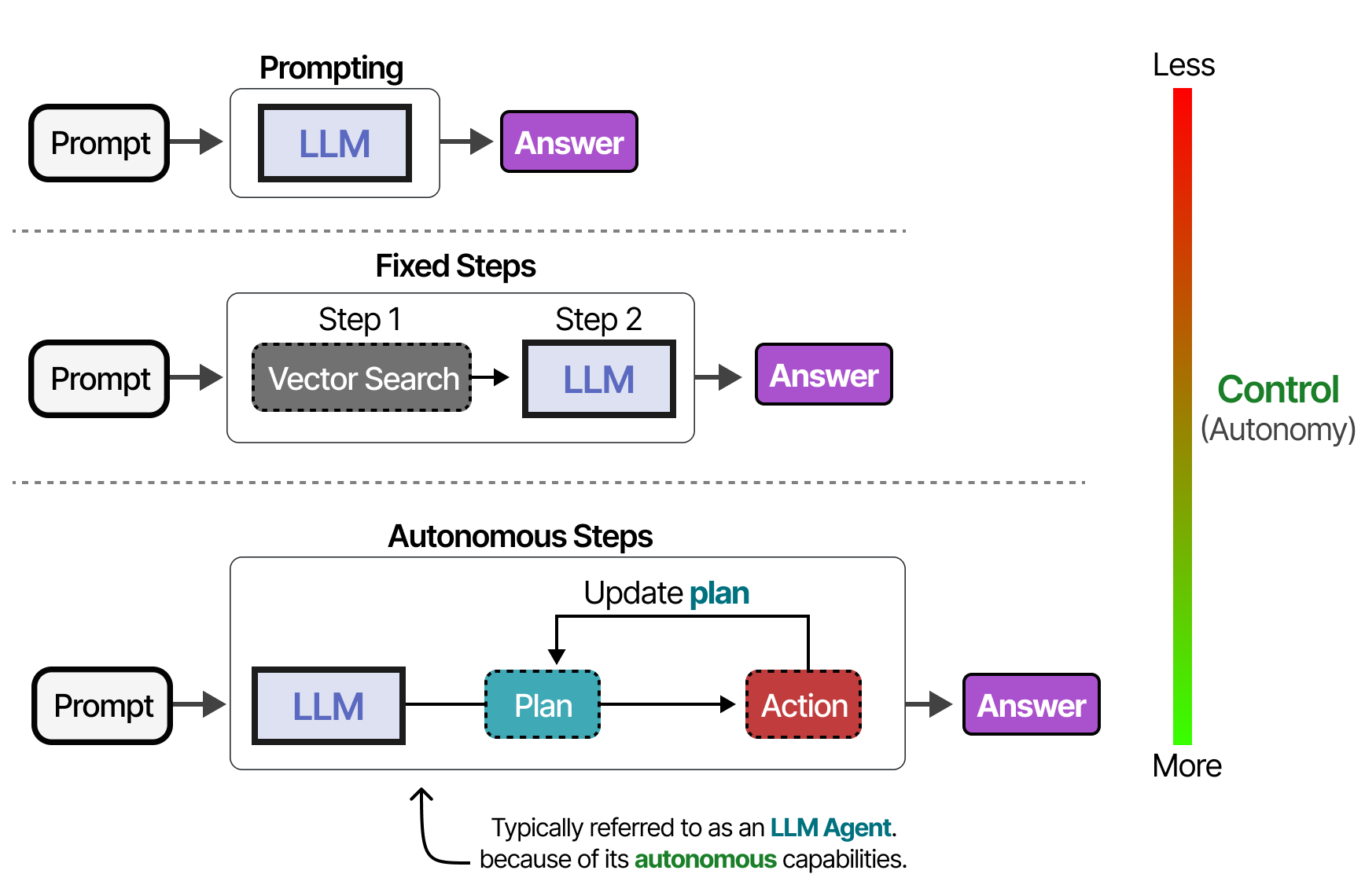
Une méthode plus stable pour accéder aux outils consiste à finetuner le LLM (nous y reviendrons plus tard). Les outils peuvent être utilisés dans un ordre donné si le cadre agentique est fixe…
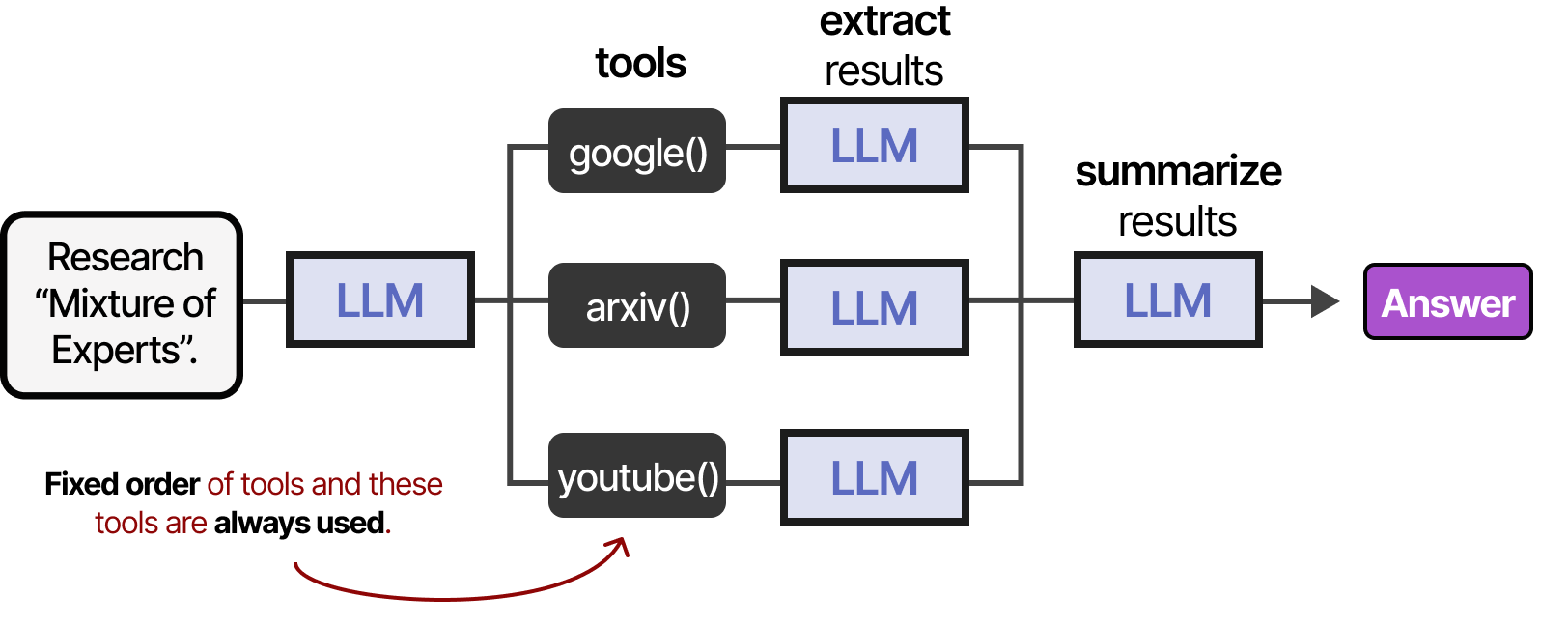
…ou le LLM peut choisir de manière autonome quel outil utiliser et à quel moment. Les agents, comme l’image ci-dessus, sont essentiellement des séquences d’appels de LLM (mais avec une sélection autonome des actions/outils/etc.).
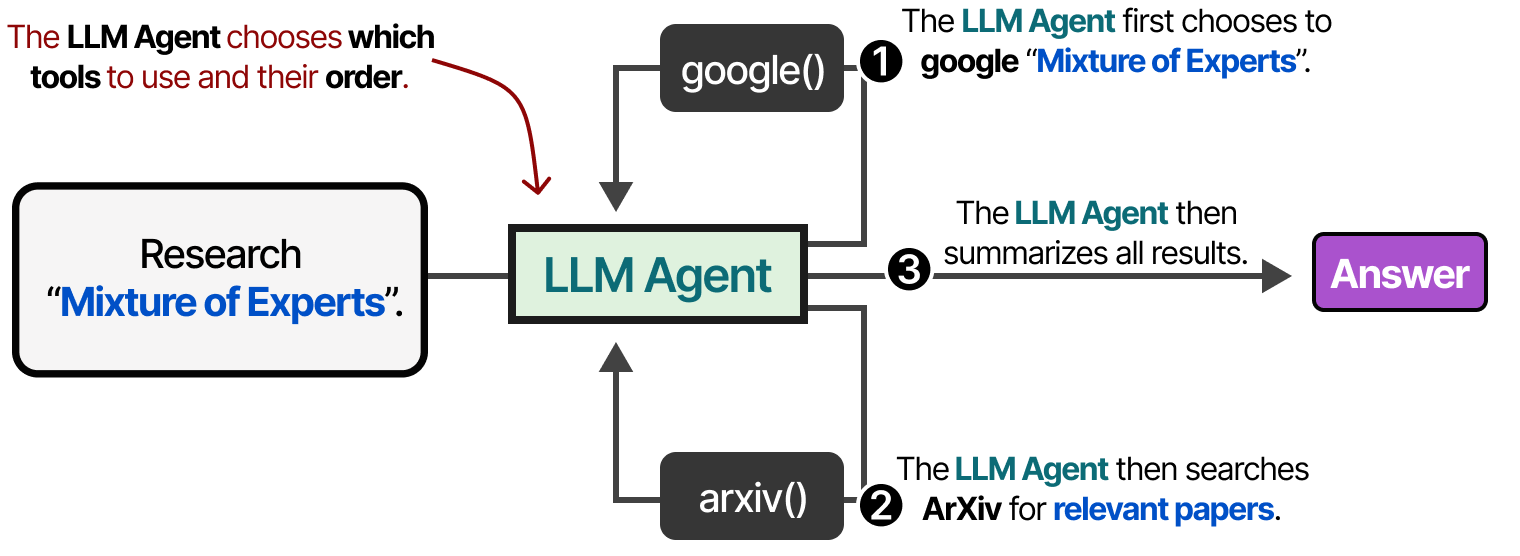
En d’autres termes, la sortie des étapes intermédiaires est réinjectée dans le LLM pour poursuivre le traitement.
Toolformer
L’utilisation d’outils est une technique puissante pour renforcer les capacités des LLM et compenser leurs désavantages. C’est pourquoi les recherches sur l’utilisation d’outils et l’apprentissage ont connu un essor rapide ces dernières années.
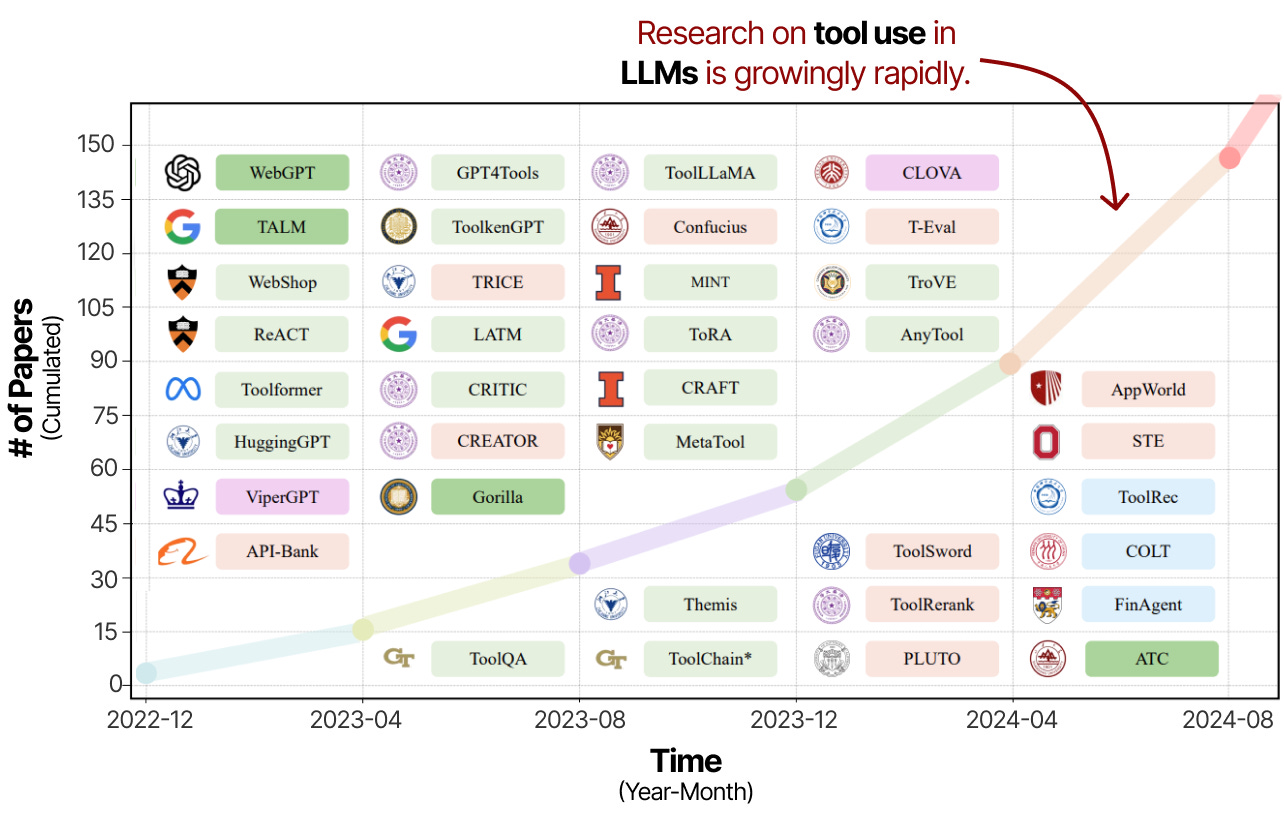
Une grande partie de cette recherche consiste non seulement à inciter les LLM à utiliser des outils, mais aussi à les entraîner spécifiquement à l’utilisation d’outils.
L’une des premières techniques à le faire s’appelle Toolformer par Schick et al. (2023), un modèle entraîné à décider quelles API appeler et comment.
Pour ce faire, il utilise les tokens [ et ] pour indiquer le début et la fin de l’appel à un outil. Lorsqu’il reçoit une instruction, par exemple « Que vaut 5 fois 3 ? », le modèle commence à générer des tokens jusqu’à ce qu’il atteigne le celui [.

Ensuite, il génère des tokens jusqu’à ce qu’il atteigne le token → qui indique que le LLM doit arrêter sa génération pour appeler un outil.

Ensuite, le résultat de l’utilisation de l’outil est ajouté aux tokens générés jusqu’à présent.
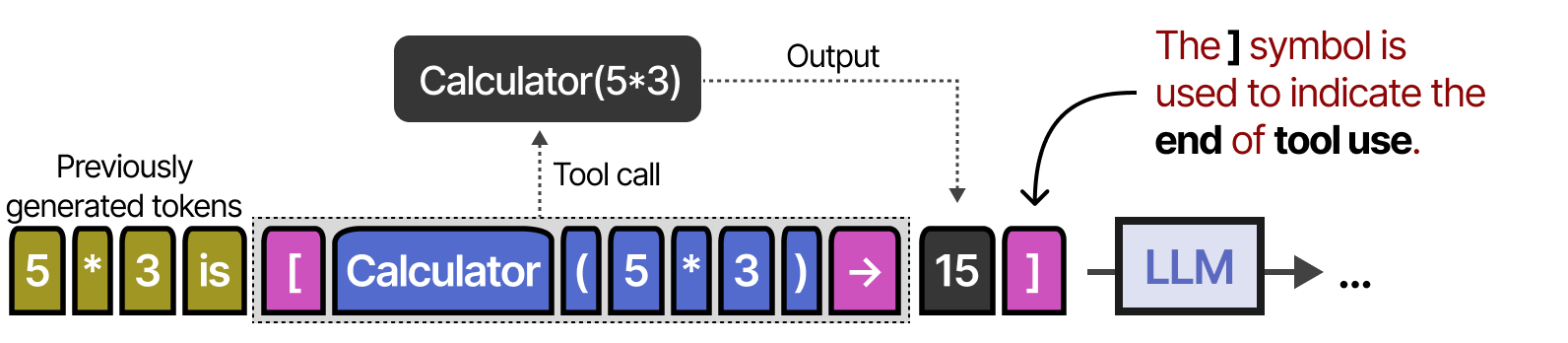
Le symbole ] indique que le LLM peut maintenant continuer à générer si nécessaire.
Toolformer crée ce comportement en générant un jeu de données via de nombreuses utilisations d’outils sur lesquels le modèle a été entraîné. Pour chaque outil, une instruction avec quelques exemples est créée manuellement et utilisée pour échantillonner les sorties utilisant ces outils.
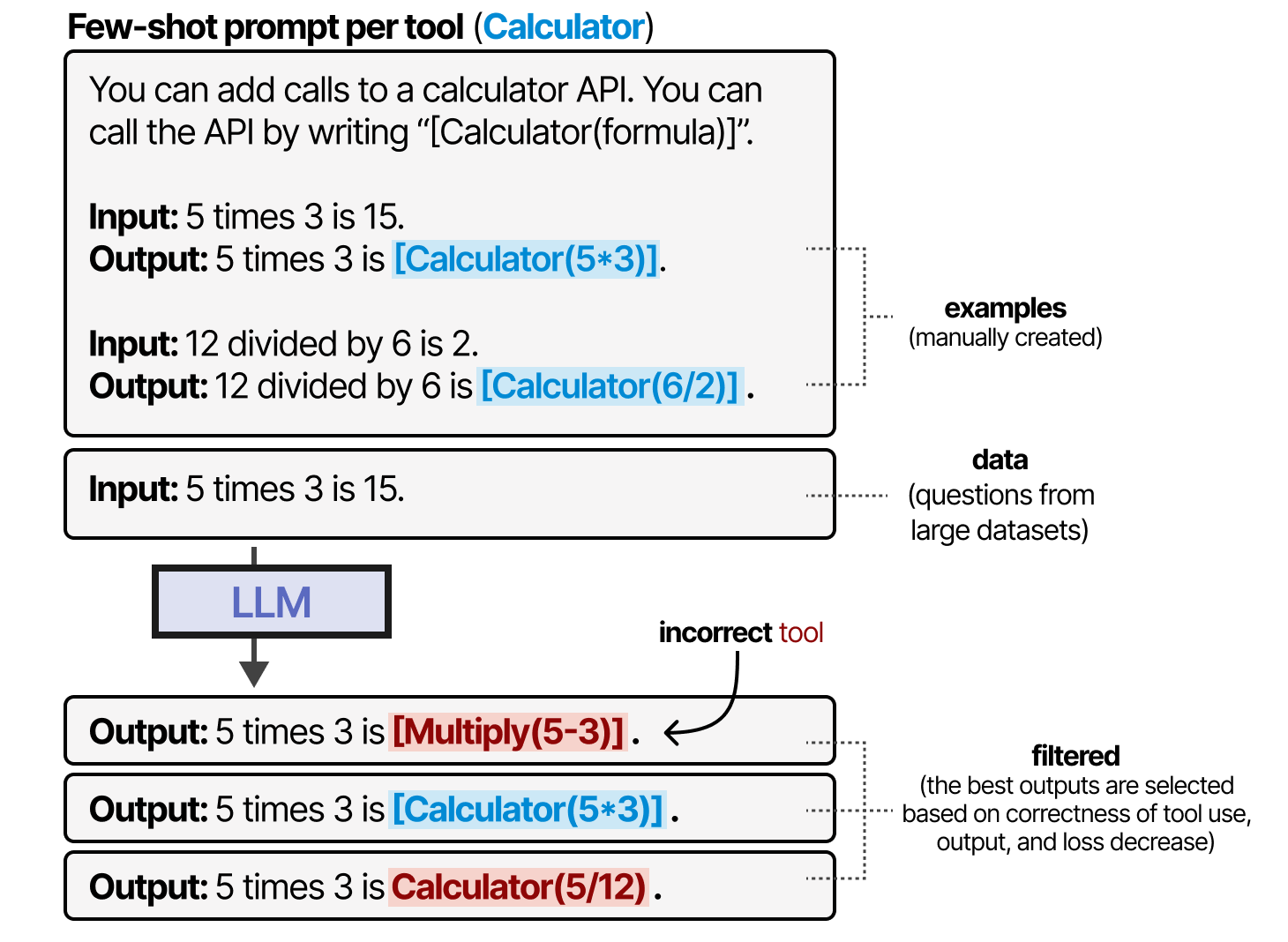
Les sorties sont ensuite filtrées en fonction de l’exactitude de l’utilisation de l’outil, de la sortie, et de la diminution de la perte. Le jeu de données résultant est utilisé pour entraîner un LLM à adhérer à ce format d’utilisation d’outil.
Depuis la publication de Toolformer, de nombreuses techniques intéressantes ont vu le jour, telles que les LLM pouvant utiliser des milliers d’outils comme ToolLLM de Qin, Liang et al. (2023) ou les LLM pouvant facilement récupérer les outils les plus pertinents comme Gorilla de Patil, Zhang et al. (2023).
Quoi qu’il en soit, la plupart des LLM actuels (début 2025) ont été entraînés pour appeler facilement des outils par le biais de la génération JSON (comme nous l’avons vu précédemment).
Model Context Protocol (MCP)
Les outils sont une composante importante des cadres agentiques. Cependant, permettre leur utilisation basée sur de nombreuses API différentes devient problématique car tout outil doit être :
- Suivi manuellement et donné au LLM
- Décris manuellement (y compris le schéma JSON attendu)
- Mise à jour manuellement à chaque modification de l’API

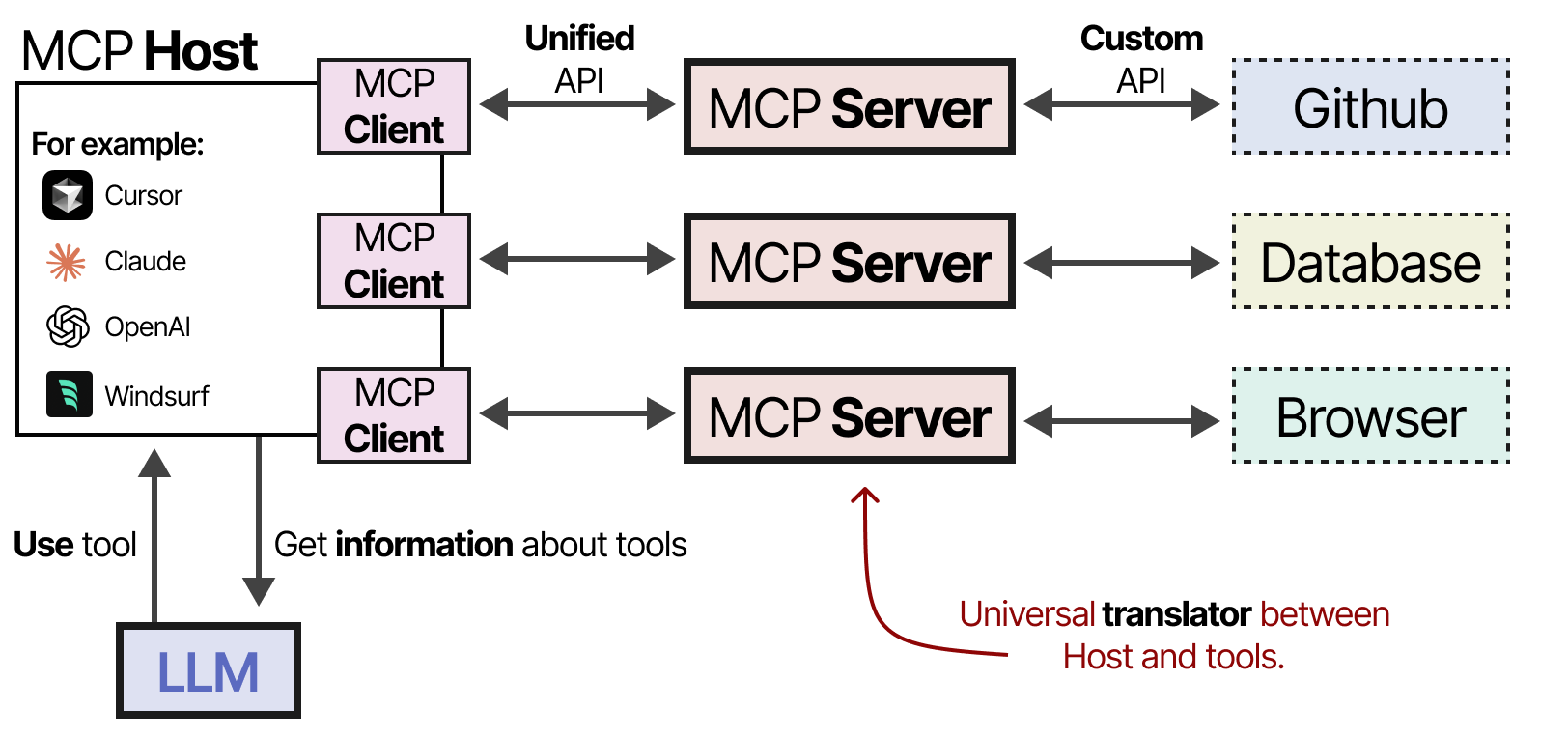
Pour faciliter l’implémentation d’outils dans un cadre agentique donné, Anthropic a développé le Model Context Protocol (MCP). Ce protocole standardise l’accès aux API pour des services tels que les applications météorologiques et GitHub. Il se compose de trois éléments :
- Hôte : une application LLM (par exemple Cursor) qui gère les connexions
- Client : maintient des connexions 1:1 avec les serveurs MCP
- Serveur : fournit le contexte, les outils et les capacités aux LLM
Par exemple, supposons que vous souhaitiez qu’une application LLM donnée résume les 5 derniers commits de votre dépôt. L’hôte MCP (ainsi que le client) appelle d’abord le serveur MCP pour demander quels sont les outils disponibles.

Le LLM reçoit les informations et peut choisir d’utiliser un outil. Il envoie une demande au serveur MCP via l’hôte, puis reçoit les résultats, y compris l’outil utilisé.
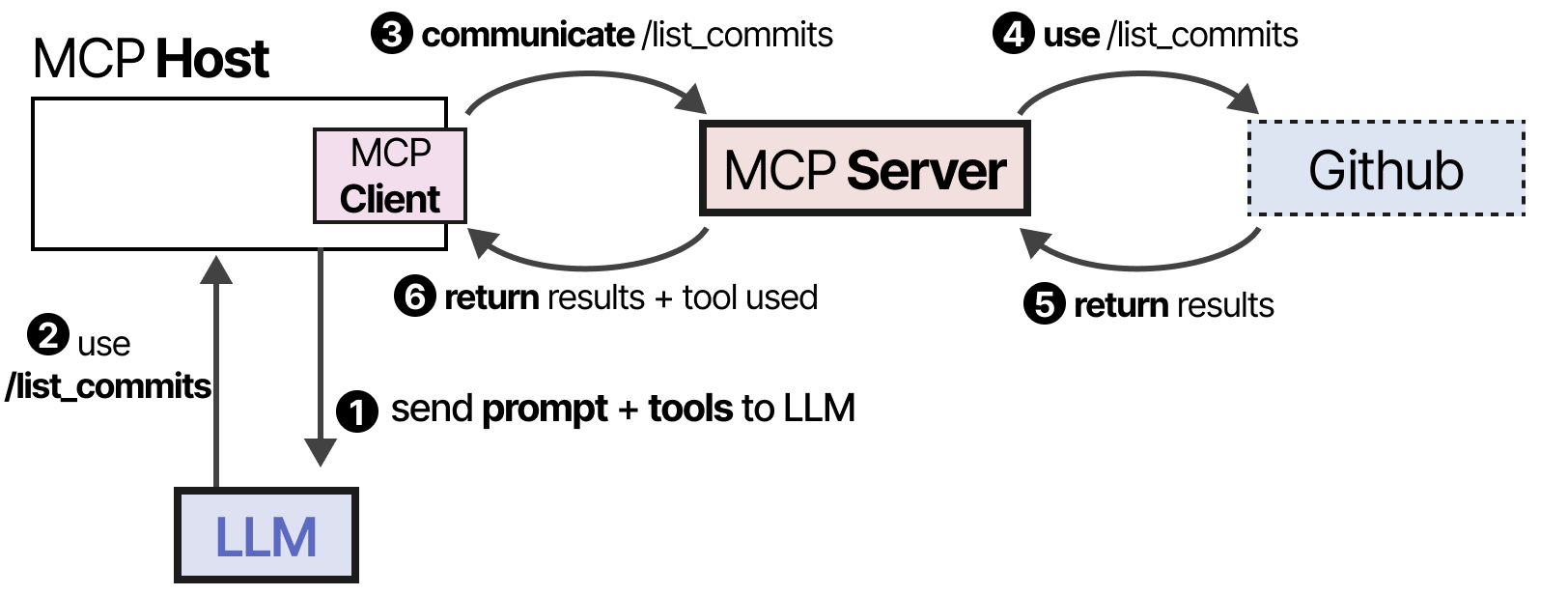
Enfin, le LLM reçoit les résultats et peut analyser une réponse à l’utilisateur.

Ce cadre facilite la création d’outils en se connectant aux serveurs MCP que toute application LLM peut utiliser. Ainsi, lorsque vous créez un serveur MCP pour interagir avec Github, toute application LLM supportant MCP peut l’utiliser.
Planification
Les outils sont généralement appelés à l’aide de requêtes de type JSON. Mais comment le LLM, dans un système agentique, décide-t-il quel outil utiliser et à quel moment ? C’est là qu’intervient la planification. Dans le cas des agents, la planification consiste à diviser une tâche donnée en étapes actionnables.
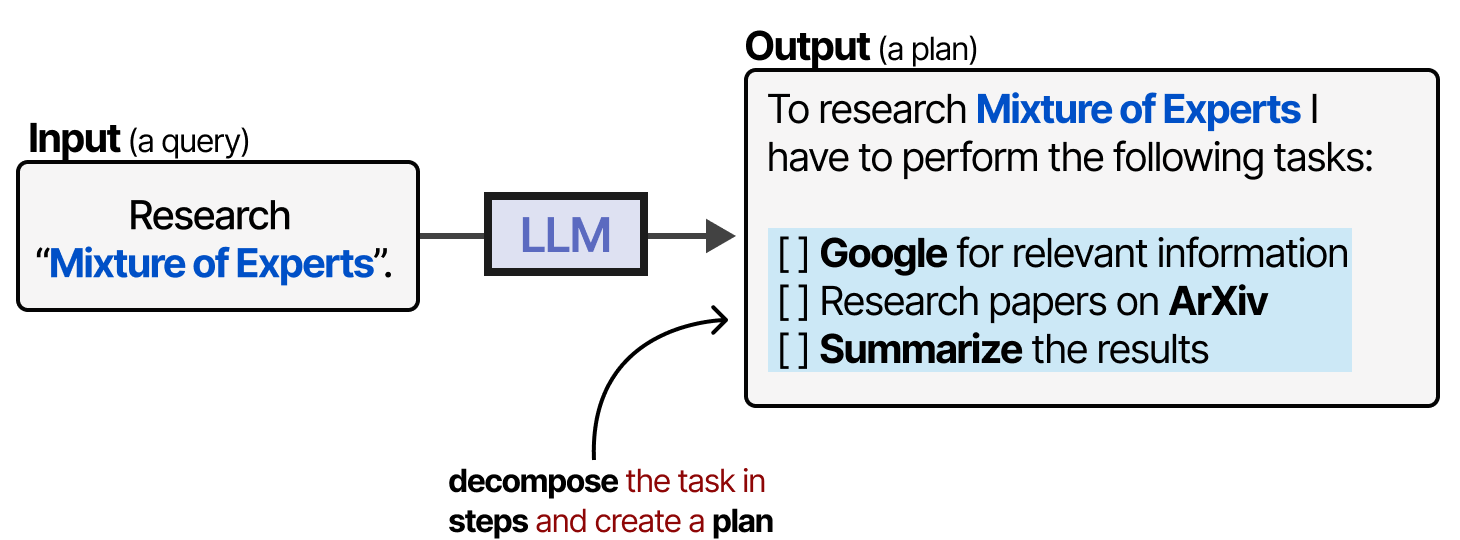
Ce plan permet au modèle de réfléchir de manière itérative au comportement passé et de mettre à jour le plan actuel si nécessaire.

Pour réaliser cette planification, examinons d’abord la base de cette technique, à savoir le raisonnement.
Raisonnement
La planification d’étapes actionnables nécessite un raisonnement complexe. Le LLM doit être en mesure de détailler les étapes avant de passer à l’étape suivante.
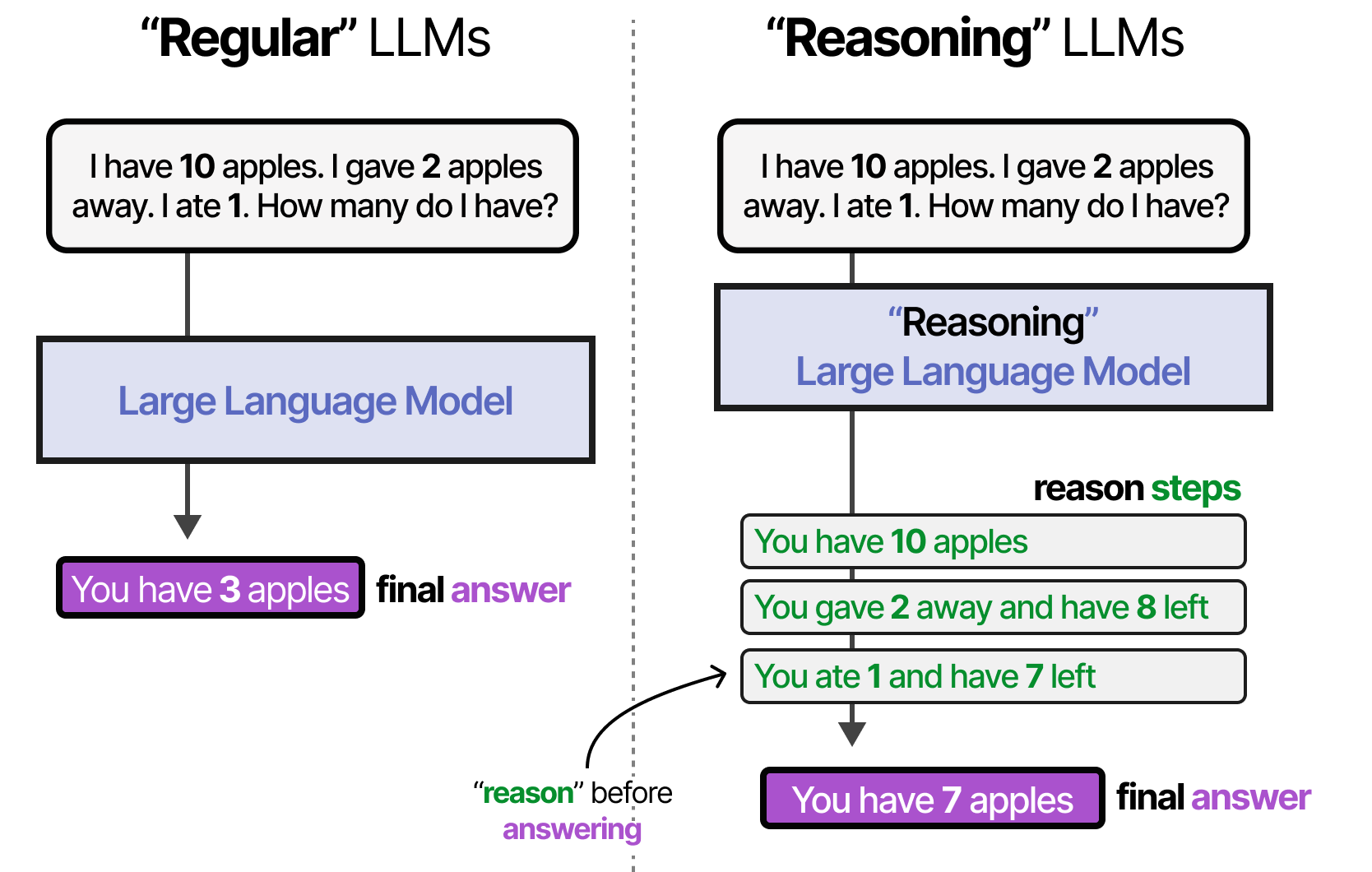
Le comportement de raisonnement peut être activé de deux manières : via un finetuning du LLM ou via du prompt engineering spécifique. Via les prompts, nous pouvons créer des exemples du processus de raisonnement que le LLM doit suivre. La fourniture d’exemples (également appelée few-shot) est une excellente méthode pour orienter le comportement du LLM.
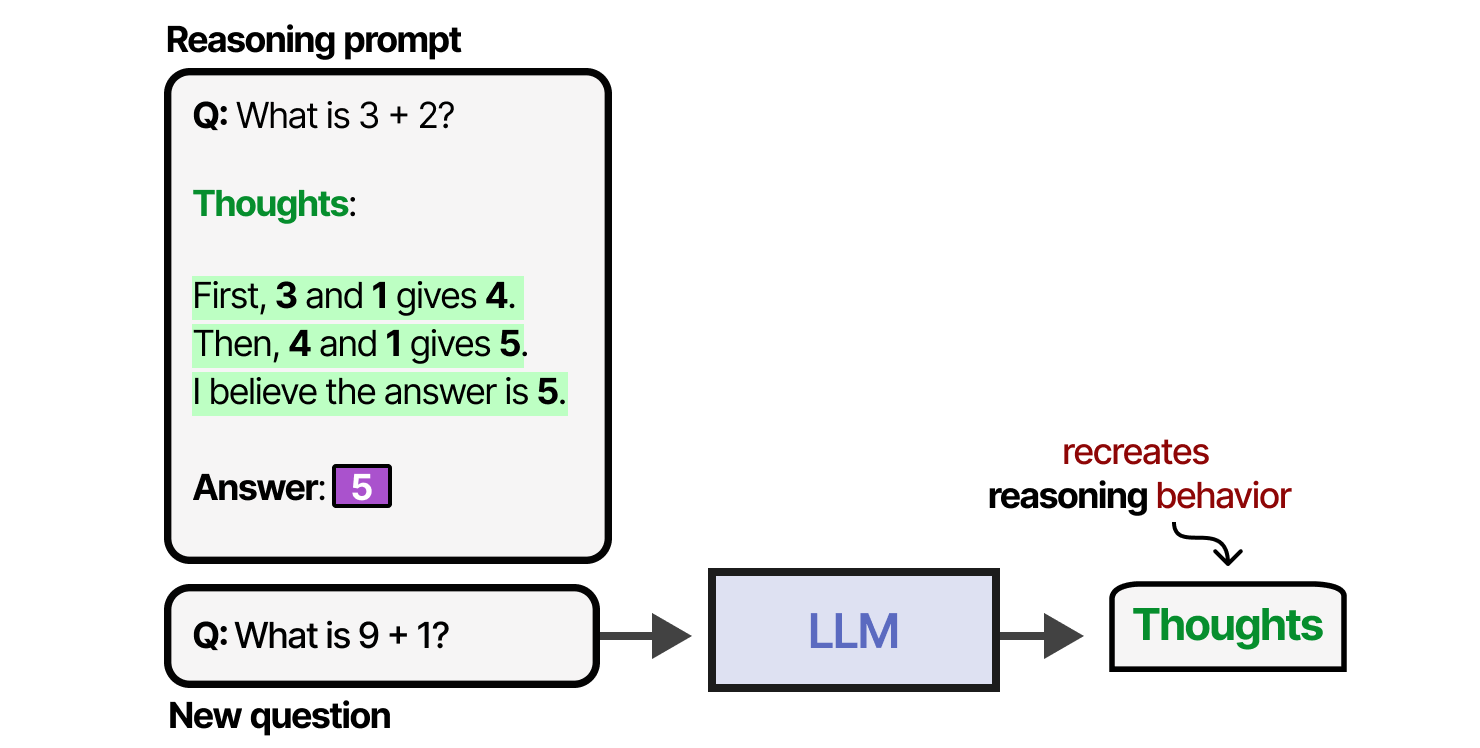
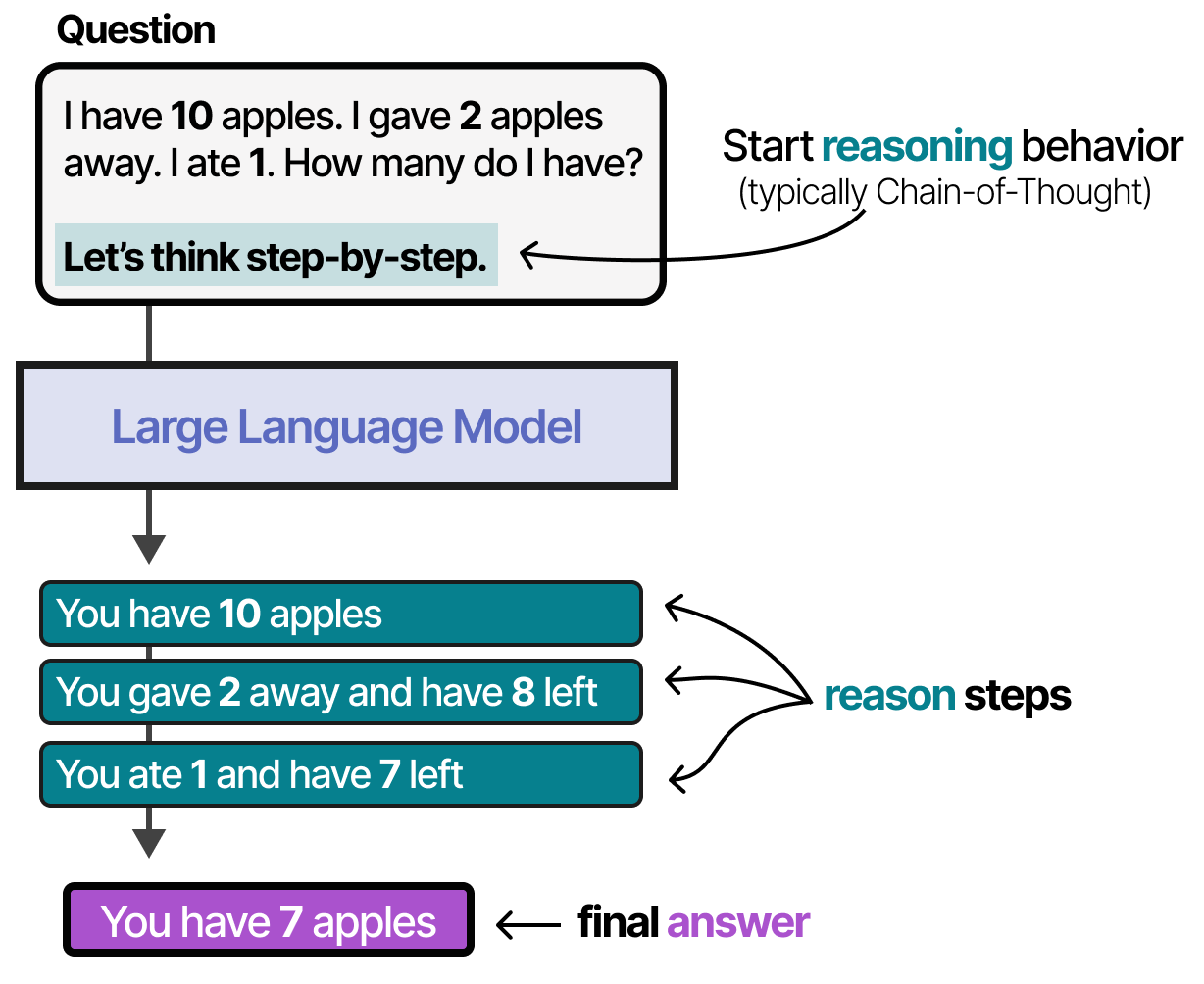
Cette méthodologie consistant à fournir des exemples de processus de pensée est appelée chaîne de pensée (Wei et al. (2022)) et permet un comportement de raisonnement plus complexe. La chaîne de pensée peut également être activée sans aucun exemple (0-shot) en disant simplement « Réfléchissons étape par étape » (Kojima et al. (2022)).

Lors de l’entraînement d’un LLM, nous pouvons soit lui donner une quantité suffisante de données qui incluent des exemples de réflexion, soit le LLM peut découvrir son propre processus de réflexion. Un bon exemple est DeepSeek-R1 où les récompenses sont utilisées pour guider l’utilisation des processus de réflexion.
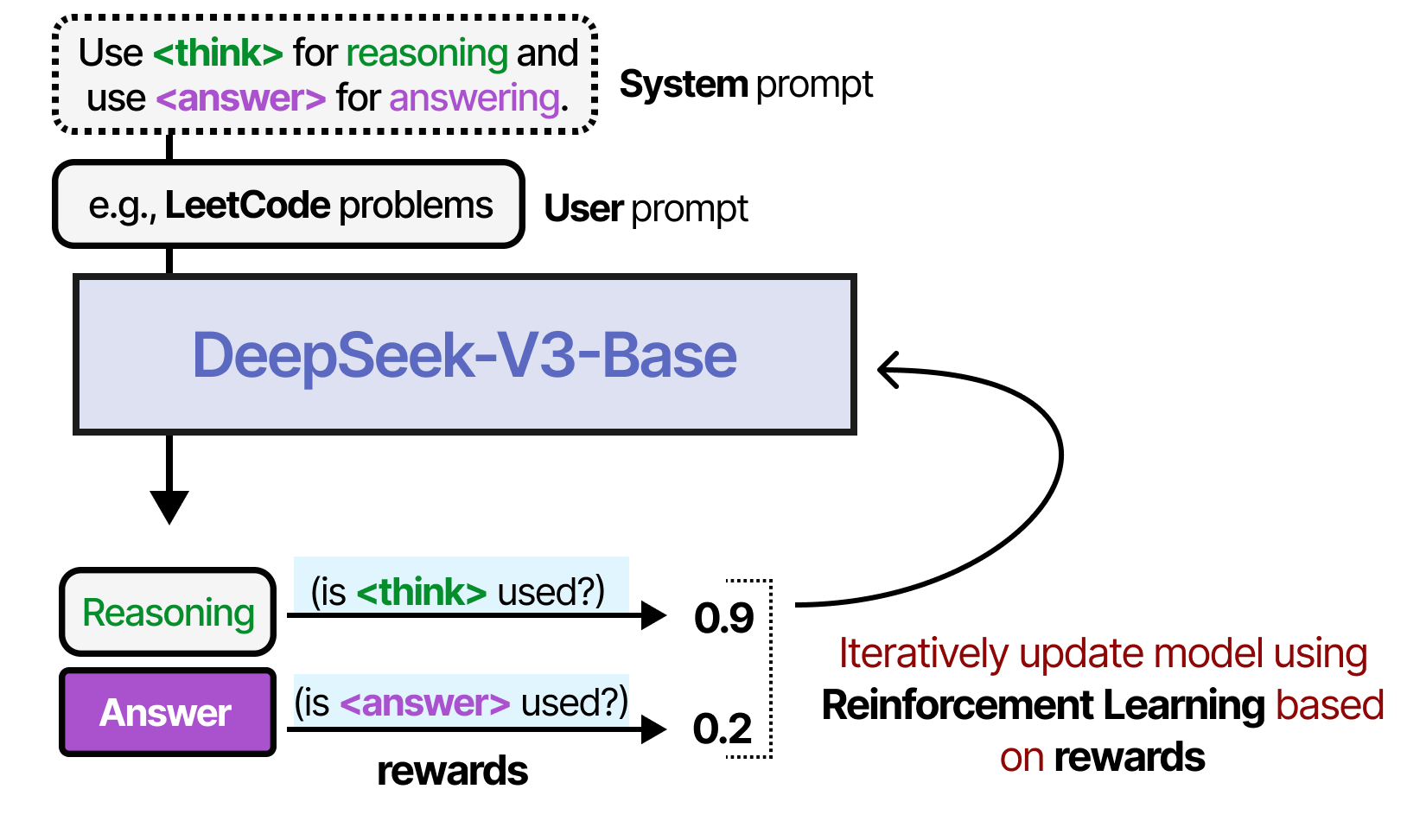
Pour plus d’informations sur les LLM avec raisonnement, consultez l’article de blog sur le sujet.
Raisonner et agir
Permettre un comportement de raisonnement dans les LLM est une bonne chose, mais cela ne les rend pas nécessairement capables de planifier des actions réalisables. Les techniques listées jusqu’à présent présentent un comportement de raisonnement ou interagissent avec l’environnement par le biais d’outils.
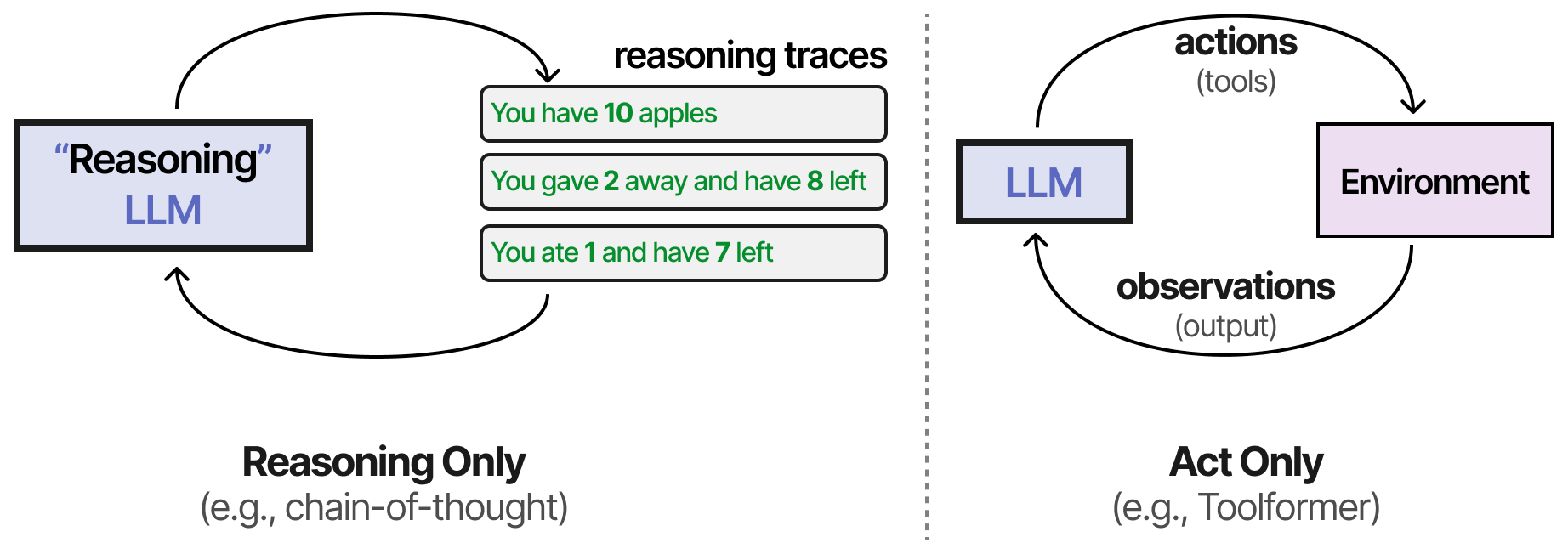
L’une des premières techniques à combiner les deux processus est appelée ReAct (Reason and Act) (Yao et al. (2022)).
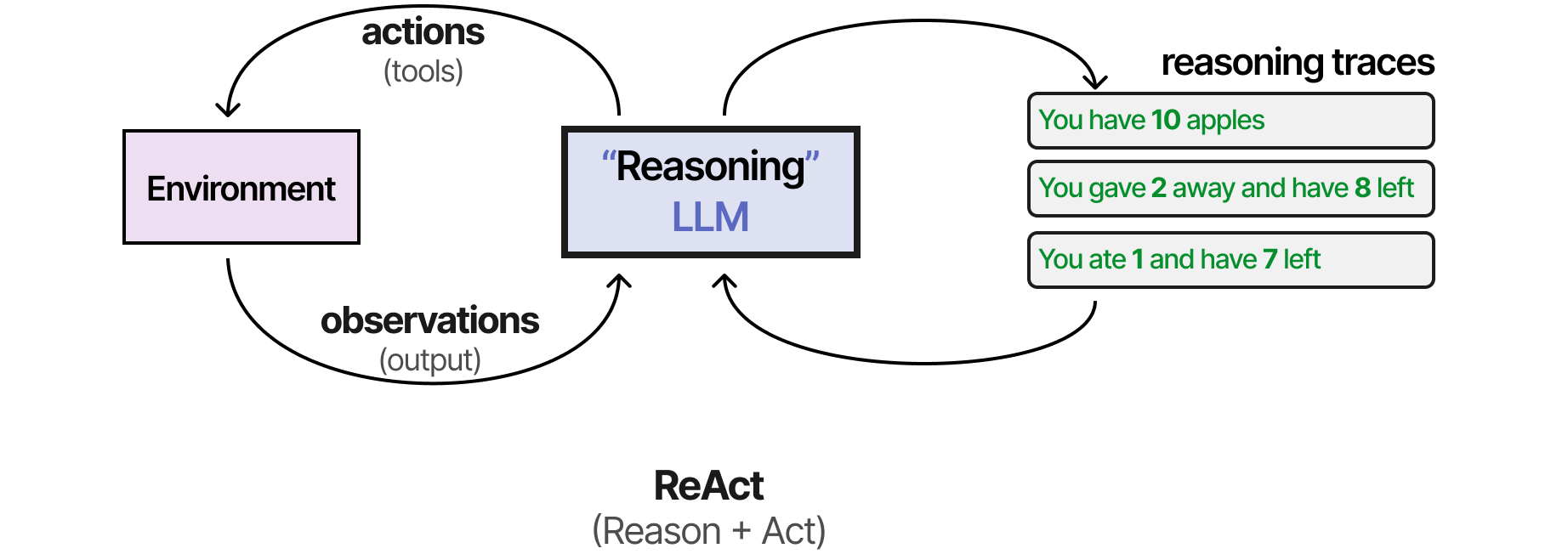
ReAct se base notamment sur une conception minutieuse du prompt qui décrit trois étapes :
- Réflexion : une étape de raisonnement sur la situation actuelle
- Action : un ensemble d’actions à exécuter (par exemple, des outils)
- Observation : une étape de raisonnement sur le résultat de l’action
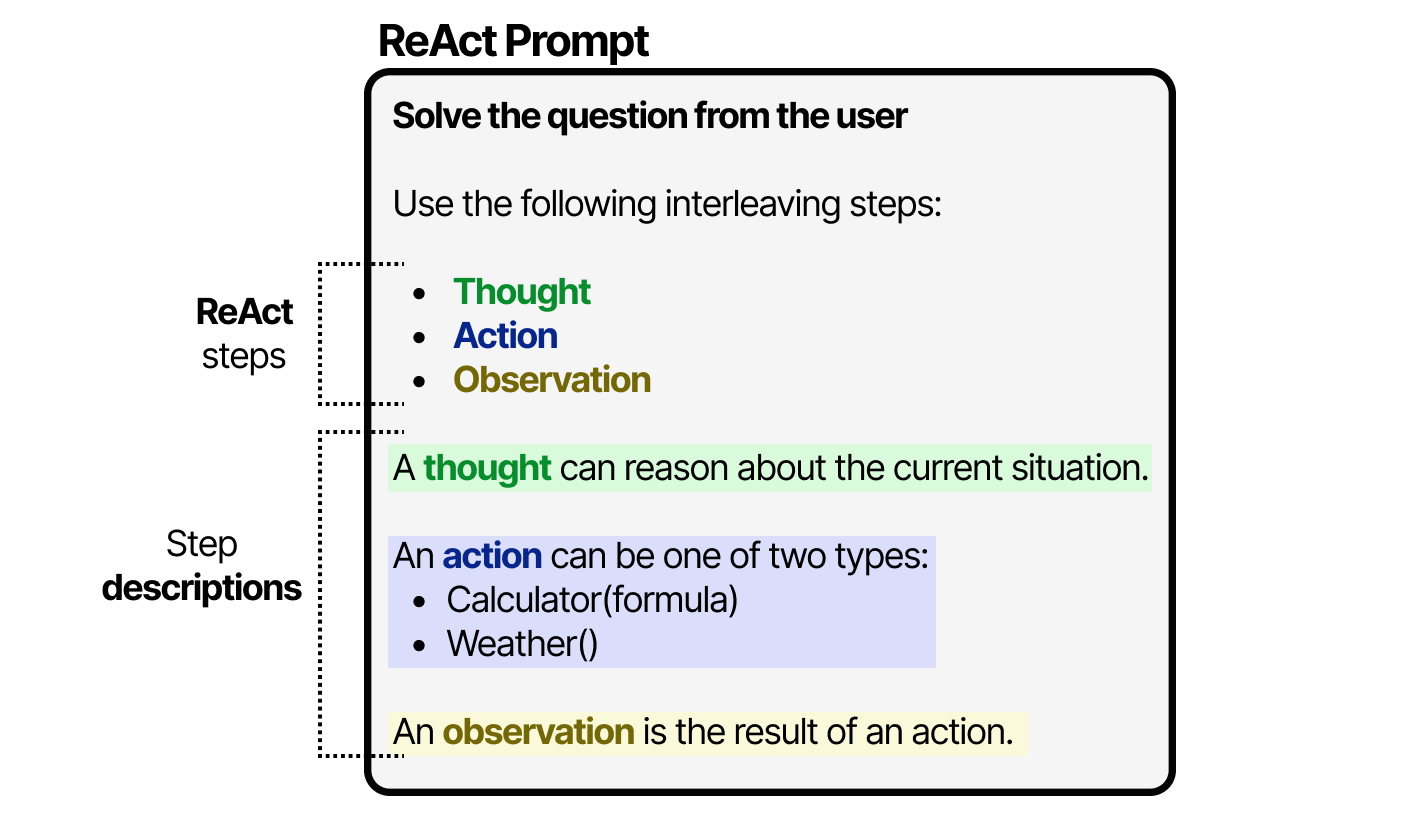
Le LLM utilise ce prompt (qui peut être utilisé comme prompt système) pour orienter ses comportements afin de travailler dans des cycles de pensées, d’actions et d’observations.
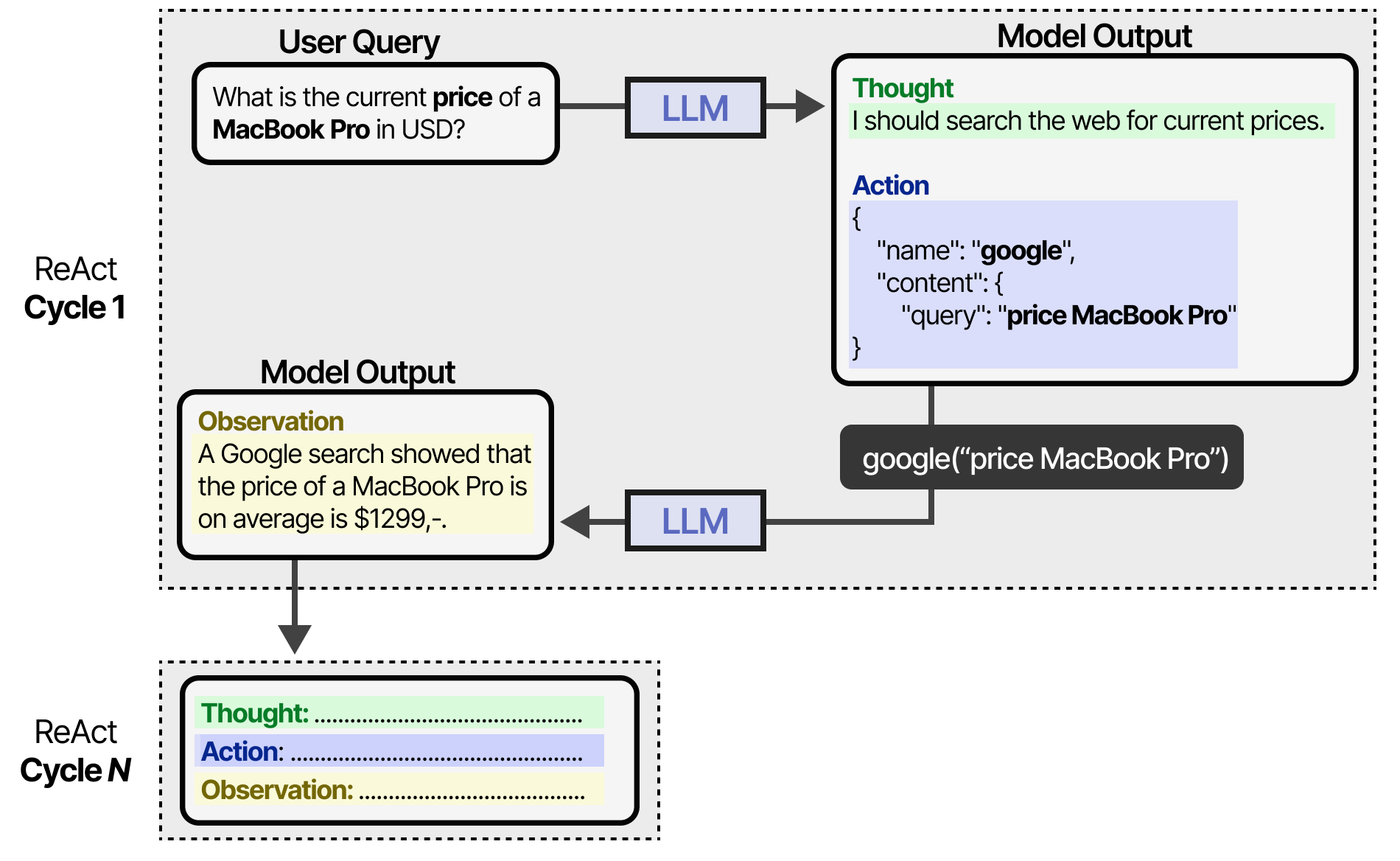
Il poursuit ce comportement jusqu’à ce qu’une action spécifie de renvoyer le résultat. En itérant sur les pensées et les observations, le LLM peut planifier des actions, observer ses sorties et s’ajuster en conséquence.
En tant que tel, ce cadre permet aux LLM de faire preuve d’un comportement d’agent plus autonome par rapport aux agents ayant des étapes prédéfinies et fixes.
Reflexion
Aucun LLM, pas même ceux utilisant ReAct, n’accomplira chaque tâche à la perfection. L’échec fait partie du processus, à condition de pouvoir y réfléchir. Ce cas est absent de ReAct et c’est là que la Réflexion (Shinn et al. (2023)) intervient. Il s’agit d’une technique qui utilise le renforcement verbal pour aider les agents à tirer des leçons de leurs échecs antérieurs. La méthode suppose trois rôles pour le LLM :
- Acteur : il choisit et exécute des actions sur la base d’observations de l’état. Nous pouvons utiliser des méthodes comme Chain-of-Thought ou ReAct.
- Évaluateur : il évalue les résultats obtenus par l’acteur.
- Auto-réflexion : réflexion sur les mesures prises par l’acteur et les scores générés par l’évaluateur.
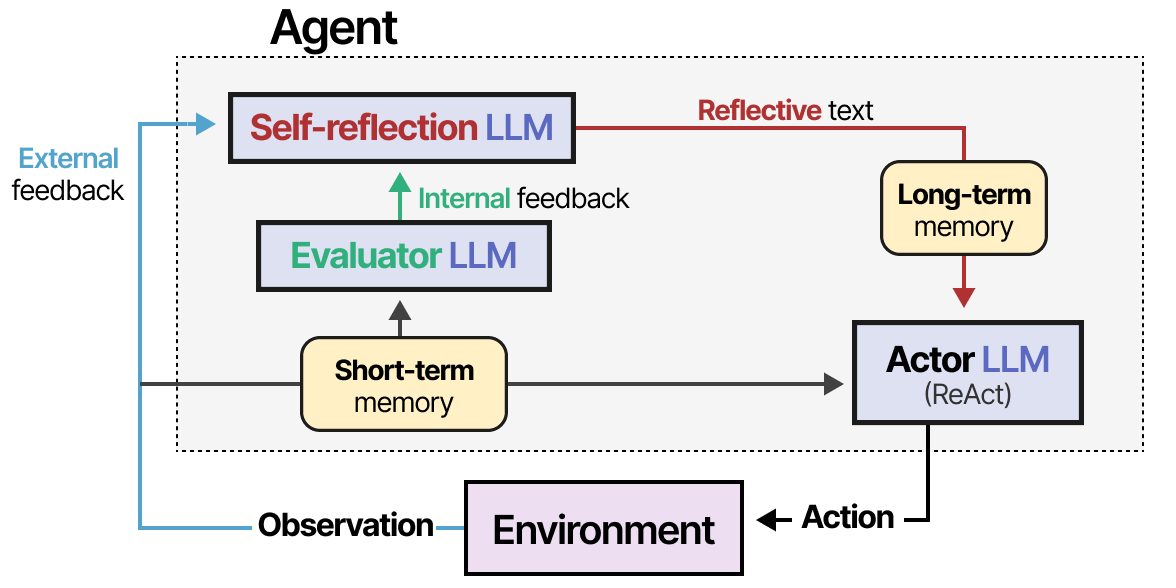
Des modules de mémoire sont ajoutés pour suivre les actions (à court terme) et les réflexions (à long terme), ce qui permet à l’agent d’apprendre de ses erreurs et d’identifier les actions à améliorer. Une technique similaire et élégante est appelée Self-Refine par Madaan et al. (2023), où les actions d’affinage des sorties et de génération de feedback sont répétées.
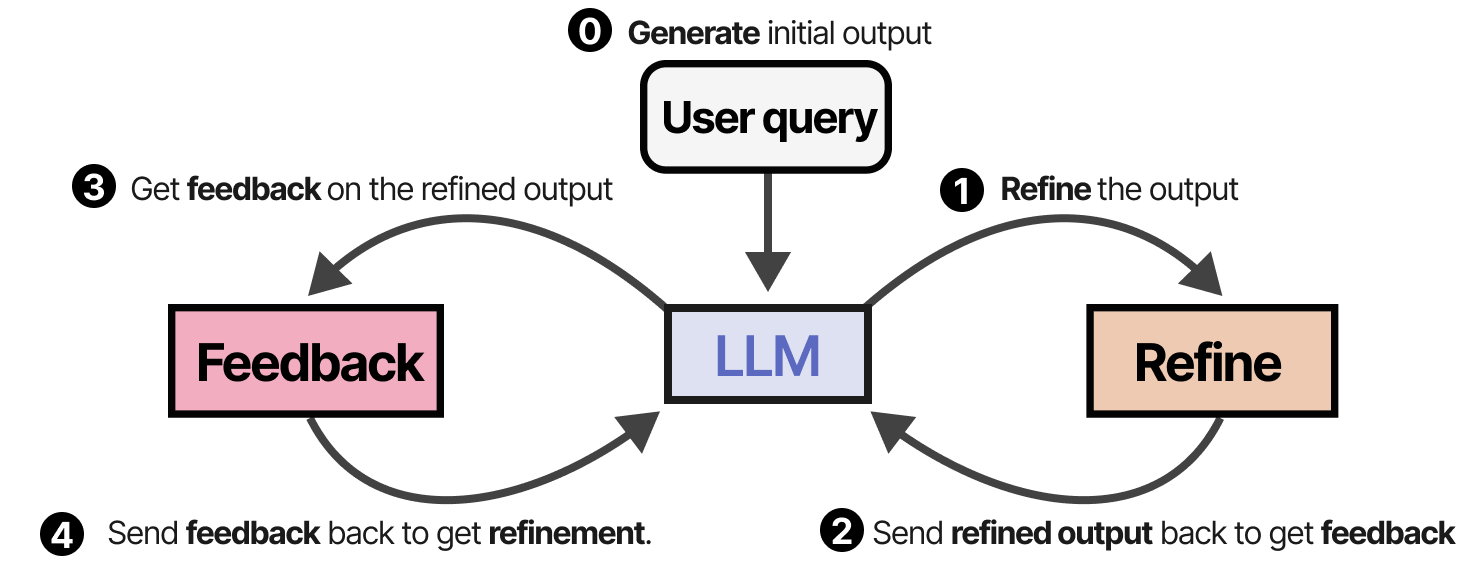
Le même LLM est chargé de générer la sortie initiale, la sortie affinée et le feedback.

Il est intéressant de noter que ce comportement d’autoréflexion, à la fois dans Reflexion et Self-Refine, ressemble beaucoup à celui de l’apprentissage par renforcement où une récompense est donnée en fonction de la qualité du résultat.
Collaboration multi-agents
L’approche avec un agent unique que nous avons exploré pose plusieurs problèmes : un trop grand nombre d’outils peut compliquer la sélection, le contexte devient trop complexe et la tâche peut nécessiter une spécialisation. Au lieu de cela, nous pouvons nous tourner vers une approche multi-agents, un cadre dans lesquels plusieurs agents (chacun ayant accès à des outils, à une mémoire et à une planification) interagissent les uns avec les autres et avec leur environnement :
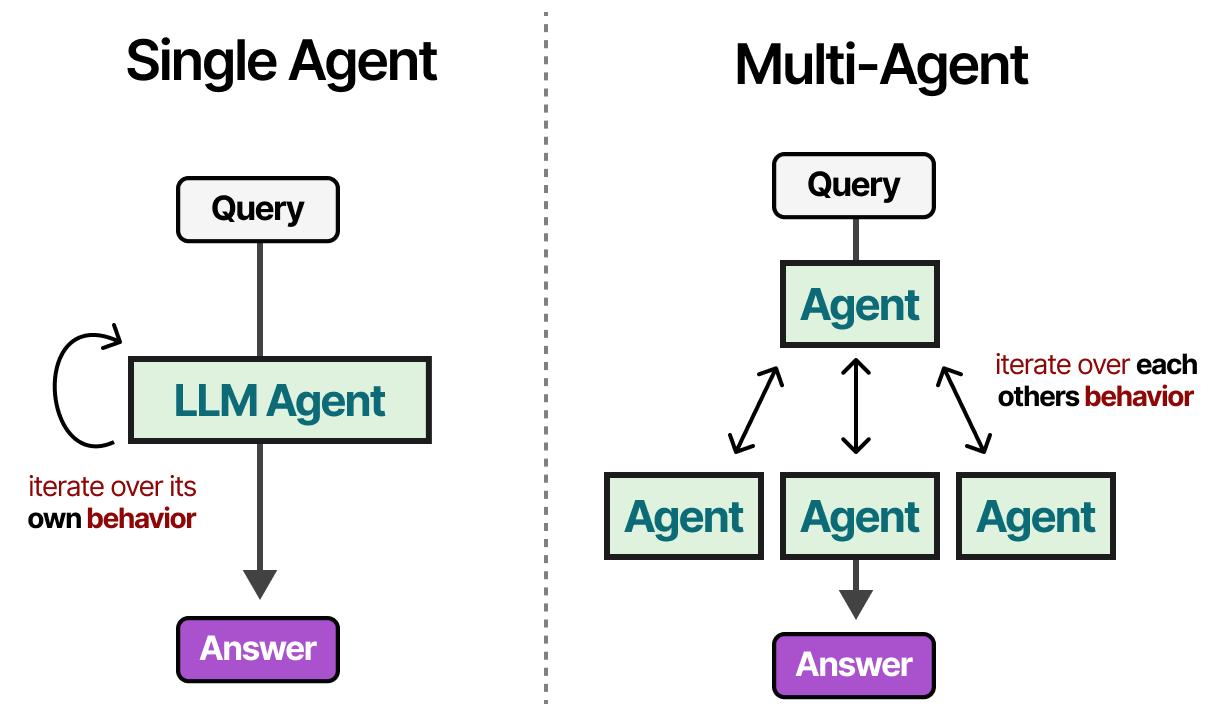
Ces systèmes multi-agents se composent généralement d’agents spécialisés, chacun équipé de son propre ensemble d’outils et dirigé par un superviseur. Le superviseur gère la communication entre les agents et peut assigner des tâches spécifiques aux agents spécialisés.
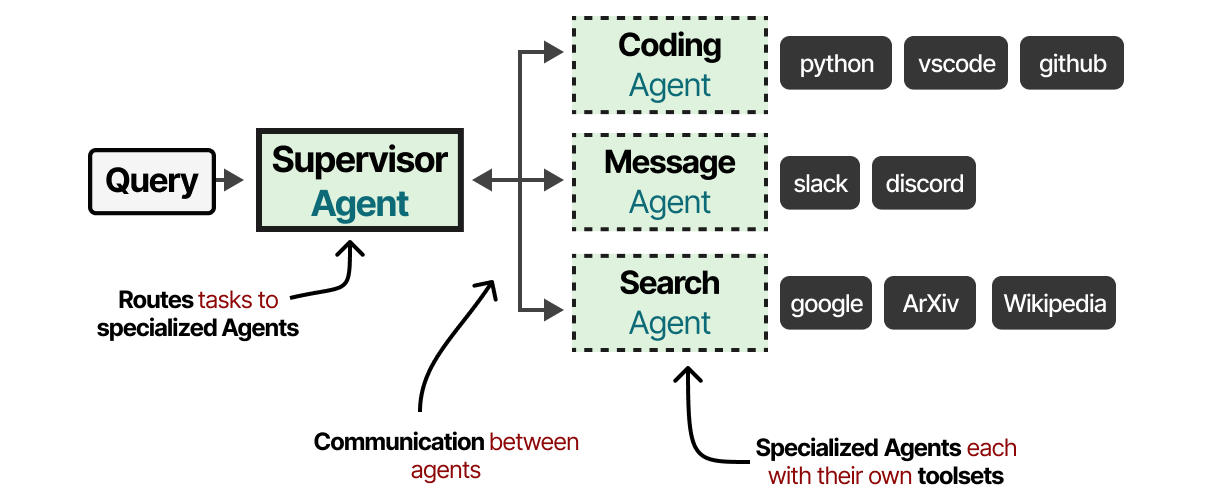
Chaque agent peut disposer de différents types d’outils, mais aussi de différents systèmes de mémoire. Dans la pratique, il existe des dizaines d’architectures multi-agents dont le cœur est constitué de deux composants :
- Initialisation des agents : comment sont créés les agents individuels (spécialisés) ?
- Orchestration des agents : comment tous les agents sont-ils coordonnés ?
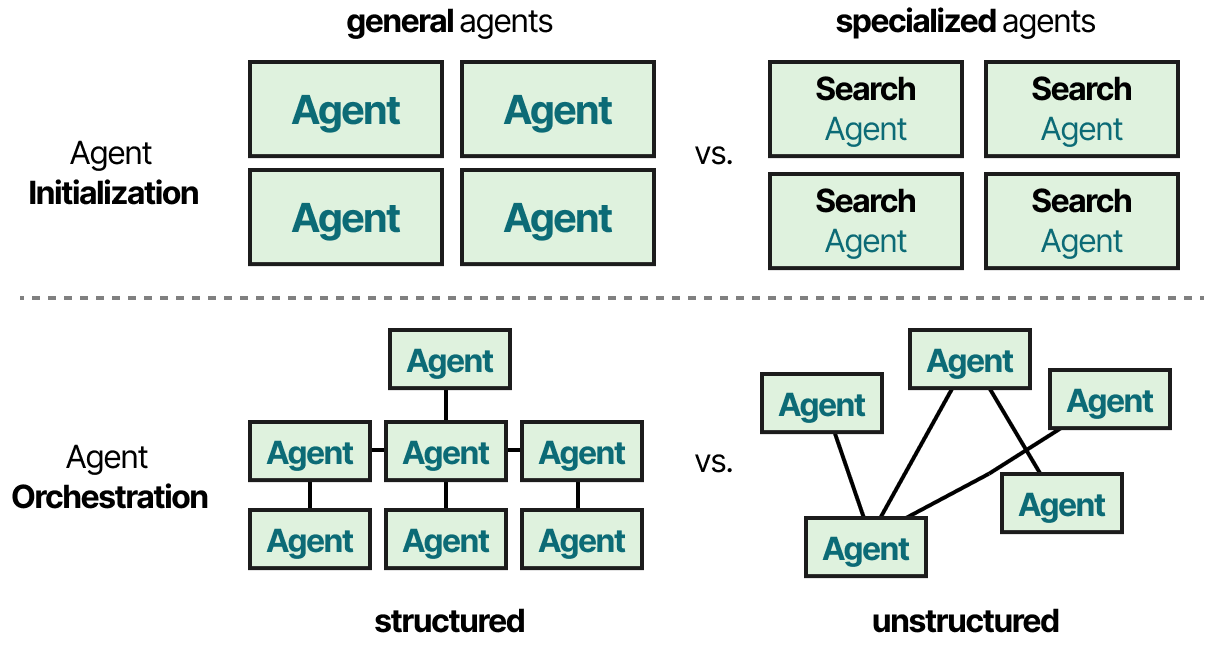
Nous allons explorer plusieurs cadres multi-agents intéressants et mettre en évidence la manière dont ces composants sont implémentés.
Simulacres interactifs du comportement humain
L’un des papiers les plus influents sur les multi-agents s’intitule Generative Agents : Simulacres interactifs du comportement humain par Park et al. (2023). Dans cet article, les auteurs ont créé des agents qui simulent un comportement humain crédible, qu’ils appellent agents génératifs.

Le profil attribué à chaque agent génératif lui permet de se comporter de manière unique et de créer un comportement plus intéressant et plus dynamique. Chaque agent est initialisé avec trois modules (mémoire, planification et réflexion) qui ressemblent beaucoup aux composants de base que nous avons vus précédemment avec ReAct et Reflexion.
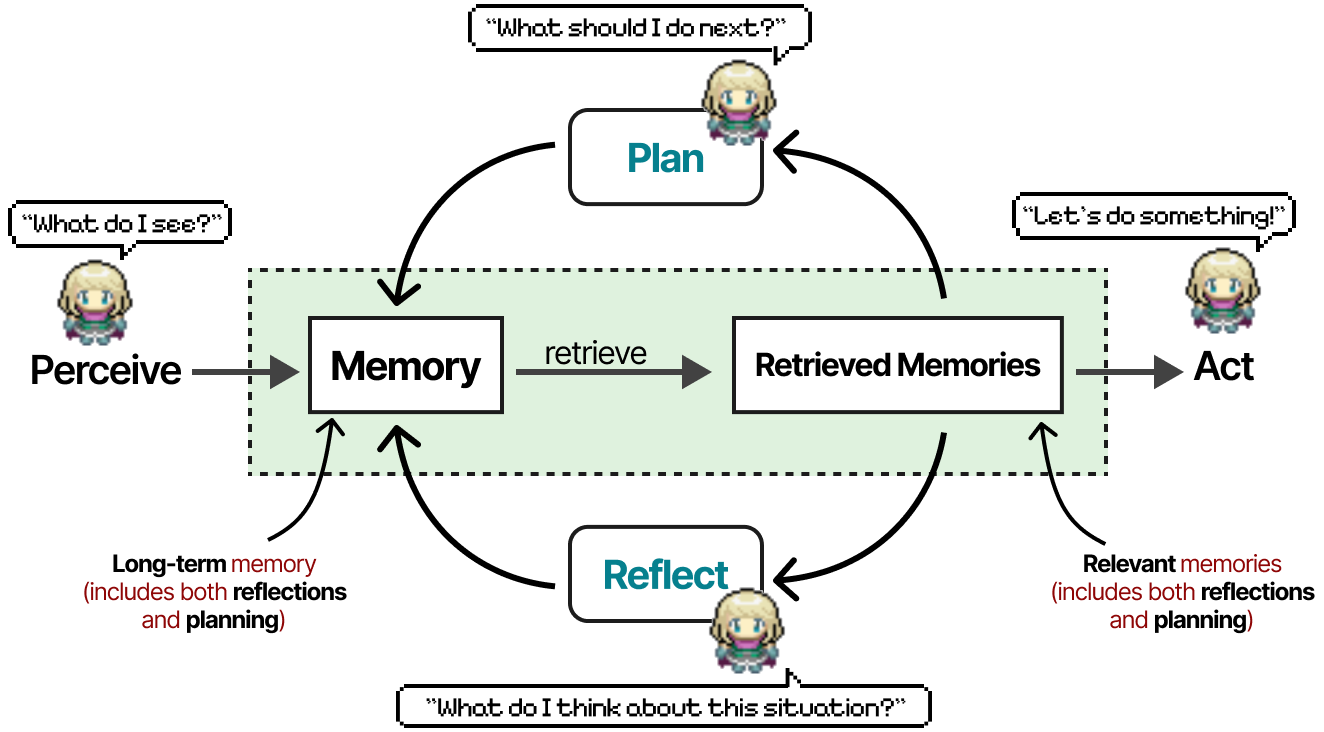
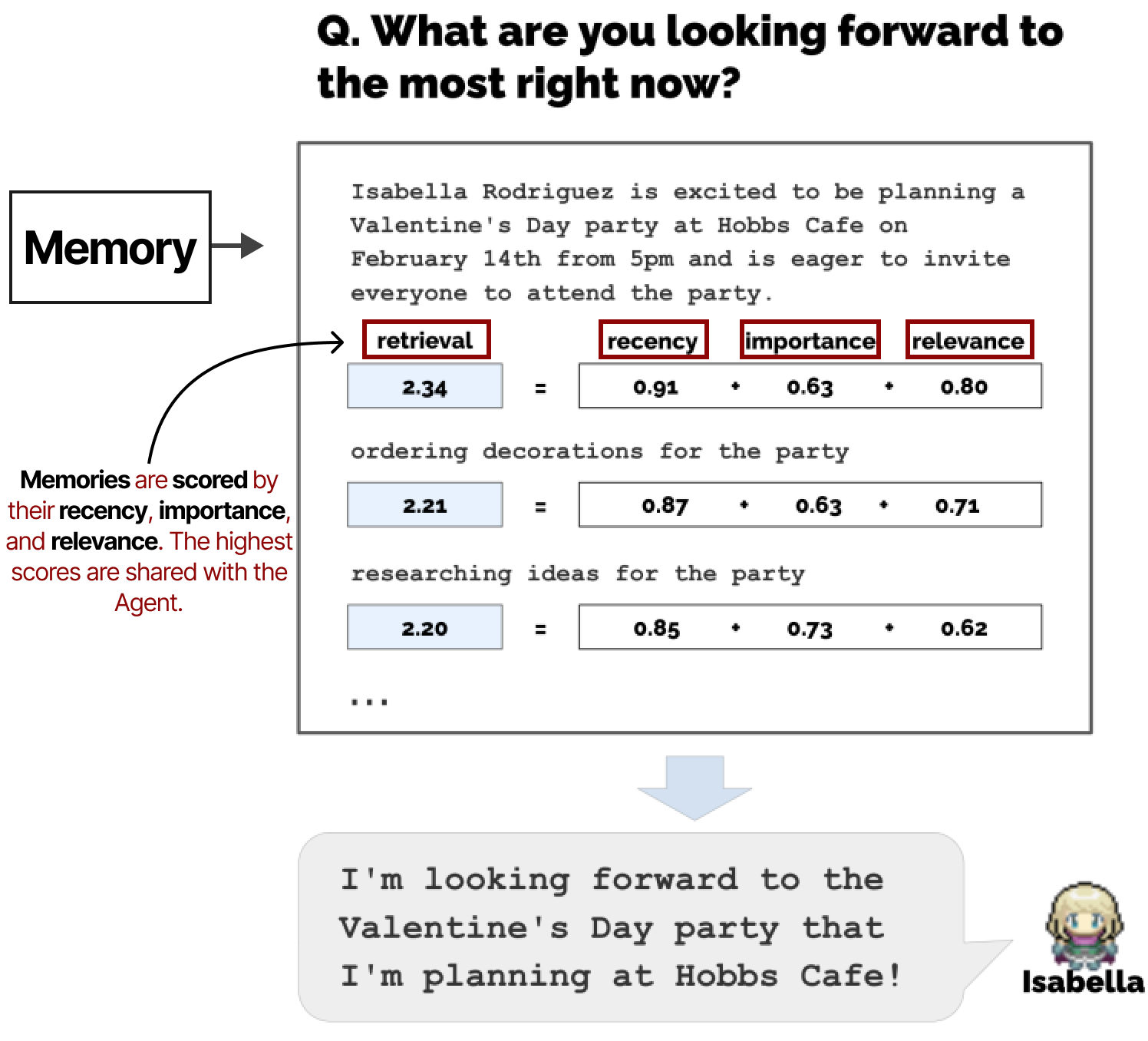
Le module de mémoire est l’un des éléments les plus importants de ce cadre. Il stocke les comportements de planification et de réflexion, ainsi que tous les événements survenus jusqu’à présent. Pour une étape ou une question donnée, les souvenirs sont retrouvés et notés en fonction de leur actualité, de leur importance et de leur pertinence. Les souvenirs les mieux notés sont communiqués à l’agent.
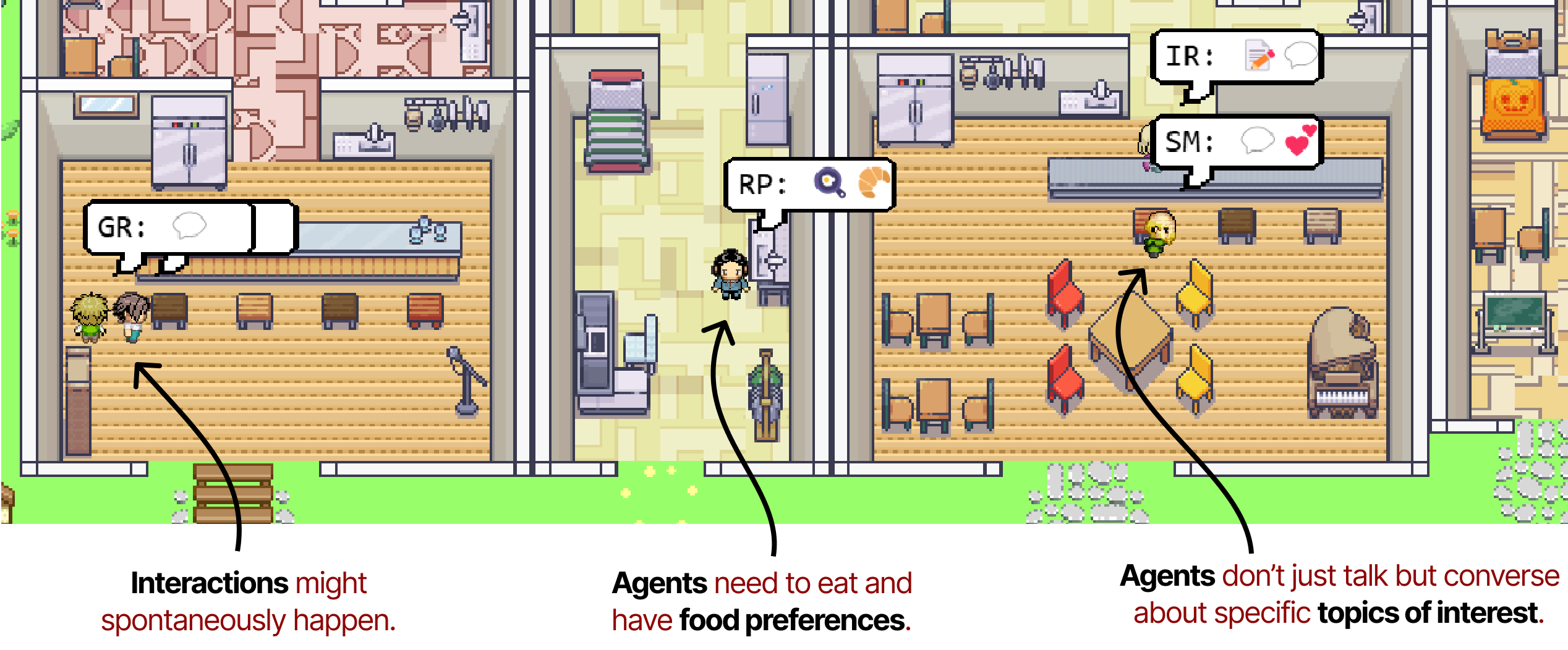
Ensemble, ils permettent aux agents de se comporter librement et d’interagir les uns avec les autres. En tant que tel, l’orchestration des agents est très limitée, car ils n’ont pas d’objectifs spécifiques à atteindre.
Il y a plusieurs éléments très intéressants dans leur papier dont nous conseillons la lecture. Détaillons un peu leur méthode d’évaluation. L’évaluation repose principalement sur la crédibilité des comportements de l’agent, qui est notée par des évaluateurs humains.
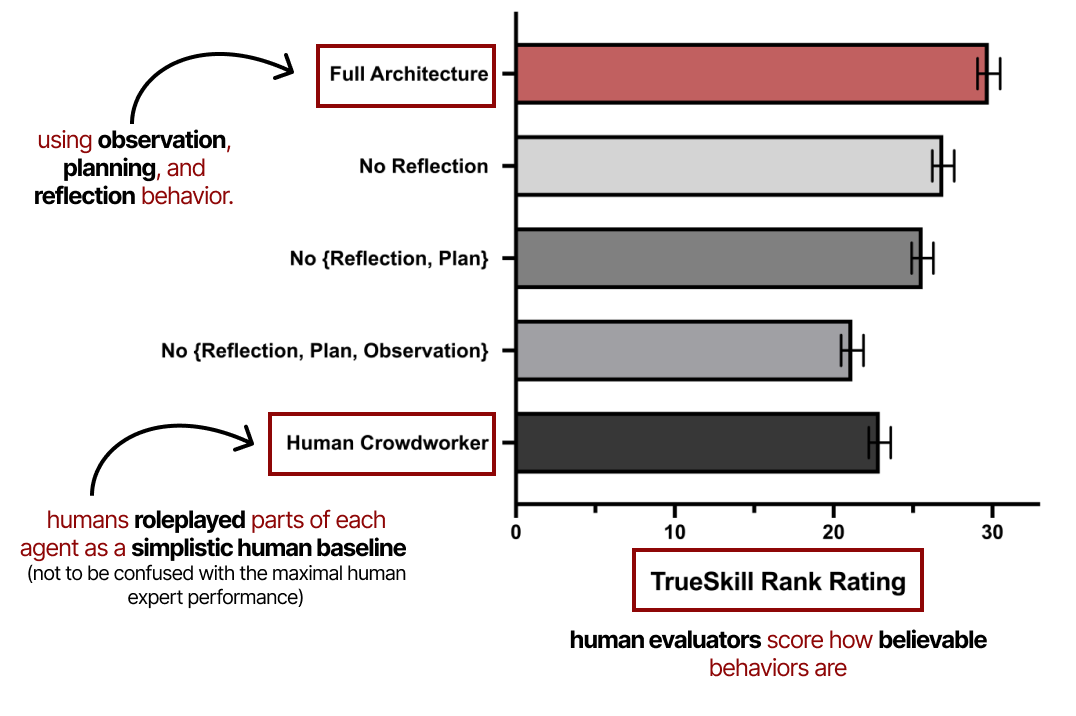
Il montre l’importance de l’observation, de la planification et de la réflexion dans les performances de ces agents génératifs. Comme nous l’avons vu précédemment, la planification n’est pas complète sans un comportement réfléchi.
Cadres modulaires
Quel que soit le cadre choisi pour créer des systèmes multi-agents, ceux-ci sont généralement composés de plusieurs ingrédients, notamment le profil, la perception de l’environnement, la mémoire, la planification et les actions disponibles (cf. cette revue de littérature de Wang, Ma, Feng et al. (2023) et celle-ci de Xi et al. (2023)).
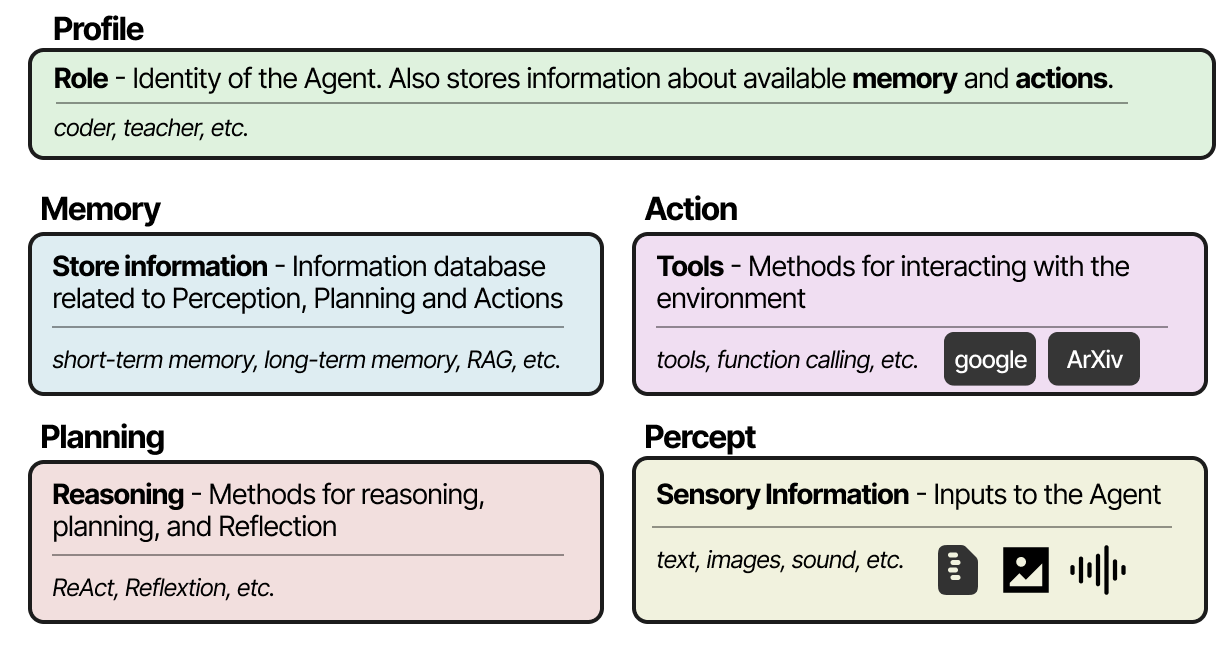
Les cadres les plus populaires pour l’implémentation de ces composants sont AutoGen de Wu et al. (2023), MetaGPT de Wang, Wang et al. (2024) et CAMEL de Li et al. (2023). Cependant, chaque cadre aborde la communication entre les agents de manière légèrement différente. Avec CAMEL, par exemple, l’utilisateur crée d’abord sa question et définit les rôles d’utilisateur et d’assistant. Le rôle d’utilisateur représente l’utilisateur humain et guidera le processus.

Ensuite, l’utilisateur et l’assistant collaborent à la résolution de la requête en interagissant l’un avec l’autre.
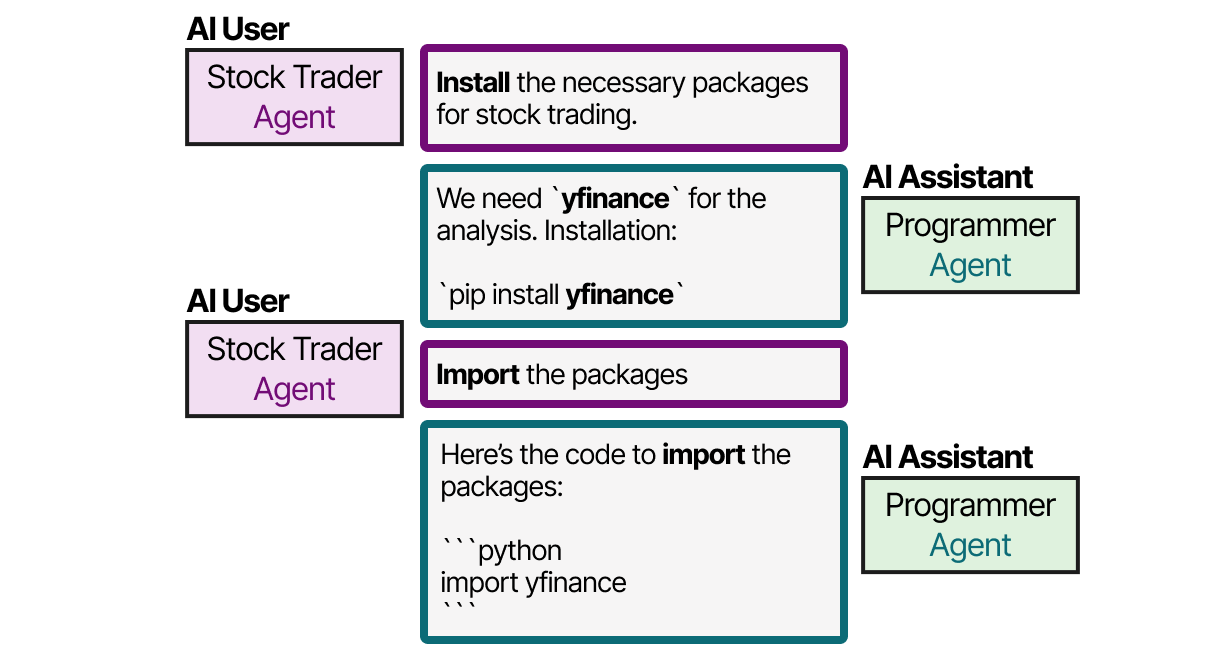
Cette méthodologie de jeu de rôle permet une communication collaborative entre les agents. AutoGen et MetaGPT ont des méthodes de communication différentes, mais tout se résume à cette nature collaborative de la communication. Les agents ont la possibilité de discuter les uns avec les autres pour mettre à jour leur statut actuel, leurs objectifs et les prochaines étapes. Au cours de l’année écoulée, et plus particulièrement ces dernières semaines, la croissance de ces approches a explosée.
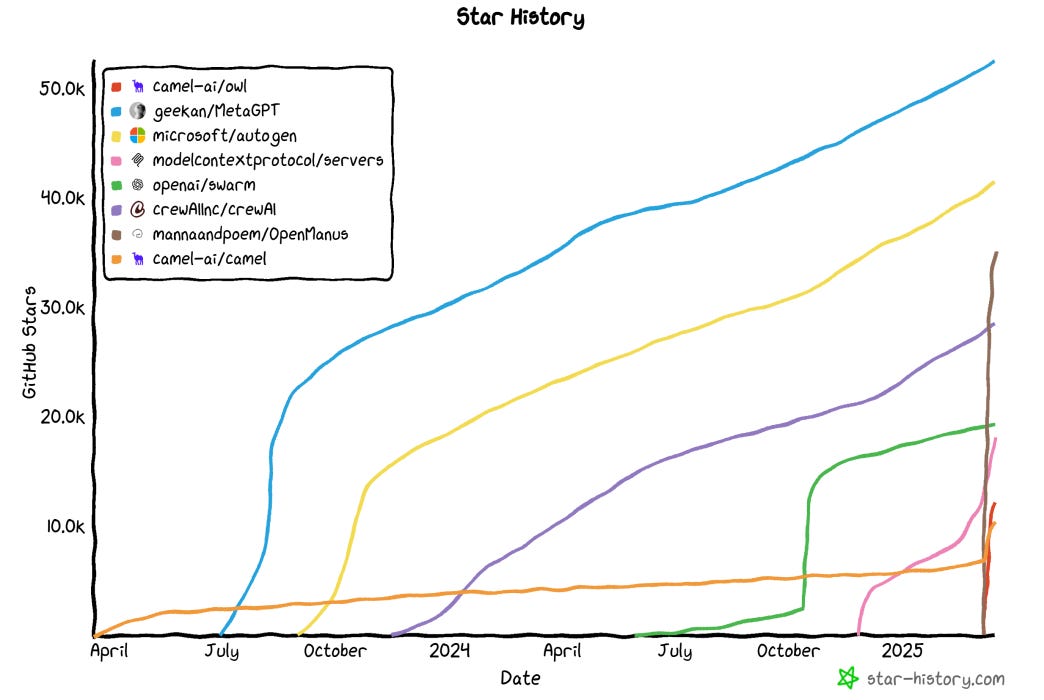
L’année 2025 pourrait donc être celle des agents qui continuent de se développer et de murir.
Conclusion
Ceci conclut notre voyage autour du thème des agents, en espérant que cela permette de mieux comprendre comment les agents LLM sont construits.
Pour une partie davantage « pratique », vous pouvez consultez le cours d’Hugging Face qui aborde notamment comment implémenter des agents avec les librairies smolagents, LlamaIndex ou encore LangGraph.
Références
- Artificial intelligence: a modern approach de Stuart RUSSELL et Peter NORVIG (2016)
- Cognitive architectures for language agents de Theodore R. SUMERS, Shunyu YAO, Karthik NARASMIMHAN et Thomas L. GRIFFITHS (2023)
- Tool Learning with Large Language Models: A Survey de Changle QU, Sunhao DAI, Xiaochi WEI, Hengyi CAI, Shuaiqiang WANG, Dawei YIN, Jun XU et Ji-Rong WEN (2024)
- Toolformer: Language Models Can Teach Themselves to Use Tools de Timo SCHICK, Jane DWIVEDI-YU, Roberto DESSÌ, Roberta RAILEANU, Maria LOMELI, Luke ZETTLEMOYER, Nicola CANCEDDA et Thomas SCIALOM (2023)
- ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs de Yujia QIN, Shihao LIANG, Yining YE, Kunlun ZHU, Lan YAN, Yaxi LU, Yankai LIN, Xin CONG, Xiangru TANG, Bill QIAN, Sihan ZHAO, Lauren HONG, Runchu TIAN, Ruobing XIE, Jie ZHOU, Mark GERSTEIN, Dahai LI, Zhiyuan LIU et Maosong SUN (2023)
- Gorilla: Large Language Model Connected with Massive APIs de Shishir G. PATIL, Tianjun ZHANG, Xin WANG et Joseph E. GONZALEZ (2023)
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models de Jason WEI, Xuezhi WANG, Dale SCHUURMANS, Maarten BOSMA, Brian ICHTER, Fei XIA, Ed CHI, Quoc LE et DENNY ZHOU (2022)
- Large Language Models are Zero-Shot Reasoners de Takeshi KOJIMA, Shixiang SHANE GU, Machel REID, Yutaka MATSUO et Yusuke IWASAWA (2022)
- ReAct: Synergizing Reasoning and Acting in Language Models de Shunyu YAO, Jeffrey ZHAO, Dian YU, Nan Du, Izhak SHAFRAN, Karthik NARASIMHAN et Yuan CAO (2022)
- Reflexion: Language Agents with Verbal Reinforcement Learning de Noah SHINN, Federico CASSANO, Edward BERMAN, Ashwin GOPINATH, Karthik NARASIMHAN et Shunyu YAO (2023)
- Self-Refine: Iterative Refinement with Self-Feedback de Aman MADAAN, Niket TANDON, Prakhar GUPTA, Skyler HALLINAN, Luyu GAO, Sarah WIEGREFFE, Uri ALON, Nouha DZIRI, Shrimai PRABHUMOYE, Yiming YANG, Shashank GUPTA, Bodhisattwa PRASAD MAJUMDER, Katherine HERMANN, Sean WELLECK, Amir YAZDANBAKHSH et Peter CLARK (2023)
- Generative Agents: Interactive Simulacra of Human Behavior de Joon Sung PARK, Joseph C. O’BRIEN, Carrie J. Cai, Meredith RINGEL MORRIS, Percy LIANG et Michael S. BERNSTEIN (2023)
- A Survey on Large Language Model based Autonomous Agents de Lei WANG, Chen MA, Xueyang FENG, Zeyu ZHANG, Hao YANG, Jingsen ZHANG, Zhiyuan CHEN, Jiakai TANG, Xu CHEN, Yankai LIN, Wayne XIN ZHAO, Zhewei WEI et Ji-Rong WEN (2023)
- The Rise and Potential of Large Language Model Based Agents: A Survey de Zhiheng XI, Wenxiang CHEN, Xin GUO, Wei HE, Yiwen DING, Boyang HONG, Ming ZHANG, Junzhe WANG, Senjie JIN, Enyu ZHOU et al. (2023)
- AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation de Qingyun WU, Gagan BANSAL, Jieyu ZHANG, Yiran WU, Beibin LI, Erkang ZHU, Li JIANG, Xiaoyun ZHANG, Shaokun ZHANG, Jiale LIU, Ahmed Hassan AWADALLAH, Ryen W WHITE, Doug BURGER et Chi WANG (2023)
- MegaAgent: A Large-Scale Autonomous LLM-based Multi-Agent System Without Predefined SOPs de Qian WANG, Tianyu WANG, Zhenheng TANG, Qinbin LI, Nuo CHEN, Jingsheng LIANG et Bingsheng HE (2024)
- CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society de Guohao LI, Hasan Abed AL KADER HAMMOUD, Hani ITANI, Dmitrii KHIZBULLIN et Bernard GHANEM (2023)
Citation
@inproceedings{Agent_blog_post,
author = {Loïck BOURDOIS},
title = {Un guide visuel sur les agents},
year = {2025},
url = {https://lbourdois.github.io/blog/LLM_Agents/}
}